









简介
首先极力推荐大佬文章,大佬就是大佬,写得超好,膜。。。
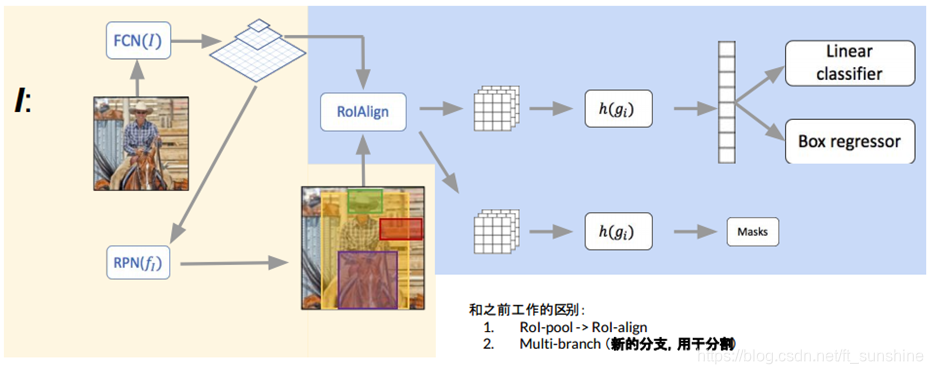
Mask R-CNN沿用了Faster R-CNN的思想,特征提取采用ResNet-FPN的架构(多尺度,详见博客),其次,Mask R-CNN将Faster R-CNN的RoI Pooling改为了RoI Align,另外多加了一个Mask预测分支。综上,Mask R-CNN一共有以下三点改进:
- 用ResNet-FPN做backbone,有利于多尺度物体的检测和分割;
- RoI Pooling -> RoI Align;
- 新加了一个mask分支;
可见Mask RCNN综合了很多此前优秀的研究成果,并且其在工业界中也被广泛使用,效果很好。
注:要了解Mask R-CNN,需要以下知识:(后面给出了参考文章链接,在此不再赘述。)
在熟悉以上基础之后,我们就会发现:Mask R-CNN == ResNet-FPN + Faster R-CNN + Mask。
网络结构
Mask R-CNN的网络结构如图:

Mask RCNN的构建很简单,只是在ROI pooling(实际上用到的是ROIAlign,后面会讲到)之后添加卷积层,进行mask预测的任务。
下面总结一下Mask R-CNN的网络:(额。。。其实了解了前面的那些基础之后,Mask RCNN就已经很简单了)
- 骨干网络ResNet-FPN,用于特征提取;
- 得到backbone提取好的特征(feature map)后,后面还是接的Faster R-CNN的那一套东西,不过将RoI Pooling 改为了RoI Align;
- 新加Mask分支,所以Mask R-CNN的头部网络如下所示:

ROI Align
实际上,Mask RCNN中还有一个很重要的改进,就是ROIAlign。Faster R-CNN存在的问题是:特征图与原始图像是不对准的(mis-alignment),所以会影响检测精度。而Mask R-CNN提出了RoIAlign的方法来取代ROI pooling,RoIAlign可以保留更精确的空间位置。
为了讲清楚ROI Align,需要明白两个知识点,双线性插值和ROI pooling。(在上面推荐的文章中都讲过了)
首先,我们为什么要用ROIAlign呢 ?
ROI Align 是在Mask-RCNN这篇论文里提出的一种区域特征聚集方式,很好地解决了ROI Pooling操作中两次量化造成的区域不匹配(mis-alignment) 的问题。
这两次量化分别为:
- region proposal的 x , y , w , h x, y, w, h x,y,w,h通常是小数,但是为了方便操作会把它整数化。
- 将整数化后的边界区域平均分割成 k × k k \times k k×k个单元,对每一个单元的边界进行整数化。
两次整数化(量化)的过程如下图所示:(图片来自知乎文章)
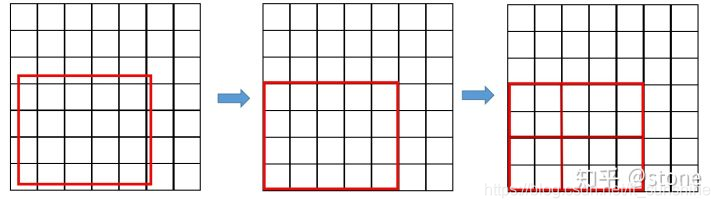
事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为 “不匹配问题(mis-alignment)。
为了解决这个问题,ROI Align方法取消整数化操作,保留了小数,使用双线性插值的方法获得坐标为浮点数的像素点的数值。但在实际操作中,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后进行池化,而是重新进行设计。 下面我们通过两个例子来说明:
例子1
如下图所示,虚线部分表示feature map,实线表示ROI,这里将ROI切分成2x2的单元格。如果采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行maxpooling,就可以得到最终的ROIAlign的结果。
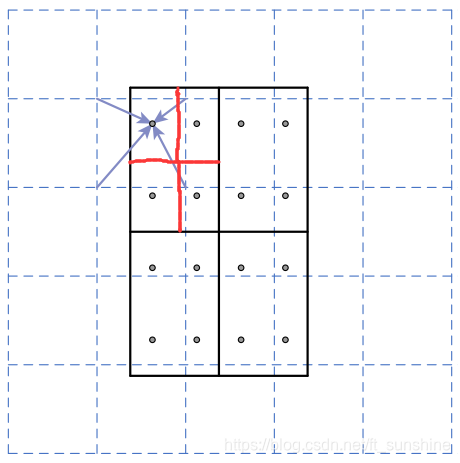
需要说明的是,在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。
例子2
下面我们再通过一个更直观的例子具体分析一下上述区域不匹配问题,如下图所示:
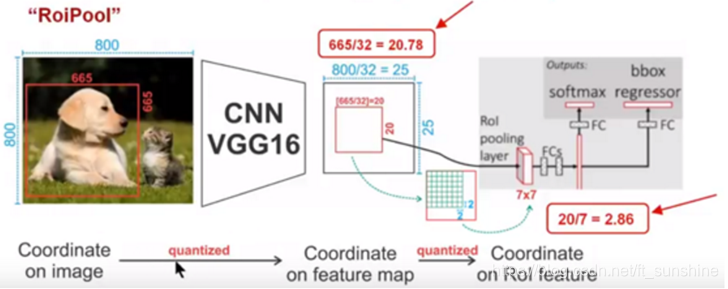
如上图所示,这是一个Faster-RCNN检测框架。输入一张
800
∗
800
800*800
800∗800的图片,图片上有一个
665
∗
665
665*665
665∗665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为
32
32
32。因此,图像和包围框的边长都是输入时的
1
/
32
1/32
1/32。
800
800
800正好可以被32整除变为25。但
665
665
665除以
32
32
32以后得到
20.78
20.78
20.78,带有小数。于是ROI Pooling 直接将它量化成
20
20
20。接下来需要把框内的特征池化为
7
∗
7
7*7
7∗7的大小,因此将上述包围框平均分割成
7
∗
7
7*7
7∗7个矩形区域。显然,每个矩形区域的边长为
2.86
2.86
2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。如下:

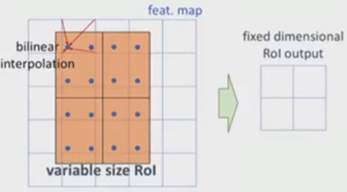
ROI Align操作如下:
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成 k × k k \times k k×k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
以上就是ROI Align的操作,想必大家已经很清楚了吧。。。。
损失函数
Mask R-CNN的损失函数为:
L
=
L
c
l
s
+
L
b
o
x
+
L
m
a
s
k
L=L_{c l s}+L_{b o x}+L_{m a s k}
L=Lcls+Lbox+Lmask

L
c
l
s
L_{cls}
Lcls 和
L
b
o
x
L_{box}
Lbox 与Faster R-CNN的定义没有区别。需要具体说明的是
L
m
a
s
k
L_{mask}
Lmask ,假设一共有
K
K
K个类别,则mask分割分支(使用的是FCN)的输出维度是
K
×
m
×
m
K \times m \times m
K×m×m。对于
m
×
m
m \times m
m×m 中的每个点,都会输出K个二值Mask(每个类别使用sigmoid输出)。需要注意的是,计算loss的时候,并不是每个类别的sigmoid输出都计算二值交叉熵损失,而是该像素属于哪个类,哪个类的sigmoid输出才要计算损失(如图红色方形所示)。并且在测试的时候,我们是通过分类分支预测的类别来选择相应的mask预测。这样,mask预测和分类预测就彻底解耦了。
还感觉有点迷的话推荐看大佬的视频。















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









