









本篇文章仅仅是之前自己学习xgboost时的学习笔记,仅作备忘录之用。本篇文章大部分内容摘自多篇文章的精华部分,文章中及最后已注明出处,在此一并感谢各位大佬!
在能看懂下述推导的情况下,首先推荐一个这篇文章,写的炒鸡棒!吐血推荐!!!
XGBoost 推导思路

XGBoost 详细推导过程
XGBoost的目标函数由训练损失和正则化项两部分组成,目标函数定义如下:
O
b
j
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
)
+
∑
k
=
1
K
Ω
(
f
k
)
O b j = \sum _ { i = 1 } ^ { n } l \left( y _ { i } , \hat { y } _ { i } \right) + \sum _ { k = 1 } ^ { K } \Omega \left( f _ { k } \right)
Obj=i=1∑nl(yi,y^i)+k=1∑KΩ(fk)
由于XGBoost是一个加法模型,因此,预测得分是每棵树打分的累加之和。(注意预测的是得分 score,不是概率值!)
y
^
i
=
∑
k
=
1
K
f
k
(
x
i
)
,
f
k
∈
F
(
s
p
a
c
e
o
f
f
u
n
c
t
i
o
n
s
c
o
n
t
a
i
n
i
n
g
a
l
l
R
e
g
r
e
s
s
i
o
n
t
r
e
e
s
)
\hat { y } _ { i } = \sum _ { k = 1 } ^ { K } f _ { k } \left( x _ { i } \right) , \quad f _ { k } \in \mathcal { F }(space\ of\ functions\ containing\ all\ Regression\ trees)
y^i=k=1∑Kfk(xi),fk∈F(space of functions containing all Regression trees)
我们已知XGBoost 是一个加法模型,假设我们第
t
t
t次迭代要训练的树模型是
f
t
(
)
f_t()
ft(),则有:(理解:新生成的树是要拟合上次预测的残差的)
y
^
i
(
t
)
=
∑
k
=
1
t
f
k
(
x
i
)
=
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
\hat { y } _ { i } ^ { ( t ) } = \sum _ { k = 1 } ^ { t } f _ { k } \left( x _ { i } \right) = \hat { y } _ { i } ^ { ( t - 1 ) } + f _ { t } \left( x _ { i } \right)
y^i(t)=k=1∑tfk(xi)=y^i(t−1)+ft(xi)
注意上式中,只有一个变量,那就是第 t t t 棵树: f t ( x i ) f _ { t } \left( x _ { i } \right) ft(xi), 同时注意此时 y ^ i ( t − 1 ) \hat { y } _ { i } ^ { ( t - 1 ) } y^i(t−1) 和 ∑ k = 1 t − 1 Ω ( f k ) \sum _ { k = 1 } ^ { t - 1 } \Omega \left( f _ { k } \right) ∑k=1t−1Ω(fk) 为已知的常量。
所以此时的目标函数就可以变为:
Obj
(
t
)
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
t
)
)
+
∑
i
=
1
t
Ω
(
f
i
)
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
)
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
\begin{aligned} \operatorname { Obj } ^ { ( t ) } & = \sum _ { i = 1 } ^ { n } l \left( y _ { i } , \ \hat { y } _ { i } ^ { ( t ) } \right) + \sum _ { i = 1 } ^ { t } \Omega \left( f _ { i } \right) \\ & = \sum _ { i = 1 } ^ { n } l \left( y _ { i } , \ \hat { y } _ { i } ^ { ( t - 1 ) } + f _ { t } \left( x _ { i } \right) \right) + \Omega \left( f _ { t } \right) + constant \end{aligned}
Obj(t)=i=1∑nl(yi, y^i(t))+i=1∑tΩ(fi)=i=1∑nl(yi, y^i(t−1)+ft(xi))+Ω(ft)+constant
考虑二阶泰勒展开: f ( x + Δ x ) ≃ f ( x ) + f ′ ( x ) Δ x + 1 2 f ′ ′ ( x ) Δ x 2 f ( x + \Delta x ) \simeq f ( x ) + f ^ { \prime } ( x ) \Delta x + \frac { 1 } { 2 } f ^ { \prime \prime } ( x ) \Delta x ^ { 2 } f(x+Δx)≃f(x)+f′(x)Δx+21f′′(x)Δx2
那么,我们的损失函数就可以转化为下式:
O
b
j
(
t
)
≃
∑
i
=
1
n
[
l
(
y
i
,
y
^
i
(
t
−
1
)
)
+
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
O b j ^ { ( t ) } \simeq \sum _ { i = 1 } ^ { n } \left[ l \left( y _ { i } ,\ \hat { y } _ { i } ^ { ( t - 1 ) } \right) + g _ { i } f _ { t } \left( x _ { i } \right) + \frac { 1 } { 2 } h _ { i } f _ { t } ^ { 2 } \left( x _ { i } \right) \right] + \Omega \left( f _ { t } \right) + constant
Obj(t)≃i=1∑n[l(yi, y^i(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)+constant
去掉上式的全部常数项,得到目标函数:
O
b
j
(
t
)
≃
∑
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
O b j ^ { ( t ) } \simeq \sum _ { i = 1 } ^ { n } \left[ g _ { i } f _ { t } \left( x _ { i } \right) + \frac { 1 } { 2 } h _ { i } f _ { t } ^ { 2 } \left( x _ { i } \right) \right] + \Omega \left( f _ { t } \right)
Obj(t)≃i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)
其中: g i = ∂ y ^ i ( t − 1 ) ( y i − y ^ i ( t − 1 ) ) 2 = 2 ( y ^ i ( t − 1 ) − y i ) h i = ∂ y ^ i ( t − 1 ) 2 ( y i − y ^ i ( t − 1 ) ) 2 = 2 g _ { i } = \partial _ { \hat { y }_i ^ { ( t - 1 ) } } \left( y _ { i } - \hat { y }_i ^ { ( t - 1 ) } \right) ^ { 2 } = 2 \left( \hat { y }_i ^ { ( t - 1 ) } - y _ { i } \right) \quad h _ { i } = \partial _ { \hat { y }_i ^ { ( t - 1 ) } } ^ { 2 } \left( y _ { i } - \hat { y }_i ^ { ( t - 1 ) } \right) ^ { 2 } = 2 gi=∂y^i(t−1)(yi−y^i(t−1))2=2(y^i(t−1)−yi)hi=∂y^i(t−1)2(yi−y^i(t−1))2=2
此外,我们还要定义树的复杂度:
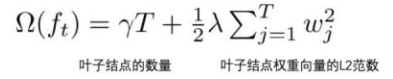
下面就是叶子节点分组:

Define the instance set in leaf
j
j
j as
I
j
=
{
i
∣
q
(
x
i
)
=
j
}
I _ { j } = \left\{ \ i\ | \ q \left( x _ { i } \right) = j \right\}
Ij={ i ∣ q(xi)=j}
Regroup the objective by each leaf:
Obj
(
t
)
≃
∑
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
=
∑
i
=
1
n
[
g
i
w
q
(
x
i
)
+
1
2
h
i
w
q
(
x
i
)
2
]
+
γ
T
+
λ
1
2
∑
j
=
1
T
w
j
2
=
∑
j
=
1
T
[
(
∑
i
∈
I
j
g
i
)
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
\begin{aligned} \operatorname { Obj } ^ { ( t ) } & \simeq \sum _ { i = 1 } ^ { n } \left[ g _ { i } f _ { t } \left( x _ { i } \right) + \frac { 1 } { 2 } h _ { i } f _ { t } ^ { 2 } \left( x _ { i } \right) \right] + \Omega \left( f _ { t } \right) \\ & = \sum _ { i = 1 } ^ { n } \left[ g _ { i } w _ { q \left( x _ { i } \right) } + \frac { 1 } { 2 } h _ { i } w _ { q \left( x _ { i } \right) } ^ { 2 } \right] + \gamma T + \lambda \frac { 1 } { 2 } \sum _ { j = 1 } ^ { T } w _ { j } ^ { 2 } \\ & = \sum _ { j = 1 } ^ { T } \left[ \left( \sum _ { i \in I _ { j } } g _ { i } \right) w _ { j } + \frac { 1 } { 2 } \left( \sum _ { i \in I _ { j } } h _ { i } + \lambda \right) w _ { j } ^ { 2 } \right] + \gamma T \end{aligned}
Obj(t)≃i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)=i=1∑n[giwq(xi)+21hiwq(xi)2]+γT+λ21j=1∑Twj2=j=1∑T⎣⎡⎝⎛i∈Ij∑gi⎠⎞wj+21⎝⎛i∈Ij∑hi+λ⎠⎞wj2⎦⎤+γT
为进一步简化该式,我们进行如下定义:
G
j
=
∑
i
∈
I
j
g
i
H
j
=
∑
i
∈
I
j
h
i
G _ { j } = \sum _ { i \in I _ { j } } g _ { i } \quad H _ { j } = \sum _ { i \in I _ { j } } h _ { i }
Gj=i∈Ij∑giHj=i∈Ij∑hi
含义如下:
- G j G_j Gj :叶子结点 j j j 所包含样本的一阶偏导数累加之和,是一个常量;
- H j H_j Hj :叶子结点 j j j 所包含样本的二阶偏导数累加之和,是一个常量;
将
G
j
G_j
Gj 和
H
j
H_j
Hj 带入目标式
Obj
(
t
)
\operatorname { Obj } ^ { ( t ) }
Obj(t),得到我们最终的目标函数(注意,此时式中的变量只剩下第
t
t
t 棵树的权重向量
w
w
w ):
O
b
j
(
t
)
=
∑
j
=
1
T
[
(
∑
i
∈
I
j
g
i
)
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
=
∑
j
=
1
T
[
G
j
w
j
+
1
2
(
H
j
+
λ
)
w
j
2
]
+
γ
T
\begin{aligned} O b j ^ { ( t ) } & = \sum _ { j = 1 } ^ { T } \left[ \left( \sum _ { i \in I _ { j } } g _ { i } \right) w _ { j } + \frac { 1 } { 2 } \left( \sum _ { i \in I _ { j } } h _ { i } + \lambda \right) w _ { j } ^ { 2 } \right] + \gamma T \\ & = \sum _ { j = 1 } ^ { T } \left[ G _ { j } w _ { j } + \frac { 1 } { 2 } \left( H _ { j } + \lambda \right) w _ { j } ^ { 2 } \right] + \gamma T \end{aligned}
Obj(t)=j=1∑T⎣⎡⎝⎛i∈Ij∑gi⎠⎞wj+21⎝⎛i∈Ij∑hi+λ⎠⎞wj2⎦⎤+γT=j=1∑T[Gjwj+21(Hj+λ)wj2]+γT
下面是树结构打分:
根据上面推导出的最终的目标函数,我们可以发现:这就是初中数学的一个简单的一元二次函数求极值的问题。对于每个叶子结点
j
j
j , 可以将其从目标式
Obj
(
t
)
\operatorname { Obj } ^ { ( t ) }
Obj(t) 中拆解出来:
G
j
w
j
+
1
2
(
H
j
+
λ
)
w
j
2
G _ { j } w _ { j } + \frac { 1 } { 2 } \left( H _ { j } + \lambda \right) w _ { j } ^ { 2 }
Gjwj+21(Hj+λ)wj2
G j G _ { j } Gj 和 H j H_j Hj 相对于第 t t t 棵树来说是可以计算出来的。那么,这个式子就是一个只包含一个变量 叶子结点权重 w j w_j wj 的一元二次函数,我们可以通过最值公式求出它的最值点。
再次分析一下目标函数 Obj ( t ) \operatorname { Obj } ^ { ( t ) } Obj(t),可以发现,各个叶子结点的目标子式是相互独立的,也就是说,当每个叶子结点的子式都达到最值点时,整个目标函数式 Obj ( t ) \operatorname { Obj } ^ { ( t ) } Obj(t) 才达到最值点。
那么,假设目前树的结构已经固定,套用一元二次函数的最值公式,我们可以轻易求出,每个叶子结点的权重
w
j
w _ { j }
wj 及其此时达到最优的
Obj
(
t
)
\operatorname { Obj } ^ { ( t ) }
Obj(t) 的目标值:
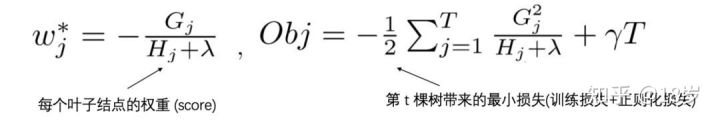
至此,XGBoost大体的推导过程已经介绍完了,总结如下:

树的生长细节
分裂一个结点
在实际训练过程中,当建立第 t t t 棵树时,XGBoost采用贪心法进行树结点的分裂:
从树深为0时开始:
- 对树中的每个叶子结点尝试进行分裂;
- 每次分裂后,原来的一个叶子结点继续分裂为左右两个子叶子结点,原叶子结点中的样本集将根据该结点的判断规则分散到左右两个叶子结点中;
- 新分裂一个结点后,我们需要检测这次分裂是否会给损失函数带来增益,增益的定义如下:
G a i n = O b j L + R − ( O b j L + O b j R ) = [ − 1 2 ( G L + G R ) 2 H L + H R + λ + γ ] − [ − 1 2 ( G L 2 H L + λ + G R 2 H R + λ ) + 2 γ ] = 1 2 [ G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ ] − γ \begin{aligned} Gai n & = O b j _ { L + R } - \left( O b j _ { L } + O b j _ { R } \right) \\ & = \left[ - \frac { 1 } { 2 } \frac { \left( G _ { L } + G _ { R } \right) ^ { 2 } } { H _ { L } + H _ { R } + \lambda } + \gamma \right] - \left[ - \frac { 1 } { 2 } \left( \frac { G _ { L } ^ { 2 } } { H _ { L } + \lambda } + \frac { G _ { R } ^ { 2 } } { H _ { R } + \lambda } \right) + 2 \gamma \right] \\ & = \frac { 1 } { 2 } \left[ \frac { G _ { L } ^ { 2 } } { H _ { L } + \lambda } + \frac { G _ { R } ^ { 2 } } { H _ { R } + \lambda } - \frac { \left( G _ { L } + G _ { R } \right) ^ { 2 } } { H _ { L } + H _ { R } + \lambda } \right] - \gamma \end{aligned} Gain=ObjL+R−(ObjL+ObjR)=[−21HL+HR+λ(GL+GR)2+γ]−[−21(HL+λGL2+HR+λGR2)+2γ]=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−γ
如果增益 G a i n > 0 Gain>0 Gain>0,即分裂为两个叶子节点后,目标函数下降了,那么我们会考虑此次分裂的结果。
但是,在一个结点分裂时,可能有很多个分裂点,每个分裂点都会产生一个增益,如何才能寻找到最优的分裂点呢?接下来会讲到。
寻找最佳分裂点
在分裂一个结点时,我们会有很多个候选分割点,寻找最佳分割点的大致步骤如下:
- 遍历每个结点的每个特征;
- 对每个特征,按特征值大小将特征值排序;
- 线性扫描,找出每个特征的最佳分裂特征值;
- 在所有特征中找出最好的分裂点(分裂后增益最大的特征及其特征值)
上面是一种贪心的方法,每次进行分裂尝试都要遍历一遍全部候选分割点,也叫做全局扫描法。
但当数据量过大导致内存无法一次载入或者在分布式情况下,贪心算法的效率就会变得很低,全局扫描法不再适用。
基于此,XGBoost提出了一系列加快寻找最佳分裂点的方案:
- 特征预排序+缓存:XGBoost在训练之前,预先对每个特征按照特征值大小进行排序,然后保存为block结构,后面的迭代中会重复地使用这个结构,使计算量大大减小。
- 分位点近似法:对每个特征按照特征值排序后,采用类似分位点选取的方式,仅仅选出常数个特征值作为该特征的候选分割点,在寻找该特征的最佳分割点时,从候选分割点中选出最优的一个。
- 并行查找:由于各个特性已预先存储为block结构,XGBoost支持利用多个线程并行地计算每个特征的最佳分割点,这不仅大大提升了结点的分裂速度,也极利于大规模训练集的适应性扩展。
停止生长
一棵树不会一直生长下去,下面是一些常见的限制条件。
-
当新引入的一次分裂所带来的增益 G a i n < 0 Gain<0 Gain<0 时,放弃当前的分裂。这是训练损失和模型结构复杂度的博弈过程。

-
当树达到最大深度时,停止建树,因为树的深度太深容易出现过拟合,这里需要设置一个超参数 m a x d e p t h max_depth maxdepth。
-
当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值(官网api中这个权重指的是二阶导数 H j H_j Hj,即要求 m i n ( H L , H j ) > m i n _ c h i l d _ w e i g h t min(H_L,\ H_j) > min\_child\_weight min(HL, Hj)>min_child_weight),也会放弃此次分裂。这涉及到一个超参数:最小样本权重和,是指如果一个叶子节点包含的样本数量太少也会放弃分裂,防止树分的太细,这也是过拟合的一种措施。
每个叶子结点的样本权值和计算方式如下:
w j ∗ = − G j H j + λ w _ { j } ^ { * } = - \frac { G _ { j } } { H _ { j } + \lambda } wj∗=−Hj+λGj
常见问题
- XGB与GBDT、随机森林等模型相比,有什么优缺点?
- XGB为什么可以并行训练?
- XGB用二阶泰勒展开的优势在哪?
- XGB为了防止过拟合,进行了哪些设计?
- XGB如何处理缺失值?
- XGB如何分裂一个结点?如何选择特征?
- XGB中一颗树停止生长的条件有哪些?
- XGB叶子结点的权重有什么含义?如何计算?
- 训练一个XGB模型,经历了哪些过程?调参步骤是什么?
- XGB如何给特征评分?
面试题-参考答案: 珍藏版 | 20道XGBoost面试题
具体例子
https://www.jianshu.com/p/ac1c12f3fba1
References
- https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
- https://www.jianshu.com/p/ac1c12f3fba1
- https://zhuanlan.zhihu.com/p/92837676
- https://www.zhihu.com/question/58883125
- https://zhuanlan.zhihu.com/p/34679467
- https://mp.weixin.qq.com/s?__biz=MzI1MzY0MzE4Mg==&mid=2247485159&idx=1&sn=d429aac8370ca5127e1e786995d4e8ec&chksm=e9d01626dea79f30043ab80652c4a859760c1ebc0d602e58e13490bf525ad7608a9610495b3d&scene=21#wechat_redirect
- https://blog.csdn.net/v_JULY_v/article/details/81410574















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









