










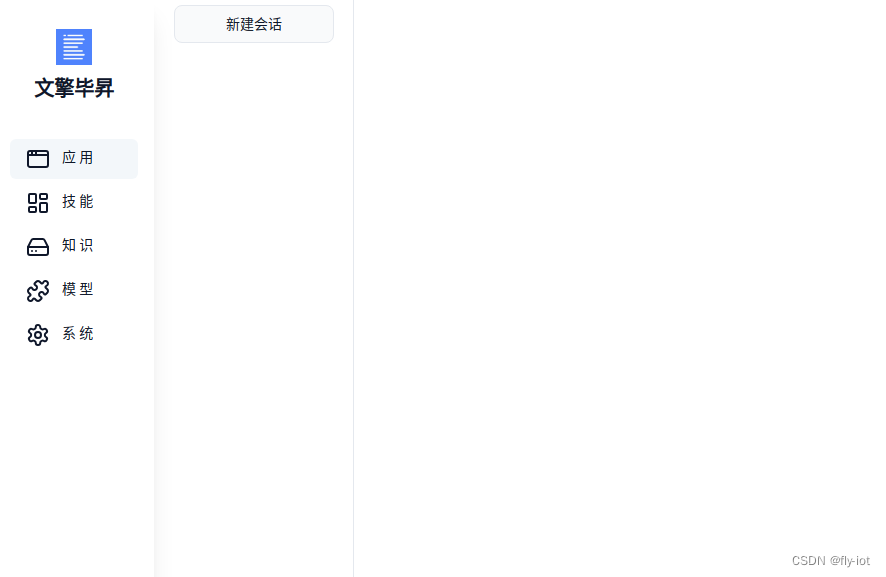
1,关于bisheng 项目
https://www.bilibili.com/video/BV1xi4y1e7MD/
【大模型知识库】(2):开源大模型+知识库方案,docker-compose部署本地知识库和大模型,毕昇+fastchat的ChatGLM3,BGE-zh模型
2,关于bisheng 项目
Bisheng是一款领先的开源大模型应用开发平台,赋能和加速大模型应用开发落地,帮助用户以最佳体验进入下一代应用开发模式。
“毕昇”是活字印刷术的发明人,活字印刷术为人类知识的传递起到了巨大的推动作用。我们希望“毕昇”同样能够为智能应用的广泛落地提供有力的支撑。欢迎大家一道参与。
Bisheng 基于 Apache 2.0 License 协议发布,于 2023 年 8 月底正式开源。
产品亮点
便捷:即使是业务人员,基于我们预置的应用模板,通过简单直观的表单填写方式快速搭建以大模型为核心的智能应用。
灵活:对大模型技术有了解的人员,我们紧跟最前沿大模型技术生态提供数百种开发组件,基于可视化且自由的流程编排能力,可开发出任意类型的大模型应用,而不仅是简单的提示词工程。
可靠与企业级:当前许多同类的开源项目仅适用于实验测试场景,缺少真正生产使用的企业级特性,包括:高并发下的高可用、应用运营及效果持续迭代优化、贴合真实业务场景的实用功能等,这些都是毕昇平台的差异化能力;另外,更直观的是,企业内的数据质量参差不齐,想要真正把所有数据利用起来,首先需要有完备的非结构化数据治理能力,而这是过去几年我们团队所积累的核心能力,在毕昇的demo环境中您可以通过相关组件直接接入这些能力,并且这些能力免费不限量使用。
产品应用
使用毕昇平台,我们可以搭建各类丰富的大模型应用:
分析报告生成
知识库问答
对话
要素提取
我们认为在企业真实场景中,“对话”仅是众多交互形式中的一种,未来我们还将新增流程自动化、搜索等更多应用形态的支持。
https://dataelem.feishu.cn/wiki/BSCcwKd4Yiot3IkOEC8cxGW7nPc
3,下载项目
git clone https://github.com/dataelement/bisheng
cd bisheng/docker
docker-compose up -d
或者使用我的镜像部署带 fastchat 版本的:
git clone https://gitee.com/fly-llm/bisheng-docker-compose

启动成功:

帐号:admin
密码:1234
如果要是出现这个错误:

需要重启下后端服务,没有连接上数据库造成的。
docker restart backend
然后就可以使用了:
3,然后启动chatglm3大模型
参考之前的文章:
https://blog.csdn.net/freewebsys/article/details/134631859
启动之后就可以进行配置了:
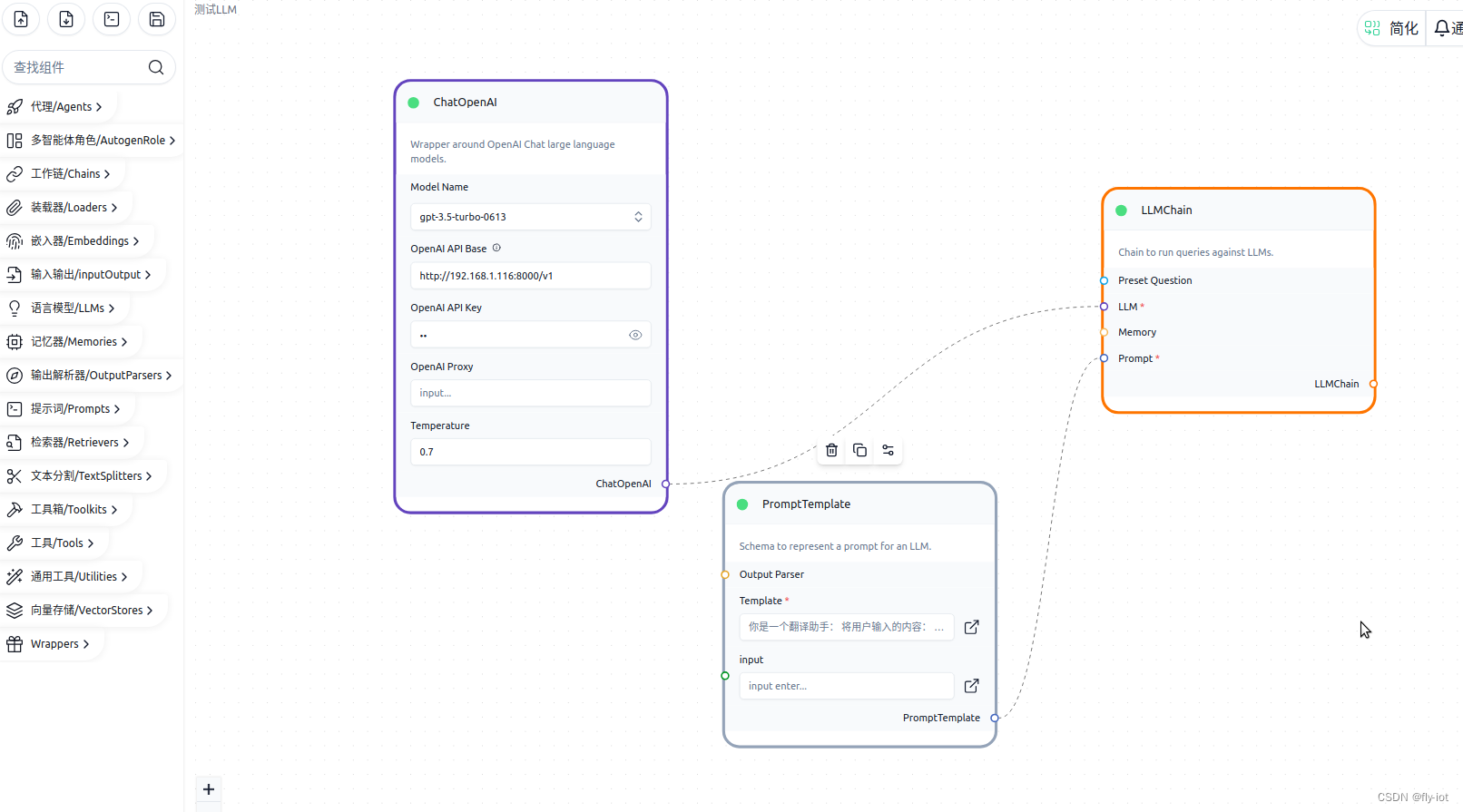
配置一个prompt :
你是一个翻译助手:
将用户输入的内容:
{input}
翻译成英文。
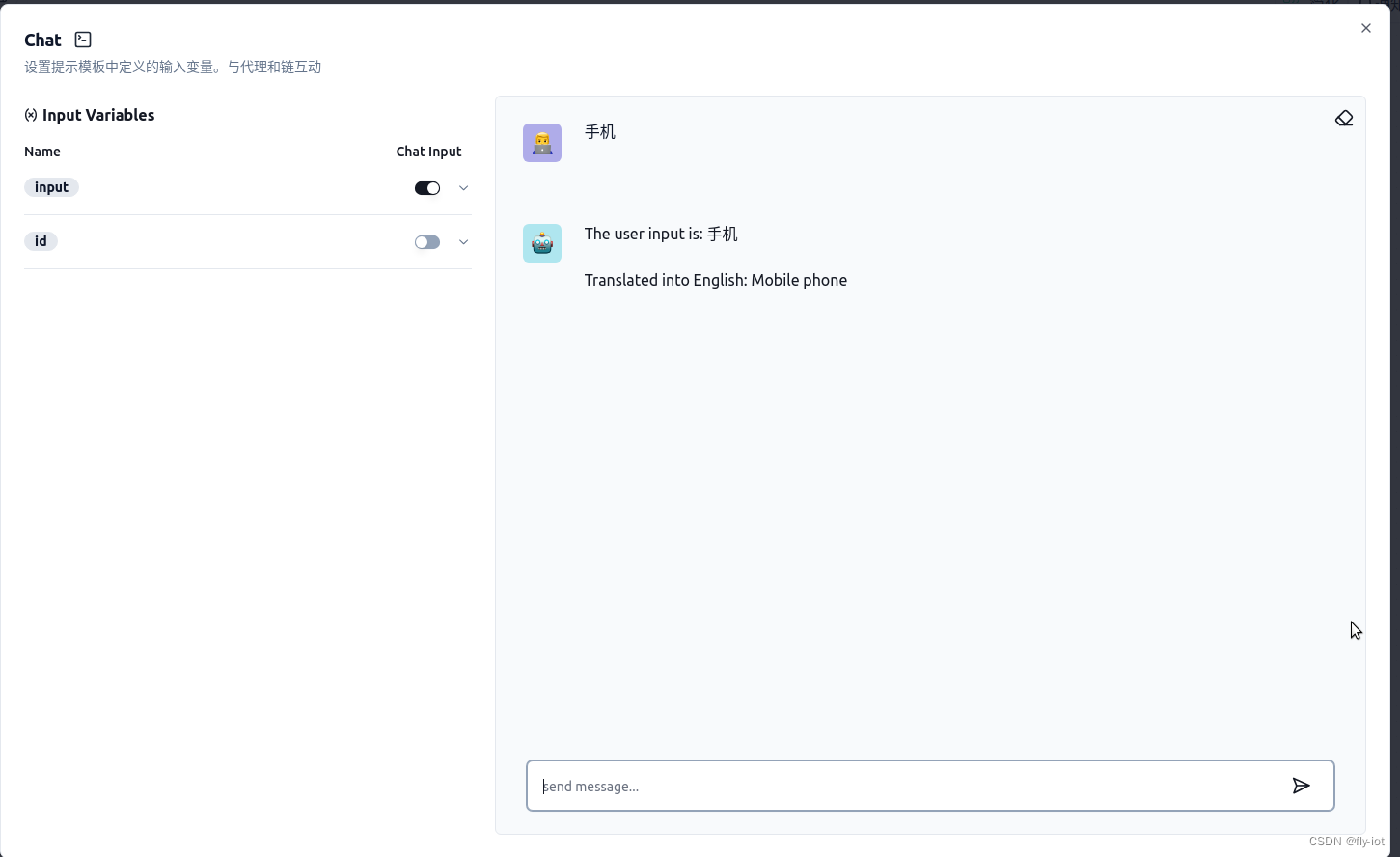
然后点击右下角编译,然后聊天:
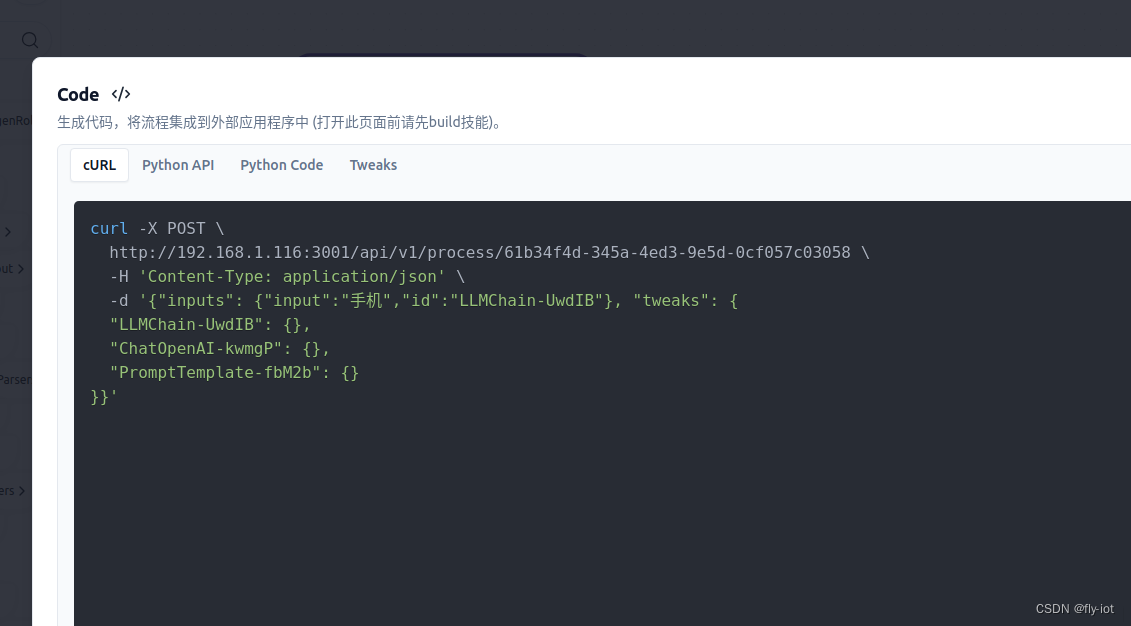
还可以配置好 API 接口:
4,总结
通过拖拽的方式可以实现模型的配置编程,可以快速的开发应用。
或者提供对外接口,非常的方便。
这个只是演示了配置chatglm3 接口的部分。
持续研究中。

















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









