这部分主要是通过对第一部分中提到的匀加速小车模型进行位移预测。
先来看看状态方程能建立准确的时候,状态方程见第一部分分割线以后内容,小车做匀加速运动的位移的预测仿真如下。
- clc
- clear all
- close all
-
- % 初始化参数
- delta_t=0.1; %采样时间
- t=0:delta_t:5;
- N = length(t); % 序列的长度
- sz = [2,N]; % 信号需开辟的内存空间大小 2行*N列 2:为状态向量的维数n
- g=10; %加速度值
- x=1/2*g*t.^2; %实际真实位置
- z = x + sqrt(10).*randn(1,N); % 测量时加入测量白噪声
-
- Q =[0 0;0 9e-1]; %假设建立的模型 噪声方差叠加在速度上 大小为n*n方阵 n=状态向量的维数
- R = 10; % 位置测量方差估计,可以改变它来看不同效果 m*m m=z(i)的维数
-
- A=[1 delta_t;0 1]; % n*n
- B=[1/2*delta_t^2;delta_t];
- H=[1,0]; % m*n
-
- n=size(Q); %n为一个1*2的向量 Q为方阵
- m=size(R);
-
- % 分配空间
- xhat=zeros(sz); % x的后验估计
- P=zeros(n); % 后验方差估计 n*n
- xhatminus=zeros(sz); % x的先验估计
- Pminus=zeros(n); % n*n
- K=zeros(n(1),m(1)); % Kalman增益 n*m
- I=eye(n);
-
- % 估计的初始值都为默认的0,即P=[0 0;0 0],xhat=0
- for k = 9:N %假设车子已经运动9个delta_T了,我们才开始估计
- % 时间更新过程
- xhatminus(:,k) = A*xhat(:,k-1)+B*g;
- Pminus= A*P*A'+Q;
-
- % 测量更新过程
- K = Pminus*H'*inv( H*Pminus*H'+R );
- xhat(:,k) = xhatminus(:,k)+K*(z(k)-H*xhatminus(:,k));
- P = (I-K*H)*Pminus;
- end
-
- figure
- plot(t,z);
- hold on
- plot(t,xhat(1,:),'r-')
- plot(t,x(1,:),'g-');
- legend('含有噪声的测量', '后验估计', '真值');
- xlabel('Iteration');
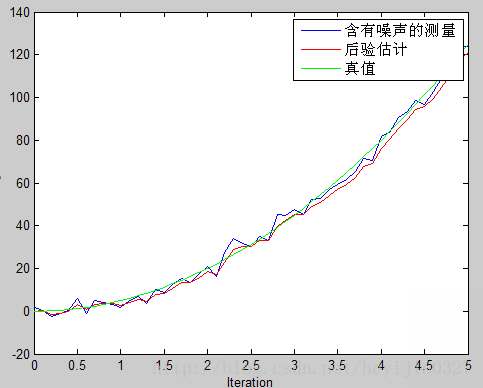
得到的仿真图像:
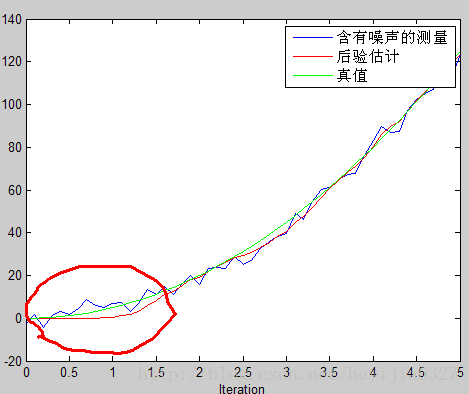
绿线为真实值,蓝色的为噪声很大的测量值,红线为估计值。由此可以看出卡尔曼滤波确实相当犀利,提供了一个顺滑的最优的估计。并请注意代码中,特地使得估计是从第9个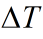 才开始预测,就像雷达跟踪一样,假设一开始我们没有发现这个东西,它已经运行了一段时间,我们在雷达测量和自己预测后得到估计结果,从图中可看出效果确实很好。
才开始预测,就像雷达跟踪一样,假设一开始我们没有发现这个东西,它已经运行了一段时间,我们在雷达测量和自己预测后得到估计结果,从图中可看出效果确实很好。
但这里请注意图像中画红圈部分,由于一开始你预测值为0,而实际上不是(它已经运动9个时间间隔了),所以估计出的效果不好。在这里回忆前面讨论过的K值大小和估计的关系,既然预测不准,那么一开始我就先相信测量呗。这就涉及估计值误差协方差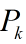 初值的选取。在第一部分中我们知道卡尔曼增益K与预测误差协方差矩阵正相关,由第一部分推导知道预测误差协方差阵
初值的选取。在第一部分中我们知道卡尔曼增益K与预测误差协方差矩阵正相关,由第一部分推导知道预测误差协方差阵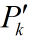 :
:
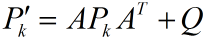
它又和估计误差协方差矩阵有关,在Q,A确定的情况下,和成正比。所以如果我们给的初值大的话,那么递推第一步中计算出的卡尔曼增益K就大。K大意味着更相信测量值。
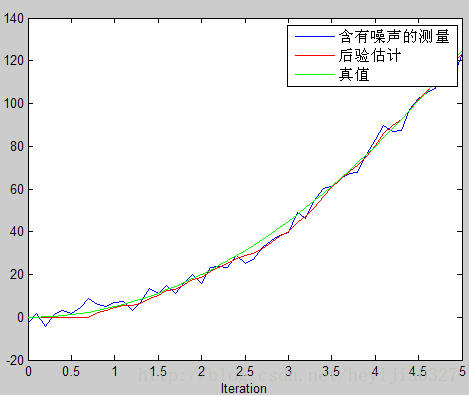
修改初值P=[2 0;0 2],估计图像如下,可以看到初始估计明显改进了。(两幅图中,测量值相同,只改变了P)。这幅图中红色水平线那部分是前9个时间段,你还没开始雷达追踪,所以是水平的为0。
好了,到第二个问题,当状态方程建立不正确的又会怎样呢?实际应用中很多时候我们不能建立正确的状态方程。
我们假设建立的状态方程如下:
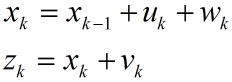
转换矩阵A,B,H都等于1.这个模型明显是不正确的。
注意这个时候的系统噪声,就不单单只是系统内部产生的,还包括你建立状态方程的不正确性。你建立的越不正确,根据你模型进行的预测就不正确,从这个角度来说,相当于你的噪声增大了。所以这个时候系统噪声W的方差应该增大。理解这一点,对改进实际估计效果有好处。接下来通过对比不同的W方差值设定给出对比,贴出这部分仿真如下。
- clc
- clear
- close all
-
- % 初始化参数
- delta_t=0.1;
- t=0:delta_t:5;
- g=10;%加速度值
- n_iter = length(t); % 序列的长度
- sz = [n_iter, 1]; % 信号需开辟的内存空间大小
- x=1/2*g*t.^2;
- x=x';
- z = x + sqrt(10).*randn(sz); % 测量时加入测量白噪声
-
- Q = 0.9; % 过程激励噪声方差
- %注意Q值得改变 待会增大到2,看看效果。对比看效果时,修改代码不要改变z的值
- R = 10; % 测量方差估计,可以改变它来看不同效果
-
- % 分配空间
- xhat=zeros(sz); % x的后验估计
- P=zeros(sz); % 后验方差估计
- xhatminus=zeros(sz); % x的先验估计
- Pminus=zeros(sz); % 先验方差估计
- K=zeros(sz); % Kalman增益
-
- % 估计的初始值
- xhat(1) = 0.0;
- P = 1.0;
- for k = 2:n_iter %
- % 时间更新过程
- xhatminus(k) = xhat(k-1);
- Pminus(k) = P(k-1)+Q;
-
- % 测量更新过程
- K(k) = Pminus(k)/( Pminus(k)+R );
- xhat(k) = xhatminus(k)+K(k)*(z(k)-xhatminus(k));
- P(k) = (1-K(k))*Pminus(k);
- end
-
- figure
- plot(t,z);
- hold on
- plot(t,xhat,'r-')
- plot(t,x,'g-');
- legend('含有噪声的测量', '后验估计', '真值');
- xlabel('Iteration');
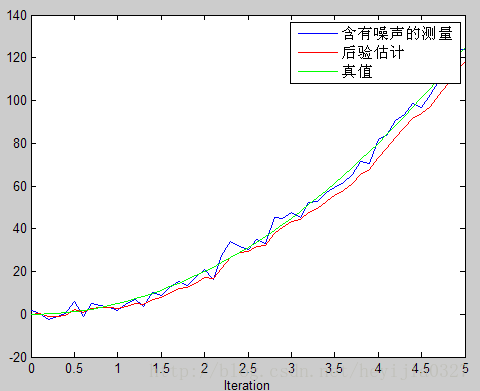
最开始假设系统噪声方差和前面状态建立正确的时候一样为0.9,估计图像如图(a)。效果不理想,我们知道状态方程建立错误了,系统噪声方差应该比之前大。于是增大系统噪声方差再预测,如图(b)
图(a)
图(b)
两个图中测量值是一样的,只是第二图中将系统噪声方差Q增大到2。对比可以看出,特别是图像后半段,图(b)比图(a)效果更接近真实值。
至此,从推导到应用接近尾声了,但我在这里还有一个问题就是,你随便给的x的预测初值,模型建立也不正确,kalman filter 竟然依然这么犀利,那么他收敛性怎么证明呢?写这文章的时候,笔者没有看详细的数学证明,但是由前面说到的kalman filter和数值分析里递推求解方程组时用的Gauss-Seidel 迭代法,两者真的很相近,于是我直观的认为卡尔曼的收敛性和Gauss-Seidel 一样。Gauss-Seidel迭代法里权重的选取能使得递推收敛真实值,因此卡尔曼滤波里增益K的每次计算就是卡尔曼收敛的重要保证。
最后再说一句个人可能不正确观点,抛砖迎玉,卡尔曼滤波最后收敛得到的方程就是维纳滤波,卡尔曼滤波是一步一步递推然后收敛到真实值,维纳滤波是直接计算出估计值,不是一步一步的结果,但两者都是最小均方差的思想在里面。因此,我在学卡尔曼的时候,想到数字图像里的维纳滤波,直观的想到,维纳滤波能做到的,卡尔曼应该也能做到。但这我也没去验证,倒是确实有这方面的论文。
转自:白巧克力亦唯心 http://blog.csdn.net/heyijia0327























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









