








人脸识别自己训练模型
OpenCV3官方中的级联分类器目标检测——cv::CascadeClassifier,介绍了如何使用级联分类器进行目标检测。而且人家也训练好了,可以自己去opencv里面找。这里,我们介绍一下如何训练自己的级联分类器。
直接说明如何进行训练。在opencv的安装目录中的bin文件夹下有两个可执行文件opencv_createsamples.exe和opencv_traincascade.exe。将这两个文件拷贝到训练文件夹下,并将正、负样本的文件夹和描述文件——positive_samples.txt和negative_samples.txt也拷贝到这个文件夹下。同时,新建两个.bat文件——create_positive_samples.bat和traincascade.bat,新建一个文件夹data。这样,训练目录如下:




其中,-info字段填写正样本描述文件;-vec用于保存制作的正样本;-num制定正样本的数目;-w和-h分别指定正样本的宽和高。
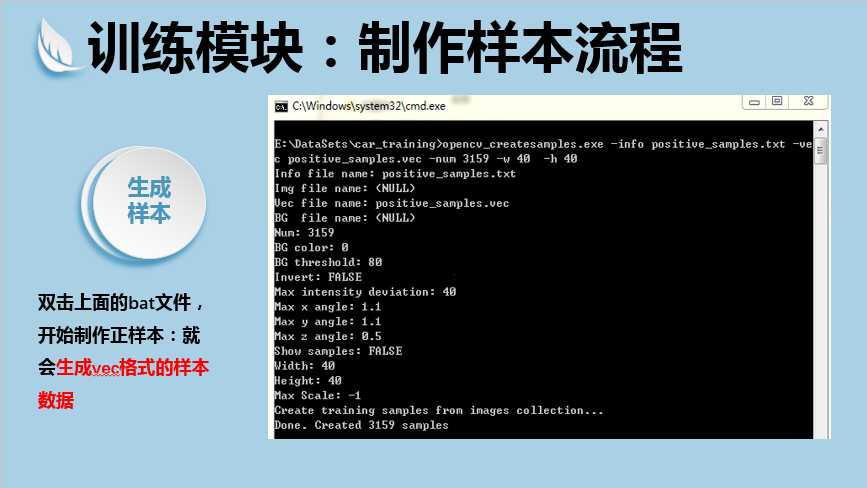
这样,正样本制作完成。
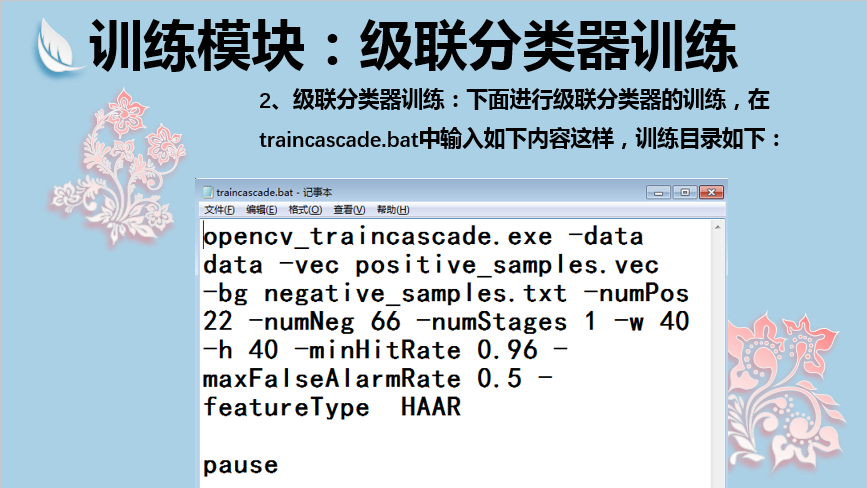
字段说明如下:
-data:指定保存训练结果的文件夹;
-vec:指定正样本集;
-bg:指定负样本的描述文件夹;
-numPos:指定每一级参与训练的正样本的数目(要小于正样本总数);
-numNeg:指定每一级参与训练的负样本的数目(可以大于负样本图片的总数);
-numStage:训练的级数;
-w:正样本的宽;
-h:正样本的高;
-minHitRate:每一级需要达到的命中率(一般取值0.95-0.995);
-maxFalseAlarmRate:每一级所允许的最大误检率;
-mode:使用Haar-like特征时使用,可选BASIC、CORE或者ALL;
另外,还可指定以下字段:
-featureType:可选HAAR或LBP,默认为HAAR;
其他字段将不再说明。
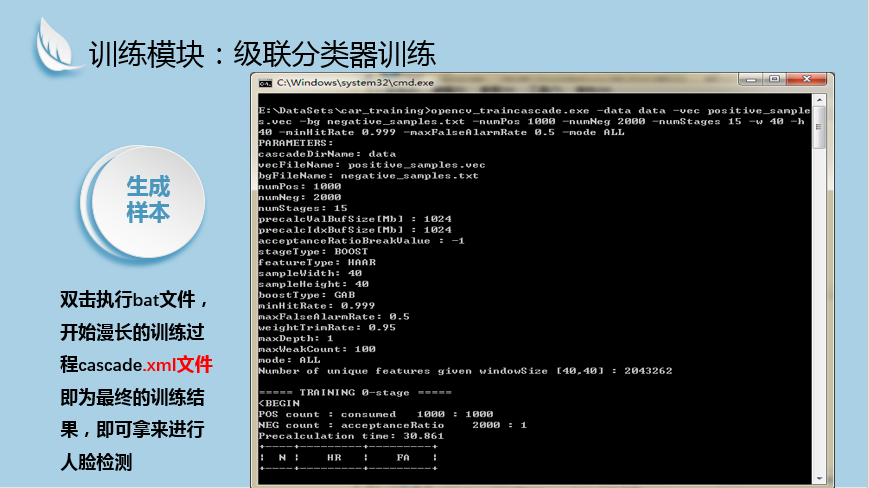
总结:
1数据准备。
Python代码。图片要记得同一尺寸,放到sample_positive文件夹里。
负样本数据要Python趴图片。
主要生出二进制的vector文件,执行bat时候系统报错少了D:\opencv\opencv3-3\opencv\build\x64\vc14\bin 里面opencv_world330.dll文件。放到同级目录下就可以了。
bat换行不能乱来
大小写ALL错了
-nstages 预先设定的分类器级数,但是如果你的负样本不给力的话,这句有跟没有一样,就是报这个参数不行,跑步起来。
-npos 每级需要的正样本的数目,这个值一定不要超过你的真实正样本的值(比如50张正样本,你就 设为45),不然就会assert报错,具体原因并不清楚,有点莫名其妙!
.样本选择的原则是:数量越多越好,尽量高于1000;样本间差异性越大越好
3.正负样本比例为1:3最佳,尺寸为20x20最佳


http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html
这篇文章写的最详细,最易理解。
本来打算讲一下用深度学习训练的方法,可是训练人脸识别的时候,把caffe搞崩了,所以后面懒得再按装了,所以就没继续搞了。很遗憾。但是我们导师要转到TensorFlow,有机会的话,可能会用tf来跑一下试试。
参考资料:
https://blog.csdn.net/guduruyu/article/details/70183372
http://www.opencv.org.cn/opencvdoc/2.3.2/html/modules/gpu/doc/object_detection.html?highlight=cascadeclassifier
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/objdetect/cascade_classifier/cascade_classifier.html?highlight=cascadeclassifier
http://www.opencv.org.cn/opencvdoc/2.3.2/html/modules/objdetect/doc/cascade_classification.html?highlight=opencv_traincascade
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html?highlight=opencv_haartraining















 9771
9771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









