







背景
在笔者应用大模型的场景中,对话模型(即大模型-chat系列)通常具有比较重要的地位,我们通常基于与大模型进行对话来获取我们希望理解的知识。然而大模型对话是依据何种数据格式来进行训练的,他们的数据为什么这么来进行组织,本篇文章将进行总结。
Chat Markup Language
Chat Markup Language (CML) 是一种用于描述对话结构的标记语言。它可以帮助大模型和 AI 助手之间的对话更加结构化和清晰。CML 可以描述对话中的各种元素,例如对话的开始和结束、用户和 AI 助手的发言、对话中的问题和回答等等。使用 CML 可以使得对话的处理更加方便和高效,同时也可以提高对话的可读性和可维护性。
DeepMind的相关研究指出,相关研究指出,LLM可以通过选取合适的prompt)来转化为对话代理。这些文本提示通常包含一种所谓的“系统”信息来定义 LLM 的角色,以及一系列人机对话的示例。
对数话数据格式
一种简单对话数据的构建格式是,单纯的把系统信息和角色信息插入到每一个训练样本中,然后在对话用"序列结尾"的token(如)分隔开。如下所示:
Below is a dialogue between a human and AI assistant ...
Human: Is it possible to imagine a society without law?
Assistant: It is difficult to imagine ...
Human: It seems like you ...
Assistant: You are correct ...
Human: Yeah, but laws are complicated ..
<EOS>
这种简单对话数据构建方法可能会导致对话推理过程中生成不必要的对话轮次,因此需要进行改进。一种更好的结构化方法是ChatML,它对每个对话轮次进行包装,并使用预定义的特殊Token来表示询问或回答的角色。这种方法可以更好地区分对话中不同角色的发言,并且可以更准确地捕捉对话的语境和上下文。相比于简单的插入系统信息和角色信息的方法,ChatML更加灵活和可扩展,可以适应不同类型的对话场景和任务。
ChatGPT的ChatML
根据OpenAI ChatML V0将每个角色(system,user,assistant)的文本按照如下进行拼接:
<|im_start|>system
You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.
Knowledge cutoff: 2021-09-01
Current date: 2023-03-01<|im_end|>
<|im_start|>user
How are you<|im_end|>
<|im_start|>assistant
I am doing well!<|im_end|>
<|im_start|>user
How are you now?<|im_end|>
其中<|im_start|>、<|im_end|>是special token,进行tokenizer encode的时候他们会被编码成对应的单个token id,他们专门用来表示一个角色说话的start和end。
千问-chat版本也是用的这种数据构建方法。https://arxiv.org/pdf/2309.16609.pdf

另一种的ChatML
我们使用一些特殊的标记来表示不同的信息类型:
- <|system|>:表示系统信息的开始,用于描述聊天机器人的身份和角色。
- <|user|>:表示用户说出的话语。
- <|assistant|>:表示机器人说出的话语。
- <|end|>:表示话语或系统信息的结尾。
案例
对话数据:
sample={
"messages": [
{
"content": "Is it possible to imagine a society without law?",
"role": "user",
},
{
"content": "It is difficult to imagine a society that is able to be maintained without any semblance of Law. Laws exists for the purpose of maintaining society and past human behavior suggests that there would people that have no interest in promoting social cohesion and norms so it's unlikely that complex social and economic systems could develop without a legal system.",
"role": "assistant",
},
{
"content": 'It seems like you consider the absence of law equal to the absence of anything that could guide the behaviour of the individual, however there are many other such things, like religion, conscience, tradition to mention few important patterns which are known to have crucial influence on society even today, but also we could imagine more, like universal love if everyone suddenly became "awaken" in some spiritual sense, or simply just having an omnipotent leader who maintains a certain order without ever codifying the principles in law. Is it still difficult to imagine?',
"role": "user",
},
{
"content": "You are correct that there are other factors that can guide behavior in a society and play a role in shaping individuals' behavior and interactions with each other. However, even in societies where these factors are present, laws still serve an important role in maintaining social order and resolving conflicts. \n\nFor example, religious teachings may prohibit theft and murder, but laws provide a system of justice for those who violate these prohibitions. Personal morality and conscience may guide individuals to act in a certain way, but laws provide a framework for resolving disputes when conflicting moral beliefs arise. Furthermore, the other factors you mentioned, such as universal love or an omnipotent leader, are not necessarily stable or reliable guides for behavior. Universal love, while a noble ideal, may not be achievable in practice, and an omnipotent leader may be prone to corruption or abuse of power.\n\nLaws provide a crucial foundation for maintaining social order and ensuring justice. It is possible to imagine alternative systems of governance, but it is unlikely that a society without any sort of legal framework would be stable or functional in the long term.",
"role": "assistant",
},
{
"content": "Yeah, but laws are complicated. Most people can't understand them in depth. Some would argue it is almost a self-serving system which put energy into growing itself(eg.: patent trolling). I think there must be a less complex system which keeps up order in society.",
"role": "user",
},
]
}
chatGPT chatGLM封装
im_start= "<|im_start|>"
im_end= "<|im_end|>"
def prepare_dialogue(example):
system_msg = "Below is a dialogue between a human and an AI assistant called StarChat."
prompt = im_start + "system\n" + system_msg + im_end+ "\n"
for message in example["messages"]:
if message["role"] == "user":
prompt += im_start+ "user\n" + message["content"] + im_end + "\n"
else:
prompt += im_start+ "assistant\n" + message["content"] + im_end + "\n"
return prompt
print(prepare_dialogue(sample))

另一种 chatGLM封装
system_token = "<|assistant|>"
user_token = "<|user|>"
assistant_token = "<|assistant|>"
end_token = "<|end|>"
def prepare_dialogue(example):
system_msg = "Below is a dialogue between a human and an AI assistant called StarChat."
prompt = system_token + "\n" + system_msg + end_token + "\n"
for message in example["messages"]:
if message["role"] == "user":
prompt += user_token + "\n" + message["content"] + end_token + "\n"
else:
prompt += assistant_token + "\n" + message["content"] + end_token + "\n"
return prompt
print(prepare_dialogue(sample))

将特殊字符添加到tokenizer中
openAI版本
tokenizer.add_special_tokens({"additional_special_tokens": ["<|im_start|>", "<|im_end|>"]})
print(tokenizer.additional_special_tokens)
tokenizer("<|im_start|>")
另一种版本
tokenizer.add_special_tokens({"additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"]})
可见特殊字符被封装到单独一个 token 的 ID中

构建标签
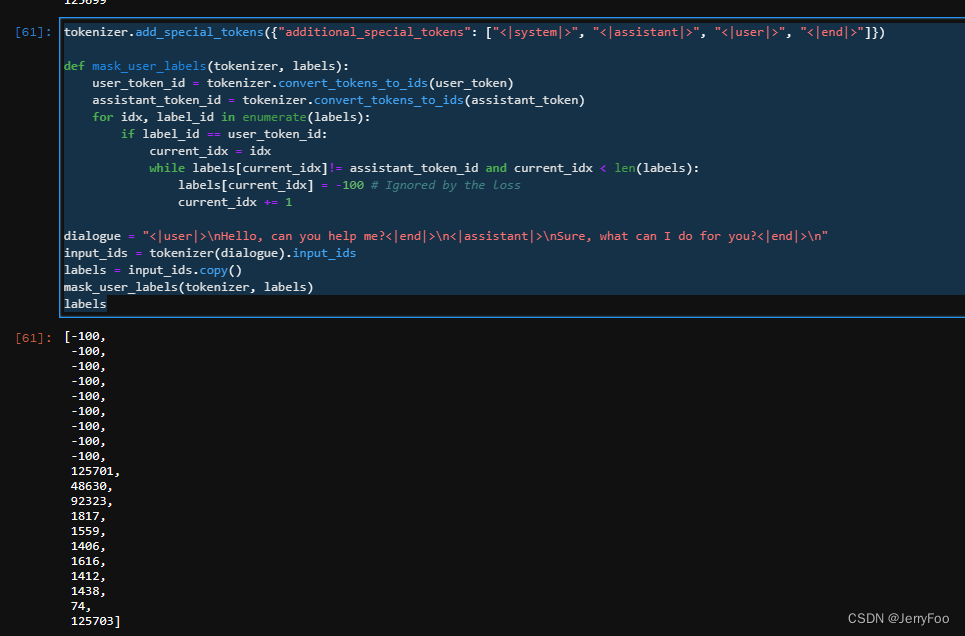
我们可以遮盖掉来自用户话语部分的损失函数值。因为我们的模型是基于用户的话语进行训练的,只被训练去预测 AI 助手说话的部分(在模型推理时,只需要根据用户的话回答用户)。下面是一个简单的函数,用于遮盖掉用户部分的标签,并将所有用户部分的令牌转换为-100(接下来,-100将被损失函数忽略)。
tokenizer.add_special_tokens({"additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"]})
def mask_user_labels(tokenizer, labels):
user_token_id = tokenizer.convert_tokens_to_ids(user_token)
assistant_token_id = tokenizer.convert_tokens_to_ids(assistant_token)
for idx, label_id in enumerate(labels):
if label_id == user_token_id:
current_idx = idx
while labels[current_idx]!= assistant_token_id and current_idx < len(labels):
labels[current_idx] = -100 # Ignored by the loss
current_idx += 1
dialogue = "<|user|>\nHello, can you help me?<|end|>\n<|assistant|>\nSure, what can I do for you?<|end|>\n"
input_ids = tokenizer(dialogue).input_ids
labels = input_ids.copy()
mask_user_labels(tokenizer, labels)
labels
tokenizer.add_special_tokens({"additional_special_tokens": ["<|im_start|>", "<|im_end|>"]})
def mask_user_labels(tokenizer, labels):
im_start_id = tokenizer.convert_tokens_to_ids("<|im_start|>")
im_end_id = tokenizer.convert_tokens_to_ids("<|im_end|>")
user_id = tokenizer.convert_tokens_to_ids("user")
assitant_id = tokenizer.convert_tokens_to_ids("assitant")
for idx, label_id in enumerate(labels):
if label_id == im_start_id:
if idx < len(labels):
if labels[idx+1] == user_id:
current_idx = idx
while labels[current_idx+1]!= im_start_id:
labels[current_idx] = -100 # Ignored by the loss
labels[current_idx+1] = -100 # Ignored by the loss
current_idx += 1
dialogue = "<|im_start|>user\nHello, can you help me?<|im_end|>\n<|im_start|>assistant\nSure, what can I do for you?<|im_end|>\n"
input_ids = tokenizer(dialogue).input_ids
labels = input_ids.copy()
mask_user_labels(tokenizer, labels)
labels
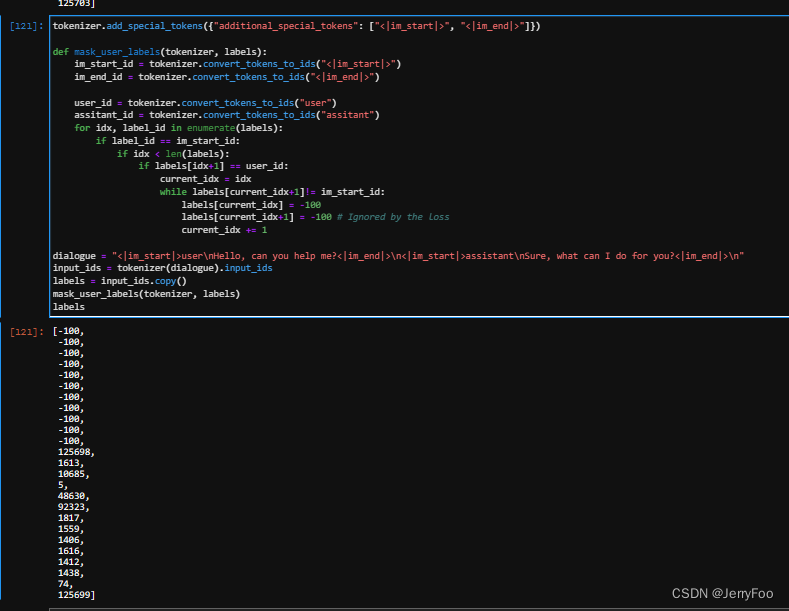
所有用户输入的ID都被遮蔽了。在微调阶段,这些特殊的标记将学习到它们自己特定的嵌入。

















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









