







什么是机器学习
岭回归(Ridge Regression)是一种线性回归的扩展,它通过在损失函数中添加正则化项(L2范数)来解决线性回归中可能存在的过拟合问题。正则化项有助于限制模型的参数,使其不过分依赖于训练数据,从而提高模型的泛化能力。
岭回归的目标函数可以表示为:
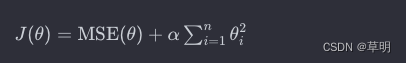
其中:
J(θ)是岭回归的目标函数MSE(θ)是均方误差(Mean Squared Error)α是正则化参数θ1, θ2, ... , θn是模型的参数
训练岭回归模型的过程是通过最小化目标函数找到最适合数据的参数。正则化项对模型的参数进行惩罚,使得参数趋向于较小的值,从而减小模型对训练数据的过拟合程度。
代码示例(使用 Python 和 scikit-learn)
以下是一个使用 scikit-learn 库进行岭回归的简单示例:
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import numpy as np
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 创建岭回归模型
ridge_model = Pipeline([
('scaler', StandardScaler()), # 特征标准化
('ridge', Ridge(alpha=1, solver='cholesky')) # 岭回归模型
])
# 拟合模型
ridge_model.fit(X, y)
# 预测新数据
X_new = np.array([[1.5]])
y_pred = ridge_model.predict(X_new)
print("预测结果:", y_pred[0][0])
# 绘制散点图和拟合的直线
plt.scatter(X, y, color='blue')
plt.plot(X, ridge_model.predict(X), color='red', linewidth=3)
plt.xlabel("自变量")
plt.ylabel("因变量")
plt.title("岭回归")
plt.show()
在这个例子中,我们使用了 scikit-learn 的 Ridge 类来构建岭回归模型。模型中的 alpha 参数表示正则化强度,你可以根据实际问题调整这个参数。模型还包括一个 StandardScaler,用于对输入特征进行标准化。这是因为在岭回归中,正则化项对参数的惩罚是基于特征的尺度计算的,因此标准化可以确保各个特征的尺度一致。














 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









