







实验课任务,简单走了一遍流程,进行记录。
-
论文
UNet: https://arxiv.org/abs/1505.04597
Transformer:https://arxiv.org/abs/1706.03762v5
TransUNet:https://arxiv.org/abs/2102.04306. -
研究背景
\quad 众所周知UNet基本是医学图像分割的魔改基础配方。由于卷积网络的内在局部性,卷积网络在远程关系显式建模上存在限制{感觉意思是一张输入图片左上角和右下角信息很难直接卷在一起},因而在不同病例数据纹理形状大小相对差别较大时效果欠佳。
\quad Transformer的结构针对序列处理设计,能一定程度上解决此问题。文章作者将Transformer应用于医学分割问题,结果也不令人满意。大概是因为Transformer将输入数据作为一维序列处理,失去了大量位置信息所致。 -
UNet【1】
其结构如图所示:
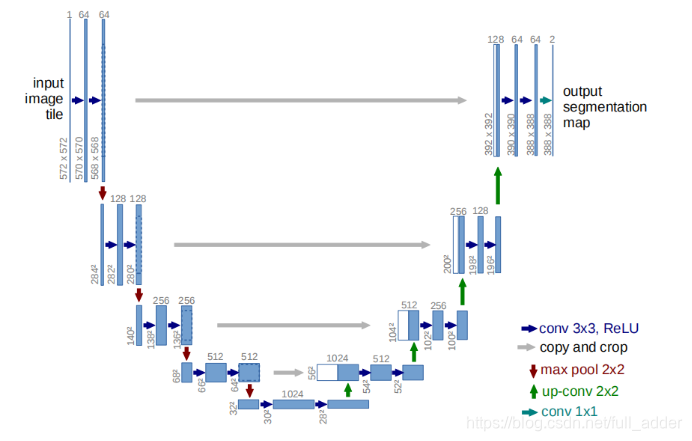
核心思想为结合浅层特征与深层特征,共进行四次下采样与四次上采样。观察网络结构图,每层上采样结果都与裁剪后的对应浅层信息拼接起来,再通过卷积后输入下次上采样。 -
Transformer【2】
网络结构如下,总之是一个全方位用注意力模块替代卷积模块的网络。具体原理见【2】,在此不赘述了。
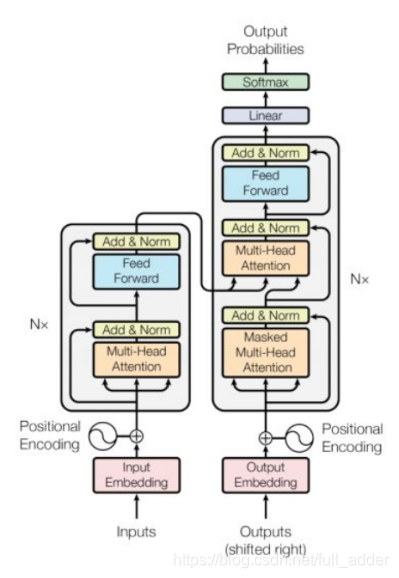
-
TransUNet【3】
故名思意,二者的结合版本,其网络结构如下:

简而言之,应当是把UNet编码器的一部分替换为了Transformer的注意力格式,其中选择了CNN-Transformer组合结构,这样不仅效果更好,也便于利用早期特征。另外将图片打包成小patch之后embeding位置这步是在CNN提取的特征图上做的,不是在原始输入上做的,总的来讲是个比较简单的部分替换式改进。
不同算法实验对比结果如下:
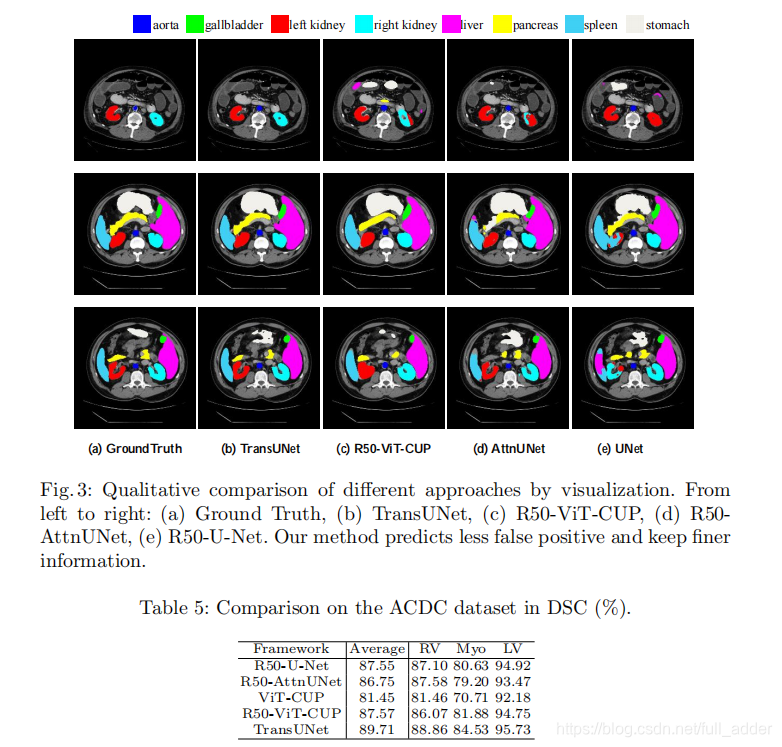
-
代码实操
数据集的预处理分为四步:转为numpy格式,在窗[-125,275]内剪切图片,归一化数据至[0,1],从三维数据中提取二维切片。但实际上只用了一步:首先通过邮件询问作者,获得了预处理后的数据集,搭建环境跑完模型之后发现,笑死,根本不会读数据,所以先去学习一下医学图像数据的构成。 -
CT数据【4】
\quad 本文选用的数据为 MICCAI 2015 多图谱腹部分割挑战赛中的30例扫描图像,具体效果如上,这个CT比想象的腹部要圆一点,左右方向也有点反直觉,又有点不反直觉。
\quad CT,其全称是Computed Tomography,即计算断层成像。 其检测机器是一个旋转的圆筒形,人躺在里面,机器旋转,获得立体图像。具体原理见参考【4】。在这里进行原理了解主要是因为,不清楚数据结构那147通道是哪来的(狒狒挠头.jpg)。这里需要注意的是,CT图像的信息非常多,采样很密,可能有多达两千的CT值数,如果单纯压到0-256会造成很大损失,因此通常会按照特定“窗位,窗宽”输出结果,窗宽指的是CT值上下限的差值,窗位指的是中心灰度对应的CT值。
\quad -
.npz数据【5】
训练中使用的数据,为切片后的结果,npz大概具体为npy文件的压缩版本,其可通过以下代码进行显示:
path="E:/fenge\TransUNet-main\project_TransUNet\project_TransUNet\data\Synapse/train_npz/case0005_slice050.npz"
data=np.load(path)
x_train=data["image"]*255
la_train=data["label"]*255
plt.subplot(121)
plt.imshow(x_train)
plt.subplot(122)
plt.imshow(la_train)
plt.show()
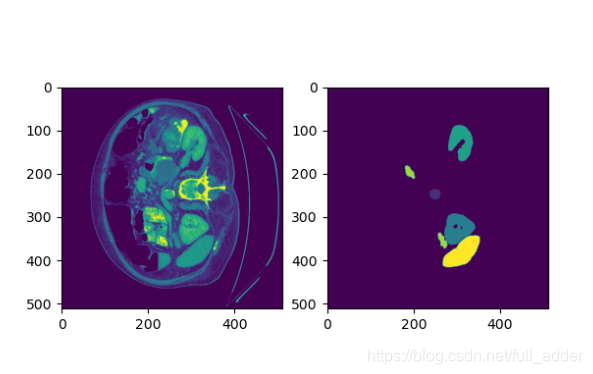
经过显示观察,数据的多通道代表的应当是三维z坐标,在头尾上没有脏器,标签就是一片黑暗的。
- .h5数据【6】
测试使用的完整数据,h5具体为层级结构,可通过以下代码进行显示:
import h5py
import matplotlib.pyplot as plt
import numpy as np
with h5py.File('E:/fenge\TransUNet-main\project_TransUNet\project_TransUNet\data\Synapse/test_vol_h5/case0001.npy.h5',"r") as f:
for key in f.keys():
#print(f[key], key, f[key].name, f[key].value) # 因为这里有group对象它是没有value属性的,故会异常。另外字符串读出来是字节流,需要解码成字符串。
print(f[key], key, f[key].name) # f[key] means a dataset or a group object. f[key].value visits dataset' value,except group object.
f=h5py.File('E:/fenge\TransUNet-main\project_TransUNet\project_TransUNet\data\Synapse/test_vol_h5/case0001.npy.h5',"r")
imagedata=f['image']
labeldata=f['label']
i=100
imgsel=np.array(imagedata)[i,:,:]
labelsel=np.array(labeldata)[i,:,:]
plt.subplot(121)
plt.imshow(imgsel)
plt.subplot(122)
plt.imshow(labelsel)
plt.show()
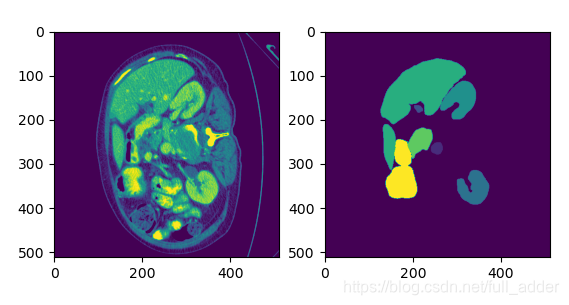
依据以上代码测试,数据结构就很清晰明了了。
- 评价指标
Mean_Dice,具体公式为2*交集/并集,详细描述见【7】 - 测试与可视化
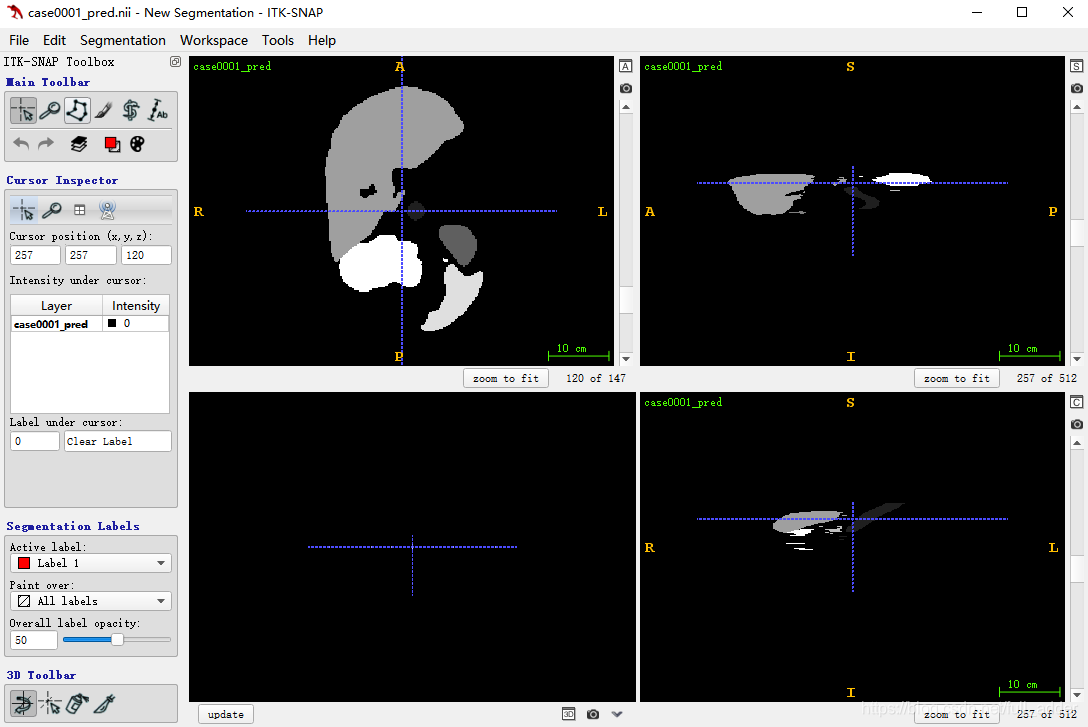
通过将 is_savenii手动置1保存了测试的结果图,下载了软件ITK-SNAP进行可视化[不过这个软件不能读h5和.npz文件],效果如下:
参考
【1】https://zhuanlan.zhihu.com/p/57859749
【2】https://zhuanlan.zhihu.com/p/44121378
【3】https://blog.csdn.net/weixin_40096160/article/details/114194562
【4】https://zhuanlan.zhihu.com/p/90571757
【5】https://blog.csdn.net/xiongchengluo1129/article/details/83051390
【6】https://zhuanlan.zhihu.com/p/361565432
【7】https://blog.csdn.net/qq_36201400/article/details/109180060
【8】https://blog.csdn.net/qq_33254870/article/details/100125788


















 3570
3570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









