







1. 正则化的目的:防止过拟合!
2. 正则化的本质:约束(限制)要优化的参数。
关于第1点,过拟合指的是给定一堆数据,这堆数据带有噪声,利用模型去拟合这堆数据,可能会把噪声数据也给拟合了,这点很致命,一方面会造成模型比较复杂(想想看,本来一次函数能够拟合的数据,现在由于数据带有噪声,导致要用五次函数来拟合,多复杂!),另一方面,模型的泛化性能太差了(本来是一次函数生成的数据,结果由于噪声的干扰,得到的模型是五次的),遇到了新的数据让你测试,你所得到的过拟合的模型,正确率是很差的。
关于第2点,本来解空间是全部区域,但通过正则化添加了一些约束,使得解空间变小了,甚至在个别正则化方式下,解变得稀疏了。这一点不得不提到一个图,相信我们都经常看到这个图,但貌似还没有一个特别清晰的解释,这里我尝试解释一下,图如下:
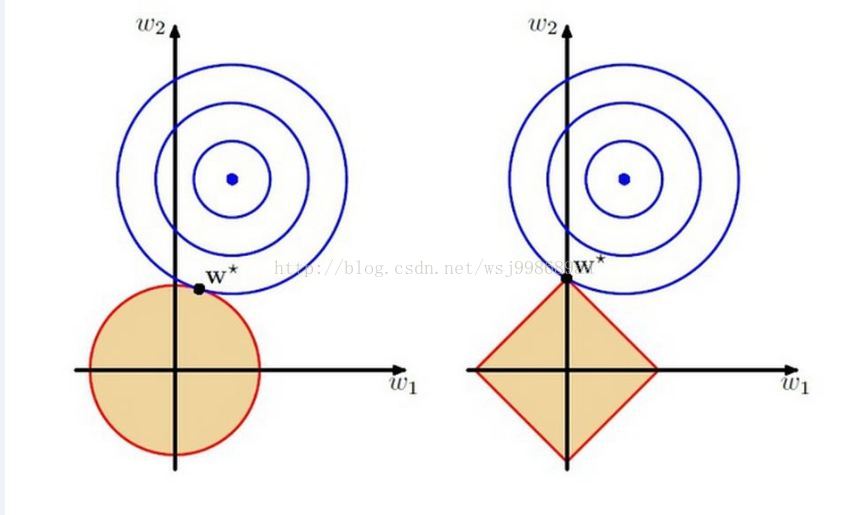
这里的w1,w2都是模型的参数,要优化的目标参数,那个红色边框包含的区域,其实就是解空间,正如上面所说,这个时候,解空间“缩小了”,你只能在这个缩小了的空间中,寻找使得目标函数最小的w1,w2。左边图的解空间是圆的,是由于采用了L2范数正则化项的缘故,右边的是个四边形,是由于采用了L1范数作为正则化项的缘故,大家可以在纸上画画,L2构成的区域一定是个圆,L1构成的区域一定是个四边形。
再看看那蓝色的圆圈,再次提醒大家,这个坐标轴和特征(数据)没关系,它完全是参数的坐标系,每一个圆圈上,可以取无数个w1,w2,这些w1,w2有个共同的特点,用它们计算的目标函数值是相等的!那个蓝色的圆心,就是实际最优参数,但是由于我们对解空间做了限制,所以最优解只能在“缩小的”解空间中产生。
蓝色的圈圈一圈又一圈,代表着参数w1,w2在不停的变化,并且是在解空间中进行变化(这点注意,图上面没有画出来,估计画出来就不好看了),直到脱离了解空间,也就得到了图上面的那个w*,这便是目标函数的最优参数。
对比一下左右两幅图的w*,我们明显可以发现,右图的w*的w1分量是0,有没有感受到一丝丝凉意?稀疏解诞生了!是的,这就是我们想要的稀疏解,我们想要的简单模型。
还记得模式识别中的剃刀原理不?倾向于简单的模型来处理问题,避免采用复杂的。
这里必须要强调的是,这两幅图只是一个例子而已,没有说采用L1范数就一定能够得到稀疏解,完全有可能蓝色的圈圈和四边形(右图)的一边相交,得到的就不是稀疏解了,这要看蓝色圈圈的圆心在哪里。
此外,正则化其实和“带约束的目标函数”是等价的,二者可以互相转换。关于这一点,我试着给出公式进行解释:
针对上图(左图),可以建立数学模型如下:
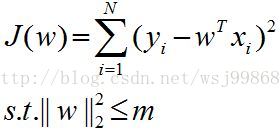
通过熟悉的拉格朗日乘子法(注意这个方法的名字),可以变为如下形式:
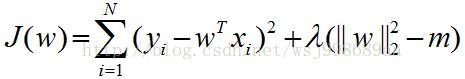
看到没,这两个等价公式说明了,正则化的本质就是,给优化参数一定约束,所以,正则化与加限制约束,只是变换了一个样子而已。
此外,我们注意,正则化因子,也就是里面的那个lamda,如果它变大了,说明目标函数的作用变小了,正则化项的作用变大了,对参数的限制能力加强了,这会使得参数的变化不那么剧烈(仅对如上数学模型),直接的好处就是避免模型过拟合。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









