






如果说VAE(【深度视觉】第十三章:生成网络1——PixelRNN/CNN、VAE-CSDN博客)太难理解,那本篇的GAN就轻松很多,没有什么晦涩的数学推导,就是一个简单的深度学习架构,但其思路很简单、也很巧妙。。。。
(三)GAN 生成对抗网络
生成对抗网络GAN是由Lan J.Goodfellow及其团队提出的,原始论文是《生成对抗网》,goodfellow本人就是 花书 的作者。
1、GAN的基本原理:两个子网络的对抗思想
假设现在存在一组从真实场景中收集的真实数据realdata,但是这些真实数据的样本量太少,我们就可以借助 GANs,用这些真实数据生成一组假数据fakedata,而且这组假数据最好是可以以假乱真的。这样这组假数据就可以替代真实数据或者是加入真实数据,就可以用来训练网络了。而有时候这组假数据就是我们想要获得的数据,比如AI生成人脸技术、比如看到20年后的自己或者20年前的自己等任务。总之,生成对抗网络的最终目标就是输出一组足以以假乱真的假数据。
一个生成对抗网络包含两个基础网络:一个是生成器generator,简称G,也称为生成网络;另一个是判别器 discriminator,简称D,也称为判别网络。其中,生成器用于生成假数据,判别器用于判断数据是真是假。
GANs网络在训练过程中,生成器的目标是尽量生成足够真的假数据,让判别器判断不出真伪,所以生成器是向生成图像越来越真的方向迭代,生成器没有标签,是无监督网络;判别器的目标是让自己的判断准确性越来越高,尽量判别出真伪,所以判别器的迭代方向是向越来越强的判别方向迭代,判别器是有标签的,是有监督网络,其标签是真与假(0或1),也就是判别器输出的是一类标签下的概率,就是当判别器输出大于0.5(当然这个阈值你可以自己定),就是认为是标签1的概率,也就是认为图片是真的概率,当判别器的概率小于0.5,就说明判别器认为生成器生成的是假数据。
当两个子网络都逐渐迭代到,生成器生成的图片真假难辨,判别器的判别结果越接近0.5时,就停止训练。 其中,生成器可以是基于已有的真实数据来生成新数据,也可以是基于噪音、甚至是随机数来生成新数据。所以GANs是使用有监督方法实现无监督输出的模型。
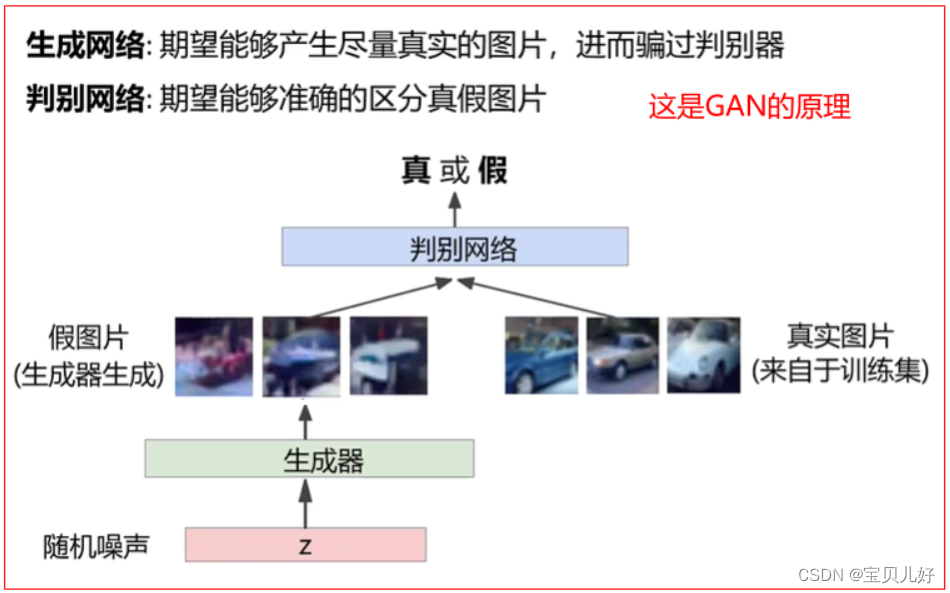
这就是GAN的最基本的思想,就是一种博弈的思维。
2、GAN的基本架构
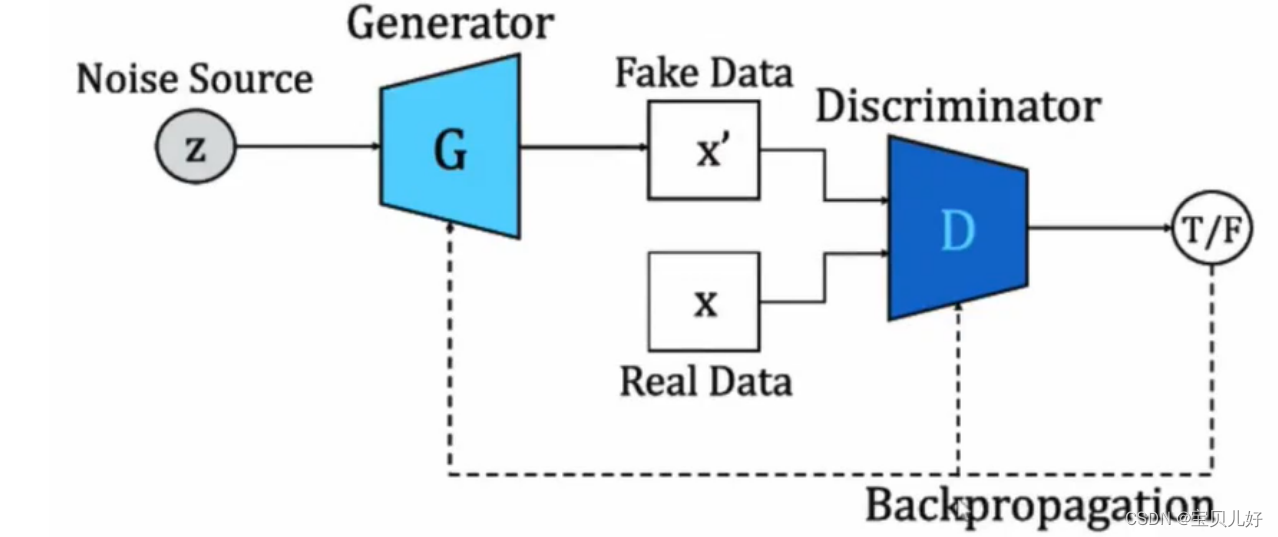
上图就是一个GAN架构:从整体来看,GAN其实就是两个子网络,一个是生成器,一个是判别器。生成器用来生成图片,判别器用来判别图片。当我们只有少量样本的时候,我们用随机数让生成器给我们生成一些fake data, 然后把fake data 和我们少量的真样本数据real data一起喂入判别器,当然此时fake data 的标签就是0(假),real data的标签就是1(真),此时判别器就是一个二分类判别器。
当我们把这个网络训练完毕后:就是训练到生成器生成的图片我们自己人类都觉得肉眼看起来很像真实的图片,并且判别器也把fake data和real data都判断得接近0.5附近,也就是说判别器也判断不准的时候,我们就算是把GAN网络训练成功了。此时我们可以丢掉判别器,让生成器给我们生成以假乱真的假数据了。这也就是为什么说GAN是一个生成模型的原因。
3、GAN背后的数学
要实现GAN的对抗思想,用数学语言来描述,就是一个最小-最大化的问题:

4、GAN的损失函数和训练方式
GAN的难点在于损失函数和训练上。你搭建两个子网络,你想让它俩对抗,他俩就对抗啦?非也,你得设置巧妙的损失函数+有策略的训练方法,才能在损失函数的牵引下,两个子网络才产生对抗,而且是要往生成器生成的图像更真、判别器判别能力更强的方向对抗!也就是这样才能实现1中原理部分讲的网络迭代的方向!不然你是训练不成一个效果很好的GAN的!
比如,如果你的损失函数仅仅是判别器的判别损失,那就是二分类交叉熵损失,这么一个损失函数时,那生成器就不往越真的方向迭代了啊,此时生成器越摆烂越好,判别器也可以轻松把真判为真、把假判为假,此时损失是垮垮往下降的啊。那此时你的损失函数就没有牵引着两个子网络走向对抗啊!生成器摆烂了,判别器瞎猜都能降低损失啊,此时就不是我们想要的,也达不到对抗的目的,更生成不了我们想要以假乱真的结果了。
从GAN的目标函数看,要先最大化再最小化目标函数,那在网络训练过程中就要采取交替训练的策略来实现:

可见,在GAN的训练过程中是分步训练的,先训练判别器,再训练生成器,然后再训练判别器,再训练生成器,如此反复多轮。。。。
也可见,对于GAN,生成器有生成器自己的损失函数、判别器有判别器自己的损失函数。
(1)判别器的损失函数
在训练判别器时,目标函数就是判别器对真样本和假样本判别损失,就是判别器把真样本判为假,把假样本判为真的损失。其实就是一个二分类,真样本的标签是1,假样本的标签是0,就是一个二分类的交叉熵损失。

意思就是判别器的损失是:真、假数据分开计算损失的。加号前面的损失是真数据的损失,加号后面的损失是假数据的损失。
当一条样本的标签是1时,就是说这条样本是真实数据,那判别器把这条样本越往接近1的方向判断,log(DXi) 就越接近0,损失就越小。当一条样本的标签是0时,就是说这条样本是生成器生成的数据,那判别器把这条样本越往接近0的方向判断,log(1-DGzi)就越接近0,损失就越小。
(2)生成器的损失函数
在训练生成器时,目标函数就是上上图的B,但是从上上图右下角的小图上看,B是绿色的线:当损失很小的时候,就是越接近0的地方,B的斜率却最大的;当损失较大的时候,比如越接近1的地方,B的斜率却较小,因此此时的B更平缓嘛。这会造成了一个什么麻烦呢?就是当网络训练得很好的时候,也就是损失很小的时候,损失函数的梯度却非常大,导致网络迭代出现大起大落得波动;当网络还没有充分训练的时候,损失函数的梯度却非常小,导致网络参数迟迟不能快速迭代,老是小步慢移,训练效率低下。
我们都知道在训练初期应该大步迭代,越往后越要小步慢走,而B却正好相反。 所以我们把B给等价成了C,C是上图得蓝色曲线,所以我们最小化B就变成了最大化C。实际在训练过程中,人们也总结出经验就是用C作为目标函数来优化生成器。
也就是,我们要求生成器能生成让判别器都给它判为1的样本。所以当数据从生成器中正向传播一次后,生成器的损失函数是:这些数据被判别器判为了0。就是判别器越往0处判断,生成器的损失值就越大,说明生成器很弱,判别器很强,生成器生成的数据都被判别器判为假了。
这里我们小结一下:
一是,我们在训练GAN的时候,是有判别器损失和生成器损失,两个损失函数的,其中,判别器损失又是由两部分组成的(真数据的损失+假数据的损失)。
二是,有两个损失函数就得有两个优化器,就得逐个训练。一般我们训练的时候是先训练一下判别器,再训练生成器,再训练判别器,再训练生成器,这样不断往复往。。。。而在训练判别器的过程中,是只迭代判别器的参数,而不迭代生成器参数的。在训练生成器时,只迭代生成器的参数而不迭代判别器的参数。
5、GAN家族介绍
GAN的底色是对抗思想,但要践行对抗,你必须要有巧妙地目标函数和训练方法的,所以GAN最大的难点就是训练。也所以,科研人员在GAN的架构、目标函数、优化方法上进行了艰苦卓绝的探索,来克服训练难的问题,就形成了现在的GAN一族。下面我们简单梳理几个比较有名的:
从架构上看,如果你是用FC来搭建的判别器和生成器,那就是普通的GAN,如果你是用transposed conv2d来搭建的,那就是DCGAN了。
从损失函数的改进来看,GAN又进化有LSGAN(Least Square GAN) 和 WGAN(Wasserstein GAN)。
从输入是否是随机数z,还是给网络输入一些其他辅助信息看,GAN又有CGAN 和 infoGAN。
由于内容太多,本部分只将普通的GAN和DCGAN。其他的架构再开辟一章节单独写。
6、从数据到架构到训练,写一个完整的普通GAN
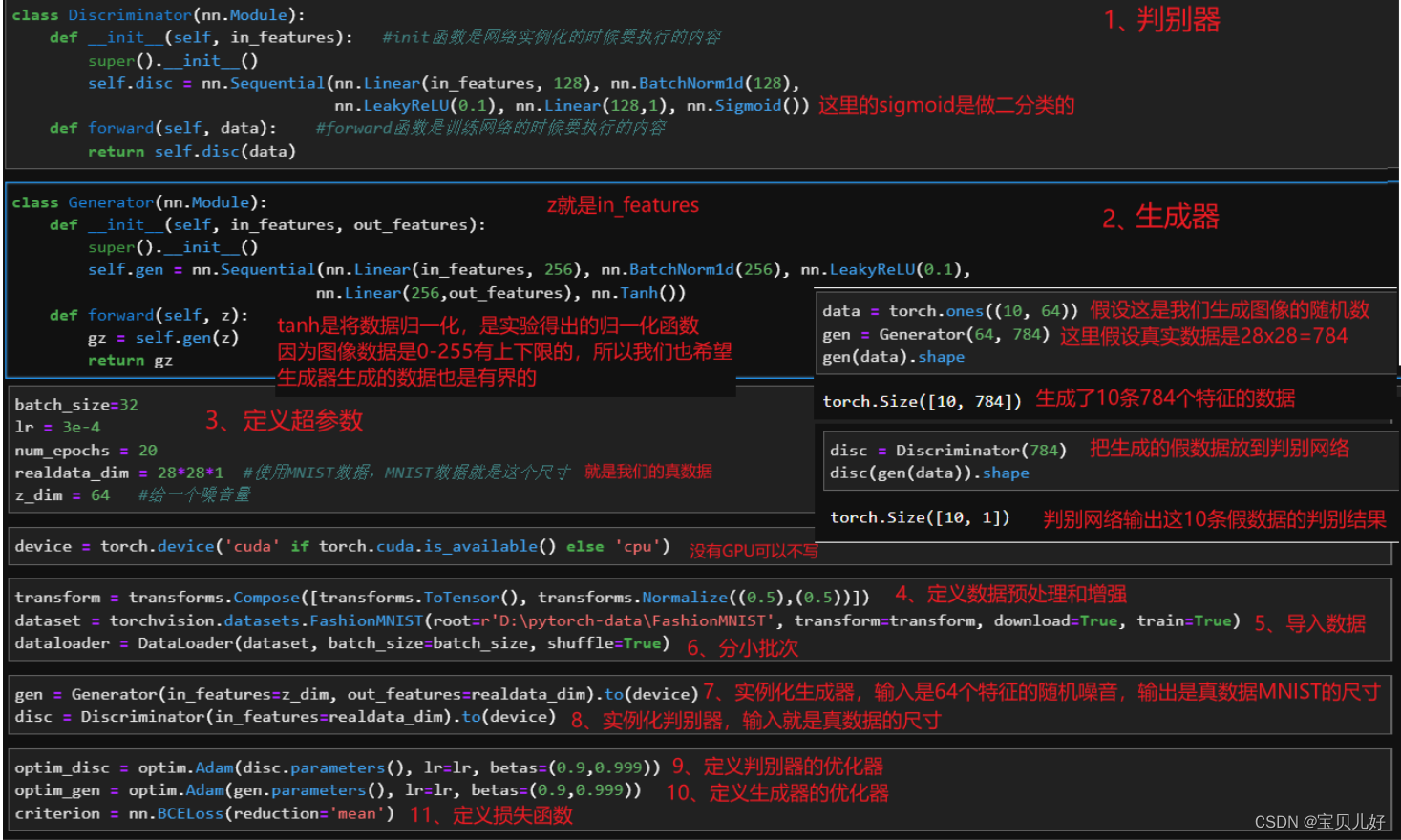
说明:
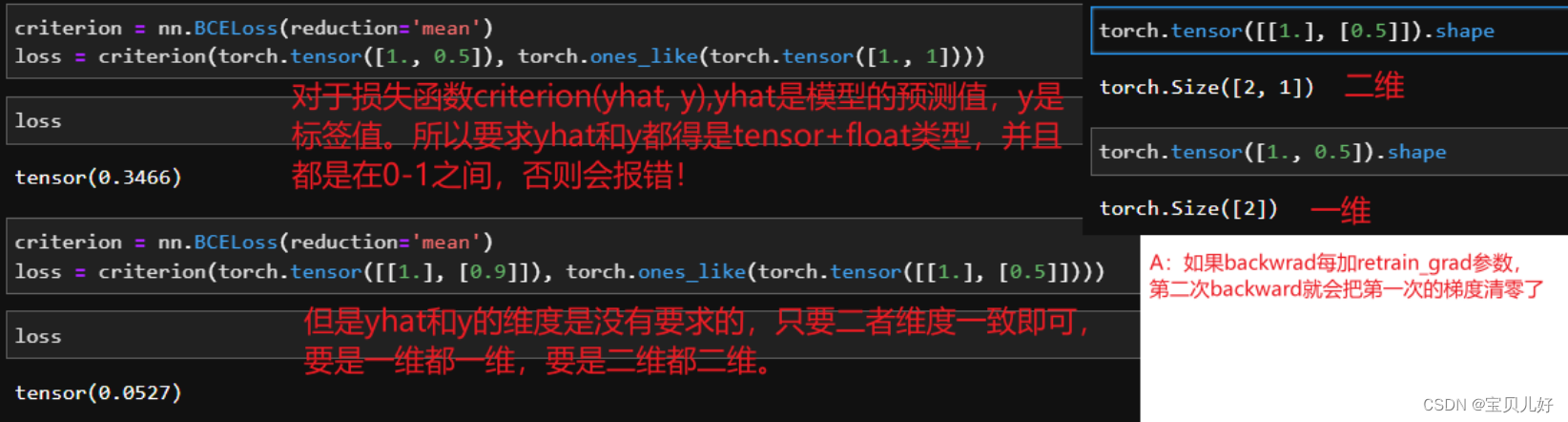
(1)数据做增强时用的归一化可以写成transforms.Normalize((0.1307), (0.3081))这一组归一化数据,因为这组数据是FashionMNIST数据集自己的均值和方差。当然你也可以用0.5-0.5,因为这组数据的最大特点或者说最大好处是,数据可以从0-1之间(图像数据经过totensor后就被归一化到0-1之间了)归一化到-1到1之间,比较符合数据有界性的良好品质。而我们的生成器最后一层是tanh激活函数,也是将数据转化到-1-1之间的。这样我们的真假数据就都是-1-1之间了。
(2)我们的判别器是一个二分类判别器,而且判别器网络的最后一层是sigmoid输出,输出就是一个类概率值了,所以损失函数用nn.BCELoss()即可。如果你的判别器网络的最后一层只是一分类的输出,就是输出的是yhat,还没有转化为类概率值,那你就得用 nn.BCEWithLogitsLoss()了。 在我们之前学得多分类网络中,比如残差网络,googlenet等,最后的输出层都是yhat,不是经过softmax处理的类概率。此时的多分类网络,我们就得用多分类交叉熵损失函数: criterion=nn.CrossEntropyLoss(reduction='sum'),然后criterion(yhat, y)。
(3)其他相关知识点:
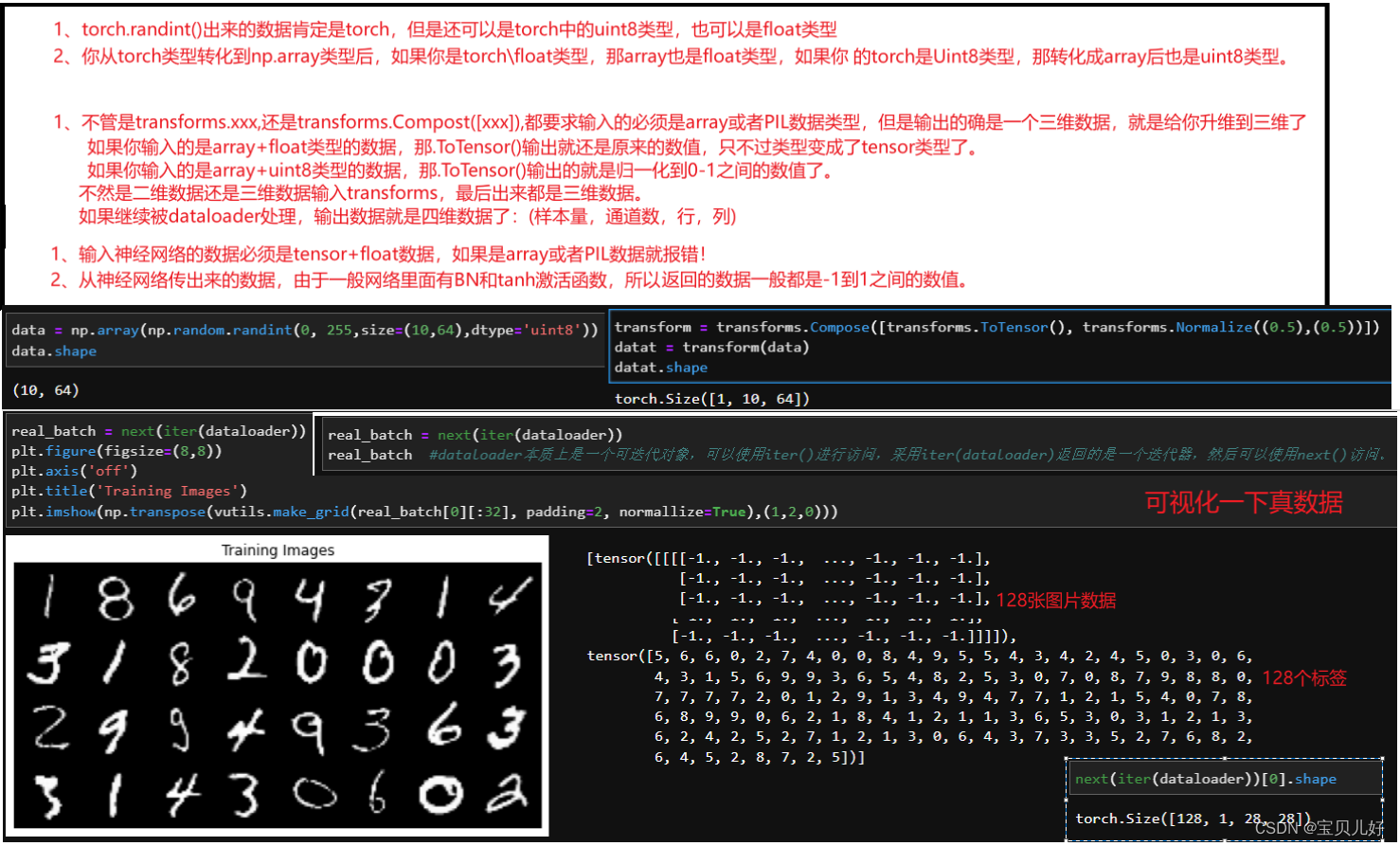
至此,我们就可以输入一个噪音或者一个随机数(尺寸是64)经过生成器,变成尺寸是784的图像数据,并且默认标签是0,就是假数据。然后把假数据和真实图像的数据(真实图像数据的标签默认是1,就是真数据)按照1:1的比例传入判别器,判别器输出simoid类概率值。这是正向传播过程,下面我们看反向传播过程:
反向传播其实就是求梯度+更新参数,也其实就是训练模型,也是让模型进行学习。而反向传播一定是从损失函数出发的求梯度的,只有有了具体的损失函数,并且明确是求损失函数的最大值还是最小值,才能反向一步步链式求得梯度值。当每步的梯度都确定后,才能用优化算法去迭代更新模型参数。这整个过程就是模型训练的过程,或者说是模型学习的过程。下面我把训练函数贴出来:

说明:
(1)迭代判别器时,使用的是判别器的损失函数,迭代方向是让判别器的损失逐渐减小。迭代生成器时,使用的是生成器的损失函数,迭代方向是让生成器的损失逐渐减小。所以,判别器和生成器的损失函数是不一样的!
由于生成器是尽量让生成的数据为真,所以生成器的损失就是它生成的数据都被判别器判断为了假。判别器的损失是把真数据判别为假,把假数据判别为真。从这个角度看,二者的本质都是一个二分类,所以二者的损失函数都可以用二分类交叉熵损失函数来表示,只是长的样子不一样:
判别器的损失函数是分真假样本分别计算的,就是先计算真样本判别器的损失,再计算假样本判别器的损失。而我们是尽量让真假样本的样本量都一样,这样判别器的平均损失就是:(真样本的总损失+假样本的总损 失)/(真样本量+假样本量)
但是在实际中,我们定义criterion=nn.BCELoss()是总是加一个参数reduction='mean',意思就是当我们正向传播一次真数据,我们就求了一下真数据的平均损失。当我们正向传播一次假数据,我们也求了一下假数据的平均损失。而且一般情况我们都让真数据的样本量=假数据的样本量,这样就不存在样本不均衡问题了。此时我们反向传播的时候,我们最好是对全部样本的平均损失进行反向传播,然后更新参数。而此时全部样本的平均损失=(真数据的平均损失+假数据的平均损失)/2。
(2)损失计算的相关知识点:
(3)细心的同学有没有发现其实上面的训练过程是有非常大的问题的!这也佐证了我说的,GAN最大的难点就是:很难训练!,当然,如果你的架构本身相对于训练数据,就绝对的强大时,那也不难训练。。。好,我们聊聊上面的训练流程有什么问题:
有没有发现,这样的训练流程下,其实生成器是很难被训练到的!要想知道原因,我们首先要搞懂backward()、optim.step()这些已经被pytorch封装得非常严实的代码背后的逻辑:
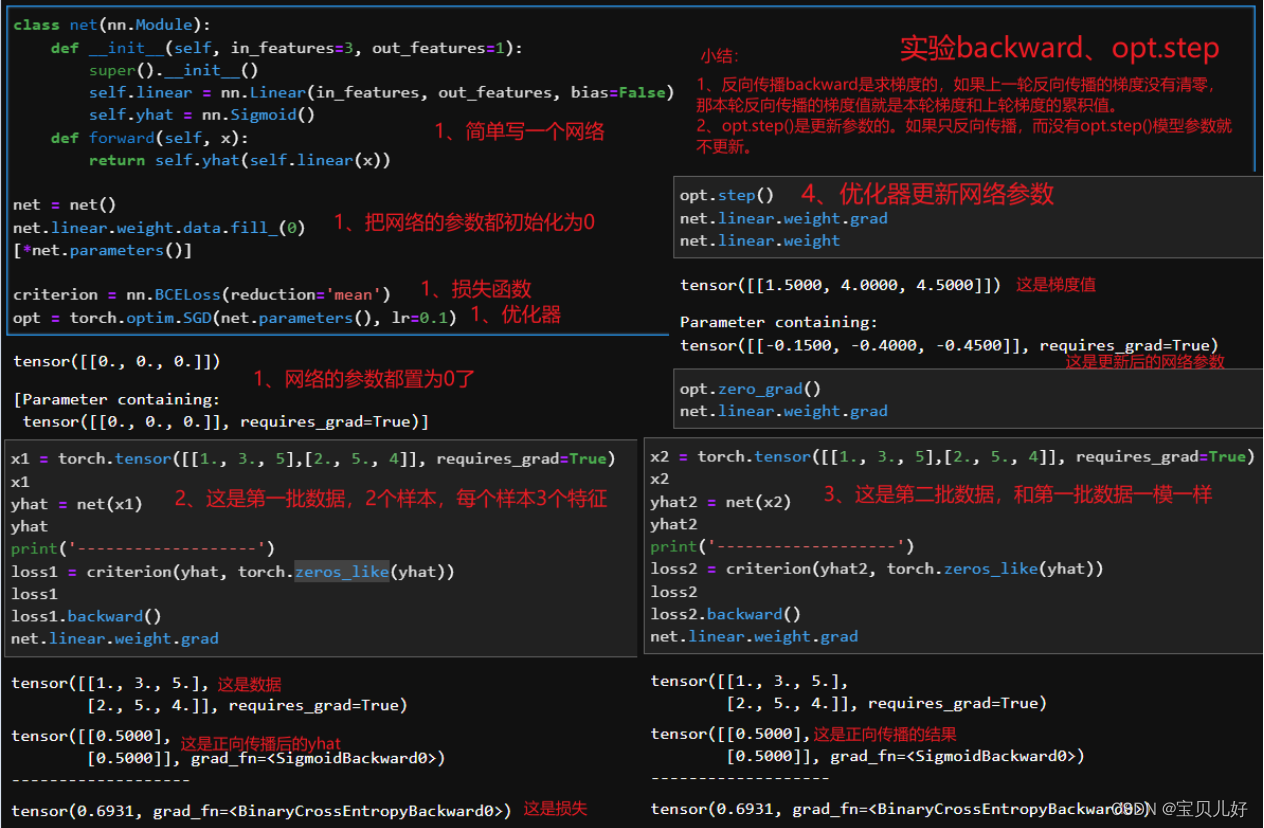
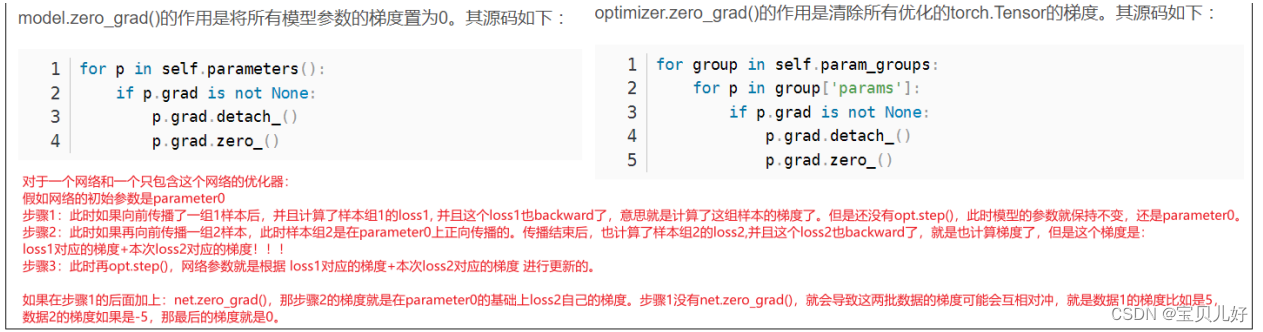
这些还不够,我们在从一个小例子中看看数据流,以及数据流过后,梯度计算-参数迭代的全过程:
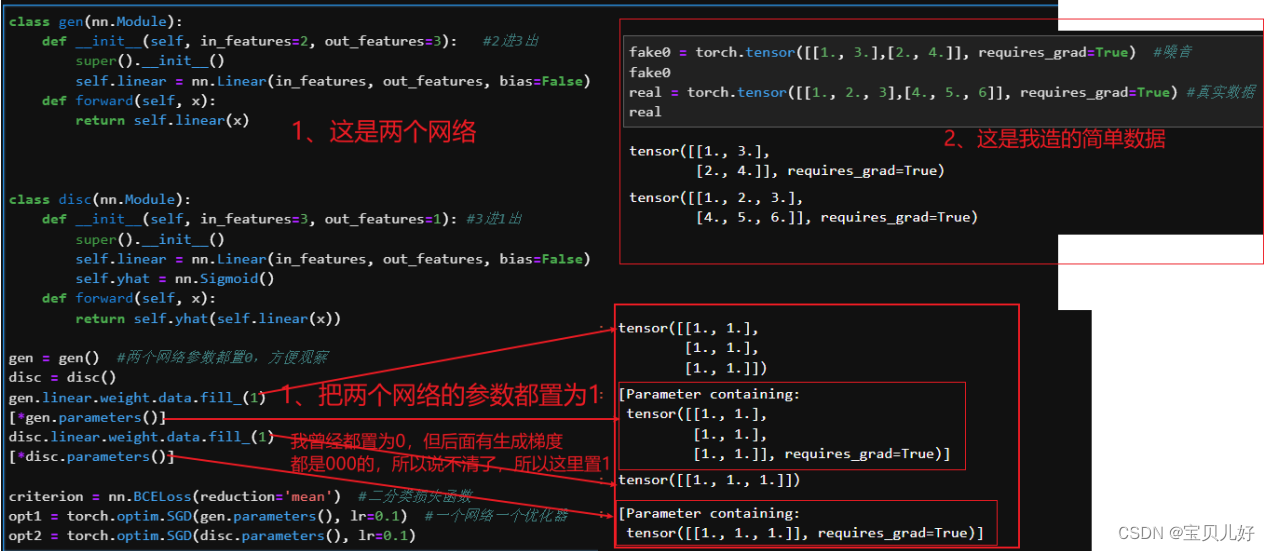
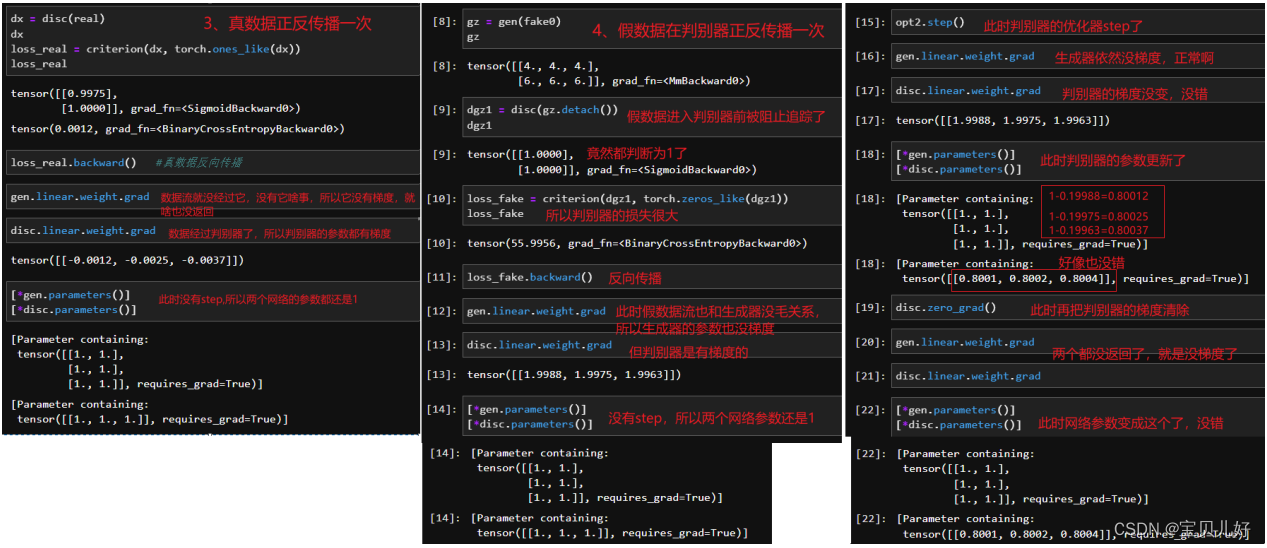
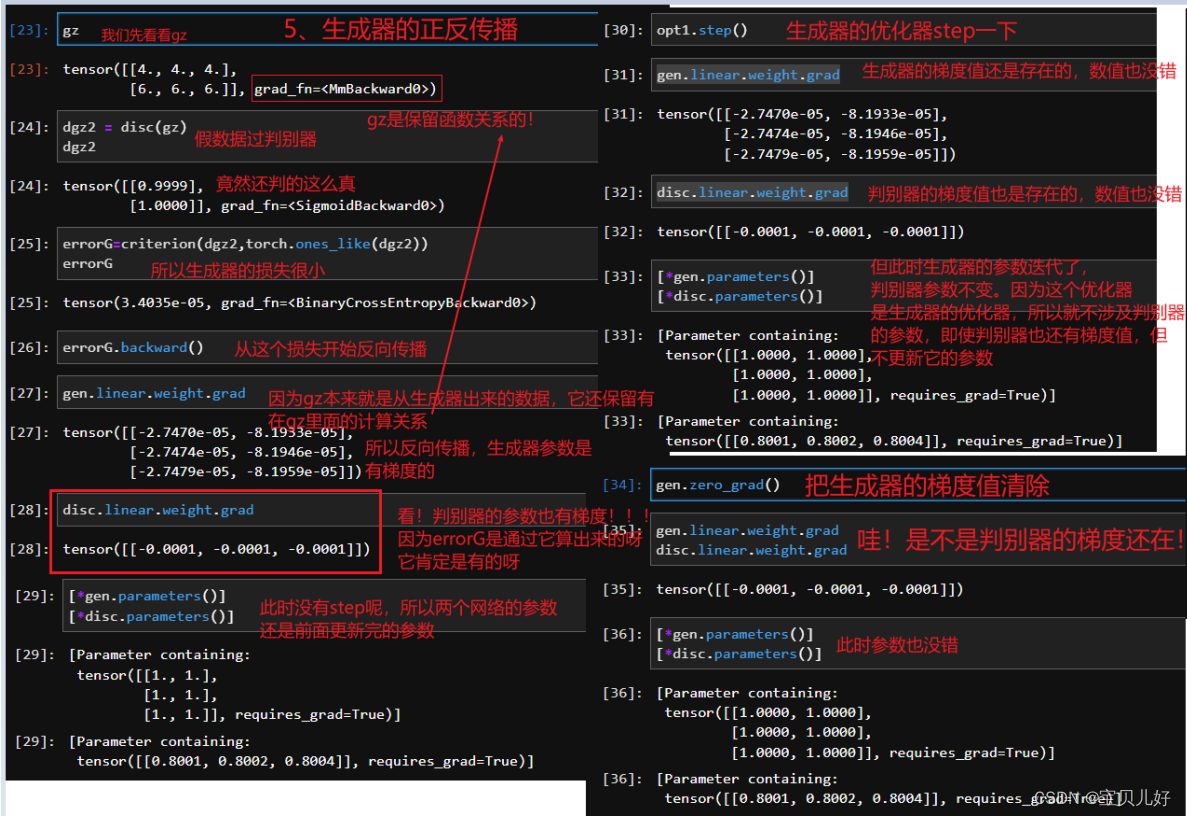
有没有发现问题出在哪里?
问题1:判别器在迭代的时候,判别器一方面要把真数据往1迭代,另一方面还得把假数据往0迭代,这个过程中很可能会出现比如:在把真数据往1迭代是的梯度是5,而把假数据往0迭代的梯度是-5,好嘛,这轮就别迭代了,向前走了5步又倒退了5步,还在原地!判别器也是无语了。是的,所以上述代码中,我自己加了个判断:如果假数据的梯度和真数据的梯度值方向相反,那我先迭代真数据的梯度,就是判别器先往能把真数据判1的方向走,假数据先靠边放放吧。。。anyway这也不是一个很好的解决方法啊!
问题2:生成器在迭代的时候,生成器的backward可是是从判别器最后一层出来的数据开始反向传播链式计算梯度的!但是我们opt.step生成器的时候,可是只step生成器,而没有step判别器啊,但是判别器的每一步也都是构成loss的呀,所以,要想生成器的loss快速下降,肯定是构成判别器loss的所有环节都下降,它才能下降啊,你只截个尾,只让后面几步下降,那势必生成器的损失很难下降的啊。也所以,我们有时训练GAN的时候,判别器的loss还好,比较容易训练到很小,但是生成器的loss始终保持高位,也就是生成器始终训练不成。就是始终是一种判别器相对越来越强、生成器相对越来越弱、甚至干脆就停止迭代了,这么一种情况。还是一句话:好难训练呀!
所以上述一个简单的手写数字MNIST,前面我们在VAE中,10个epochs,不到10分钟,都能生成有模有样的数字了,但是在上面的、用DNN搭建的GAN却始终无法得到个数字样!
这和生成器的损失函数有关,位于迭代的最末端,很容易得不到优化,这个架构就很难有效。所以我们暂时放弃这个网络。但是对抗的思想永垂不朽,上面的架构一是自身就很弱(就一个线性层嘛,能干啥呀?!有人会说我们前面的VAE不也是线性层嘛,我想说的是人家VAE是6个线性层好吧);二是也没有找到如何有效对抗的方法(就是上面的损失函数的设计还是有些不清晰),这就好比,你本来就是一个路痴的人,再加上一个模糊的导航,你就更迷糊了。
那我们现在再找一个自身就比较强大的架构——DCGAN,看这个架构在对抗的思想下的表现如何。
7、DCGAN
上面我们的案例是要生成手写数字图片,那要生成图片是不是用卷积层搭建的架构要强大一些呢?是滴,用卷积层搭建的对抗网络就是DCGAN。我们先科普一下DCGAN论文中一些观点:
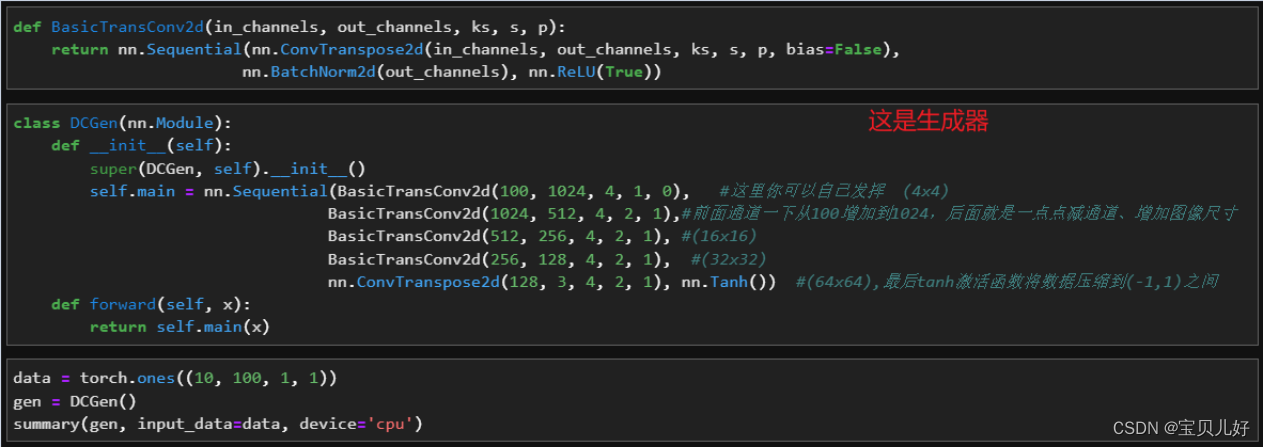
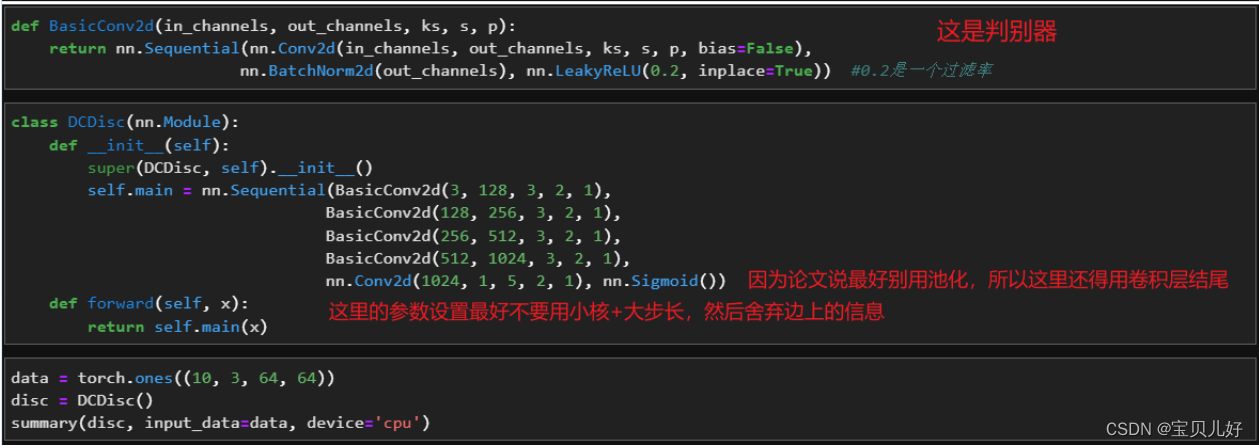
在Radford的论文《使用深度卷积生成对抗网络的无监督表示学习》(简称DCGAN)中,给出了DCGAN的一组经典参数和架构,就是生成器的具体架构和判别器的相应设置规则。其中,判别器可以是任意卷积架构,但判别器应该是和生成器势均力敌的,所以我们往往会参照生成器的架构去选择判别器架构的强度。意思就是如果我们的生成器只是一个简单的转置卷积层时,此时判别器你不能选择152层的残差网络作为判别器,而是倾向于构筑和生成器匹配的、也是只有一个简单的卷积层作为判别器。
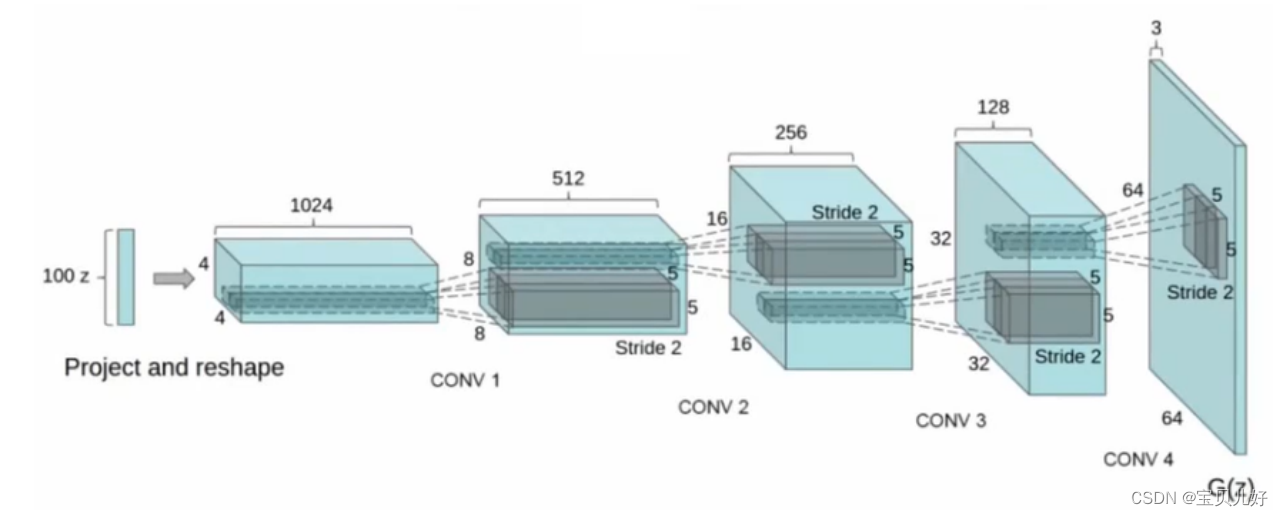
说明:
(1)上图是原论文DCGAN里面的生成器的架构图。一般情况下,很多论文都是只给出一个生成器的架构,默认判别器都是和生成器反向对应的,就是把生成器逆转一下,让判别器的结构与生成器的结构是两个完全相反的二分类或多分类架构。因为判别器是要和生成器势均力敌的。所以一般是不会给出判别器的架构的。这里生成器有4个隐藏层,那判别器也应该是4个对应的隐藏层。
(2)上图虽然写的是conv,其实是Transposed Convolution,是转置卷积层。
(3)上面架构从左往右看:图像尺寸越来越大,而且是翻倍变大的;而且通道数是从1024一层一层减半的, 直到输出层减到3。所以可以推导出这个架构用的转置卷积的参数是kernel_size=4, stride=2, padding=1这组参数。同理,也可以推导出判别器的参数是kernel_size=3, stride=2, padding=1这组可是将图像过一层尺寸砍半,而且判别器的通道数也是一层层翻倍的。当然也有人把判别器的参数设置得和生成器的参数一模一样,这样也是可以的,这样两个网络的参数量就完全 一模一样了。但我们这里最好用321这组参数,因为这组参数参数量比421少一点。
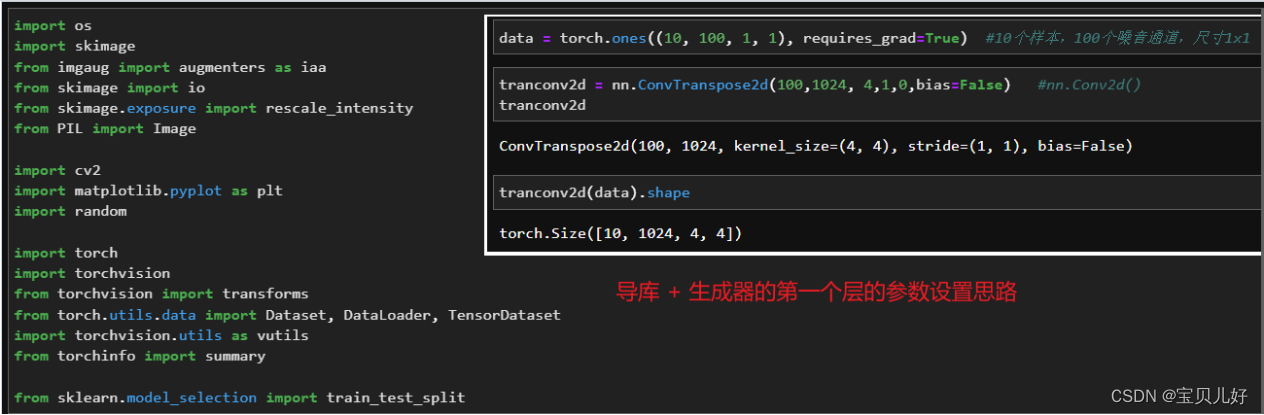
(4)上面架构的输入是一组随机噪音z,输出是1024张特征图,每张特征图都是4x4。上图作者只标了一个 project(映射)和reshape(变形),其他什么都没说。其实这里我们可以猜测,输入的噪音z的数据结构应该是(样本量,通道数,w, h),然后经过第一个转置卷积变成(样本量,1024,4,4)。所以我们可以自己配:假如我先将输入的z定为(m,100,1,1),我又想输出(m,1024,4,4),那此时我再看用什么样的卷积核步长和padding的转置卷积可以达到目的,那就怎么用。所以这里看你自己的选择了。

(5)架构的最终输出是具体某一大尺寸的图像,所以最终输出的数据结构应该是(样本量,3,64,64)。
(6)原论文给出的其他一些细节说明:

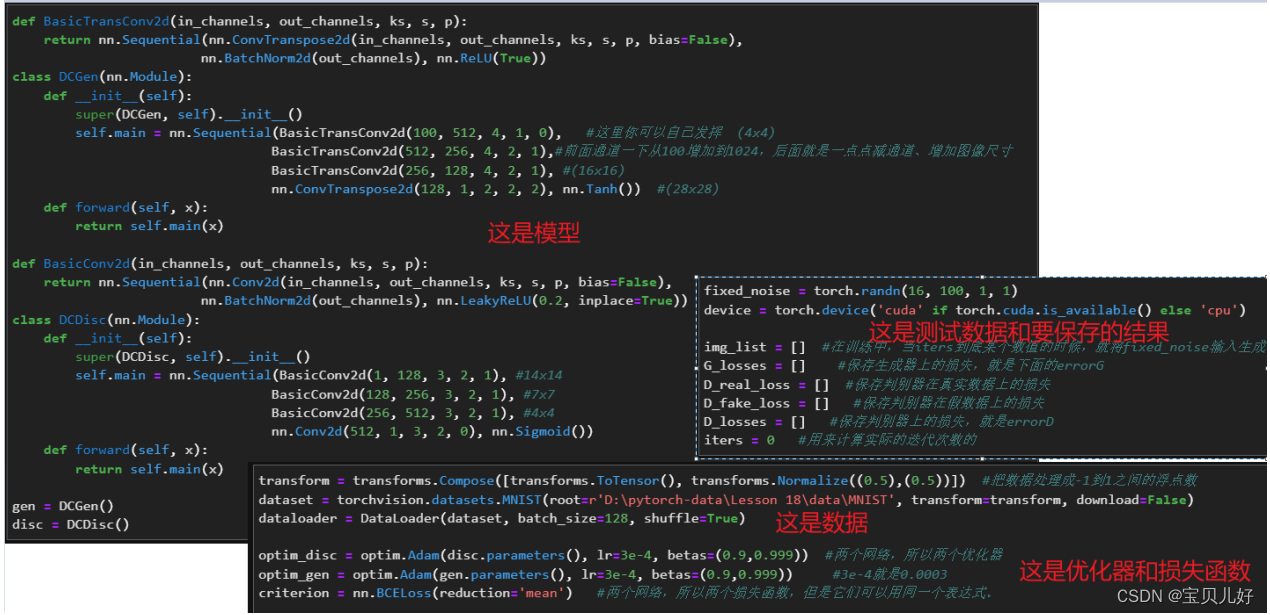
遵照作者的这些细节忠告,我们开始搭建DCGAN:
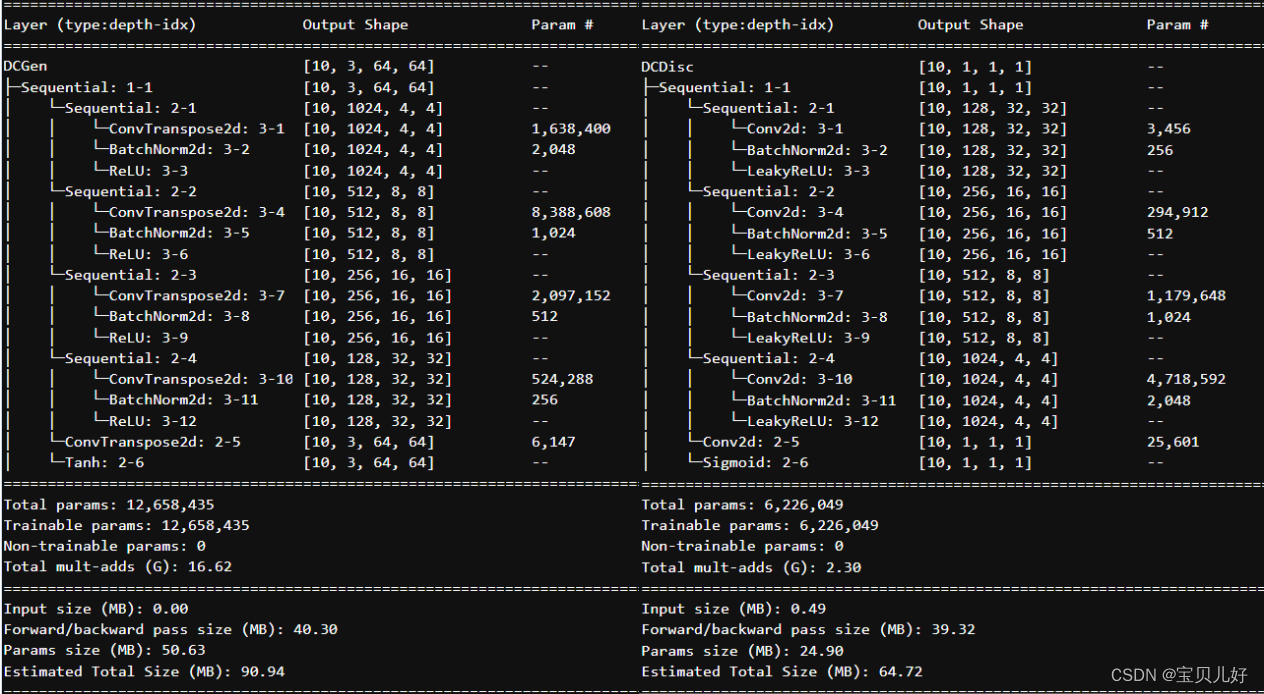
用它训练训练手写数字,看生成手写数字怎么样:
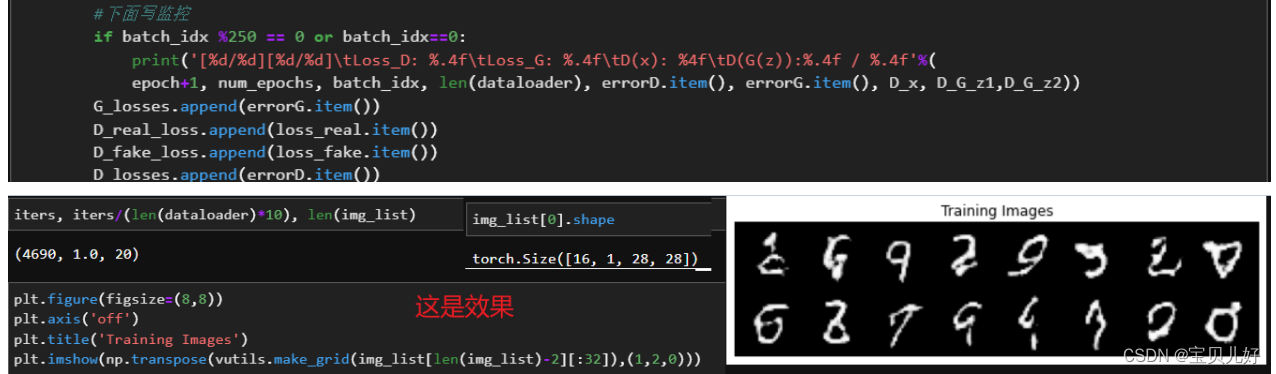
效果果然比DNN搭建的GAN要好很多!
说明:DCGAN这个架构是论文作者实验了很多次总结出来的性能最好的架构,以后我们用的时候尽量参考这个架构来搭建。下面我们看看GCGAN在LSUN数据集上的效果: 
8、使用DCGAN做生成图像的算术运算
上图中作者输入z0随机数时生成的是第一列图片,输入z1随机数时生成的是最右列图片。但是作者又给模型喂入了8个位于z0-z1之间的随机数,我们发现生成的图片是逐渐过渡的效果!那这是不是就说明我可以使用DCGAN做生成图像的算术运算!
上图的效果图中我们可以得到z码的启发:比如下图,我用z0生成的是戴眼镜的男人、用z1生成的是不戴眼镜的男人、用z3生成的是不戴眼镜的女人。那此时我们把随机数z3+(z0-z1)送入网络,就生成了戴眼镜的女人!当然这里的z也可以是随机向量,不一定非得是个随机数。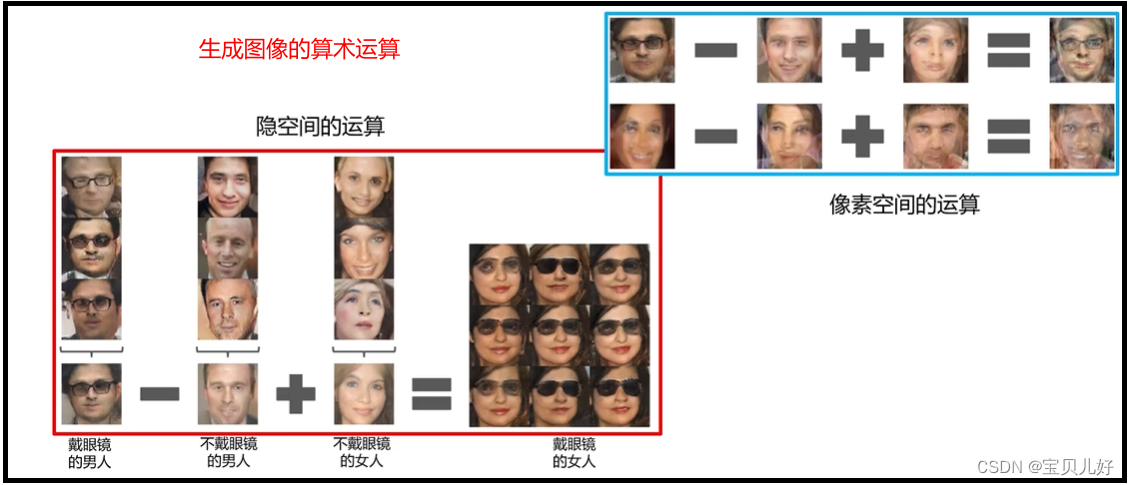
这就是使用DCGAN做生成图像的算术运算,非常有意思。















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









