





最近几年中,深度模型在推荐领域里的预测任务上取得的令人满意的成果。但大部分工作的焦点放在的模型,只有有限的少数工作注意到了输入的特征,但实际上特征决定了模型效果的上限。本文的工作也关注到了特征层面,特别是商业推荐系统中的特征。
为了确保离线训练和在线服务的一致性,现实的应用中我们通常采用两个环境下都可以获取的特征。只有训练期间才能获取到的一批具有识别能力的特征因此被忽略。以电商推荐中的转化率预测为例,我们的目标是预测用户点击商品之后购买的概率。描述点击后详情页内用户行为的特征可能非常有用。但是线上转化率预测中却无法使用这些特征。因为购买动作之前,无法获取到这些特征。这些后事件特征可以被记录用于离线训练。这里我们将训练阶段才能获取到的对于预测任务具有区分度的特征称为特权特征。
采用特权特征比较直接的方式是多任务学习,比如通过额外的任务预测特权特征。但是多任务学习中,新增的任务可能会伤害原有模型的学习。更重要的是,特权特征的学习可能比原始问题更具有挑战性。从实际的角度出发,当采用数十个特权特征时,精调如果多任务的学习非常具有挑战性。
受到LUPI(特权信息学习)的启发,我们提出特权特征蒸馏(PFD)。我们训练两个模型,一个学生模型和一个导师模型。学习模型与普通模型没有区别,采用线下训练和线上预测都可获得的特征。导师模型采用所有的特征,包括只有线下训练才可获得的特权特征。导师模型蒸馏得到的知识,譬如本文中采用的软标签,用于监督学生模型的训练,提升学生模型的效果。线上预测时,抽取只采用了普通特征的学生模型,保证训练和预测时的一致性。与多任务学习相比,特征蒸馏主要有两大优点。首先,组合特权特征的方式更加恰当,通常添加更多的特权特征将提高预测的准确性。其次,特征蒸馏只额外引入了蒸馏损失,与特权特征的数量无关,方便精细调参。
特征蒸馏与通常使用的模型蒸馏有所区别。模型蒸馏中导师与学生模型处理的输入完全一致,但导师模型比学生模型的表达能力更强。比如导师模型采用深度网络,知道浅层网络的学生模型。然而在特征蒸馏中,导师和学生采用的模型一样,但是输入有所差别。特征蒸馏与LUPI也有区别,特征蒸馏中导师模型需要额外处理普通特征。图1说明了主要的区别。
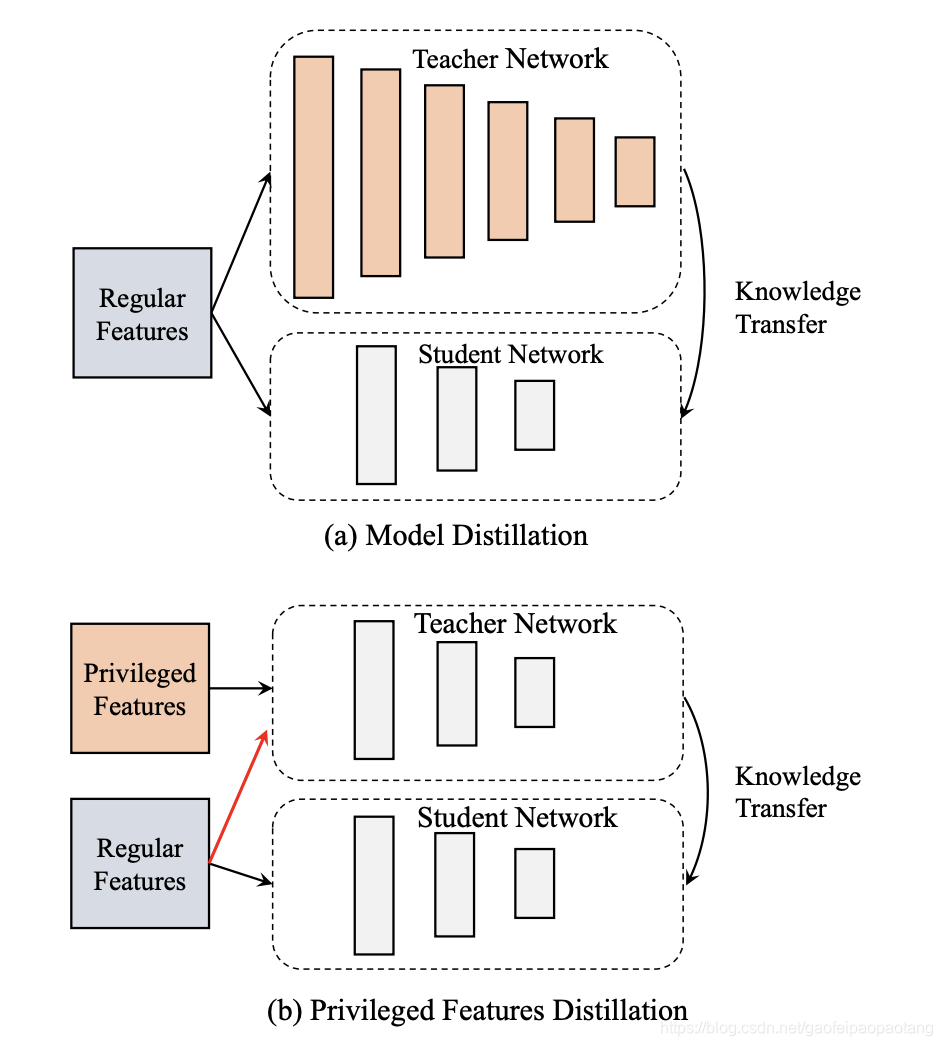
图1:模型蒸馏与特权特征蒸馏的图解。模型蒸馏中,知识来自于更复杂的模型。特征蒸馏中,知识来自于特权特征和普通特征。特征蒸馏同样也区别于LUPI,LUPI中导师模型只处理特权特征。
本文的主要贡献有四点:
- 我们指出淘宝推荐中特权特征的存在,并提出特征蒸馏利用特权特征。相比于多任务学习需要预测每一个特权特征,特征蒸馏整合了所有特权特征,并提供一站式解决方案。
- 与LUPI相比,特征蒸馏中的导师模型增加了普通的特征,更好的指导学习模型。特征蒸馏是对模型蒸馏的补充,二者相结合,可以取得进一步的提升。
- 通过共享输入部分,我们同时训练导师和学生模型。相比于分开独立训练,这种训练方式取得一样或更好的效果,并且时间消耗大大减少。因此这种方式可用于在线学习(对实时性要求比较高)
- 我们在淘宝做了两个实验,粗排阶段的CTR预测和精排阶段的CVR预测。通过蒸馏CTR预测中的因性能问题而未被采用的交互特征,以及CVR预测中上文介绍的后事件类特征,相对基线取得了显著的提升。根据线上的AB测试,点击预测任务中点击指标提升了5.0%,转化预测任务中转化指标提升了2.3%。
详细介绍特征蒸馏之前,我么首先介绍蒸馏技术。整体而言,蒸馏的目标是帮助非凸学生模型更好的训练。对于模型蒸馏,我们可以将目标函数归纳如下形式:
m i n W s ( 1 − λ ) ∗ L s ( y , f s ( X ; W s ) ) + λ ∗ L d ( f t ( X ; W t ) , f s ( X ; W s ) ) min_{\bold{W}_s}(1-\lambda)*L_s(\bold{y}, f_s(\bold{X};\bold{W}_s)) + \lambda * L_d(f_t(\bold{X};\bold{W}_t), f_s(\bold{X};\bold{W}_s)) minWs(1−λ)∗Ls(y,fs(X;Ws))+λ∗Ld(ft(X;Wt),fs(X;Ws))
其中 f t , f s f_t,f_s ft,fs分别表示导师模型和学生模型。 L s L_s Ls表示学生模型关于“硬”标签的损失, L d L_d Ld表示学生模型关于蒸馏得到的“软”标签的损失。 λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ∈[0,1]是超参,权衡以上两个损失值。相比仅包含 L s L_s Ls项的原始损失函数,我们期望 L d L_d Ld通过导师模型蒸馏所得的知识将帮助更好的训练学生模型。【30】将蒸馏损失项视为正则化,仅通过最小化 L s L_s Ls训练 f s f_s fs,训练过程倾向于过拟合训练集。增加蒸馏损失项, f s f_s fs将额外拟合导师模型 f t f_t ft生产的“软”标签。通过软化输出, f s f_s fs更有可能达到更好的泛化效果。
通常导师模型相比学生模型表达能力更强。导师模型可能是多个模型的组合,或则相比学些模型包含更多的神经元、或更多网络层,甚至是更高的数值精确度。也有一些例外,【1】中两个模型采用了完全一样的结构,互相学习,区别在于初始化方式和处理训练数据 的顺序。
上述损失函数中导师模型的参数 W s \bold{W}_s Ws在训练过程中保持不变。一般我们可以将蒸馏技术分为两步:首先采用已知标签 y \bold{y} y训练导师模型,然后训练学习模型。在一些应用中,模型需要较长的时间才会收敛,等待导师模型完全收敛不太可行,因此有些工作尝试同时训练导师和学生模型。除了可以从最终输出进行蒸馏,还可以从中间层进行蒸馏。譬如【31】尝试了蒸馏中间特征映射,帮助训练更深或更浅的网络。
除了从更复杂的模型中蒸馏知识,【25】提出了从特权信息 X ∗ \bold{X}^* X∗中蒸馏知识,称之为LUPI。对应的损失函数为:
m i n W s ( 1 − λ ) ∗ L s ( y , f s ( X ; W s ) ) + λ ∗ L d ( f t ( X ∗ ; W t ) , f s ( X ; W s ) ) min_{\bold{W}_s}(1-\lambda)*L_s(\bold{y},f_s(\bold{X};\bold{W}_s))+\lambda*L_d(f_t(\bold{X}^*;\bold{W}_t),f_s(\bold{X};\bold{W}_s)) minWs(1−λ)∗Ls(y,fs(X;Ws))+λ∗Ld(ft(X∗;Wt),fs(X;Ws))
为了更好的理解本文中的特权特征,我们首先整体介绍一下淘宝推荐,如图2,我们采用了级联学习结构。物品展示给用户之前包含三个选择/排序阶段:生成候选集、粗排、精排。为了权衡效率和准确度,级联的三阶段越往后,模型越复杂,耗时越高。候选集生成阶段,我们从大规模的商品库中选择约 1 0 5 10^5 105个左右最可能被用户点击和购买的商品。通常候选集混合了多种来源的商品,譬如协同过滤,DNN模型,等等。候选集生成之后,我们采用了分为两个阶段的排序过程,特征蒸馏技术应用于排序阶段。

粗排阶段,我们主要估计所有候选商品的点利率,并用于选择TopK个商品进入下一阶段。预测模型的输入主要包含三个部分。第一部分由用户行为组成,记录了用户点击/购买的历史商品。用户的行为是序列数据,通常采用RNN和注意力机制建模用户的长短期兴趣。第二部分包括用户的特征,譬如用户id,年龄,性别,等等。第三部分保量商品特征,譬如商品id,类别,品牌,等等。本文中,所有的特征信息都被转换为类目特征,并为特征学习对应的embedding。
粗排阶段对预测模型的复杂度要求比较严格,为了在毫秒级时间内对数以万计的商品打分,这里我们采用内积形式的模型:
f ( X u , X i ; W u , W i ) = < ϕ W u ( X u ) , ϕ W i ( X i ) > f(\bold{X}^u,\bold{X}^i;\bold{W}^u,\bold{W}^i)=<\phi_{\bold{W}^u}(\bold{X}^u),\phi_{\bold{W}^i}(\bold{X}^i)> f(Xu,Xi;Wu,Wi)=<ϕWu(Xu),ϕWi(Xi)>
其中 X u \bold{X}^u Xu表示用户行为和用户特征的组合, ϕ W ( . ) \phi_{\bold{W}(.)} ϕW(.)表示训练参数为 W \bold{W} W的非线性隐射。 < . , . > <.,.> <.,.>表示向量内积操作。我们可以离线提前计算商品侧的隐射 ϕ W i ( ) \phi_{\bold{W}^i}() ϕWi(),线上预测时,仅需要实时计算用户侧的隐射 ϕ W u ( . ) \phi_{\bold{W}^u}(.) ϕWu(.),然后进行内积运算。这种方式非常高效。
如图2所示,粗排阶段未采用任何类似用户24小时内本类型的点击历史,24小时内本商店内的点击历史,等交互特征。正如下面实验验证的结果,添加这些特征将极大的提升预测的效果。但是也会极大的增加耗时,因为交互特征依赖用户和商品。我们将交互类特征视为粗排CTR预估任务的特权特征。
精排阶段,除了需要估计CTR,还需要估计CVR。电商推荐领域,最大化GMV是主要的目标之一,其中GMV可以分解为 C T R × C V R × P r i c e CTR \times CVR \times Price CTR×CVR×Price。显然用户在详情页的行为,譬如停留时长、是否查看评论,是否与卖家沟通,等等,对CVR的估计帮助很大。但是我们需要在未来可能的点击发生前预估CVR,这些描述用户在详情页行为的特征在预估时无法获取。因此我们将这些特征作为CVR估计任务的特权特征。
4. 特权特征蒸馏
LUPI中导师模型仅仅依赖特权信息 X ∗ \bold{X}^* X∗。本文中虽然特权信息包含丰富信息量,但仅仅部分地描述了用户的偏好。采用这些特征的模型可能不如采用普通特征的模型。此外,基于特权特征的预测可能有事会被误导。比如贵重物品的决策同城需要更多的时间,但是转化率却比较低。LUPI的导致模型将使预测依赖停留时长等特权特征,不考虑价格等普通特征。导致对贵重物品的预测失准。为了缓解此类问题,我们我们的导师模型也将考虑普通特征,我们将损失函数修改为:
m i n W s ( 1 − λ ) ∗ L s ( y , f s ( X ; W s ) ) + λ ∗ L d ( f t ( X , X ∗ ; W t ) , f s ( X ; W s ) ) min_{\bold{W}_s}(1-\lambda)*L_s(\bold{y},f_s(\bold{X;\bold{W}_s}))+\lambda*L_d(f_t(\bold{X},\bold{X}^*;\bold{W}_t), f_s(\bold{X};\bold{W}_s)) minWs(1−λ)∗Ls(y,fs(X;Ws))+λ∗Ld(ft(X,X∗;Wt),fs(X;Ws))
上述函数显示导师模型 f ( X , X ∗ ; W t ) f(\bold{X},\bold{X}^*;\bold{W}_t) f(X,X∗;Wt)需要提前训练完成。但是我们的应用中,导师模型的收敛需要较长时间,因此等待导师模型训练完成一般不可行。一个合理的方式是同时训练导师和学生模型,我们将损失函数修改为:
m i n W s , W t ( 1 − λ ) ∗ L s ( y , f s ( X ; W s ) ) + λ ∗ L d ( f t ( X , X ∗ ; W t ) , f s ( X ; W s ) ) + L t ( y , f t ( X , X ∗ ; W t ) ) min_{\bold{W}_s,\bold{W}_t}(1-\lambda)*L_s(\bold{y},f_s(\bold{X;\bold{W}_s}))+\lambda*L_d(f_t(\bold{X},\bold{X}^*;\bold{W}_t), f_s(\bold{X};\bold{W}_s)) + L_t(\bold{y},f_t(\bold{X},\bold{X}^*;\bold{W}_t)) minWs,Wt(1−λ)∗Ls(y,fs(X;Ws))+λ∗Ld(ft(X,X∗;Wt),fs(X;Ws))+Lt(y,ft(X,X∗;Wt))
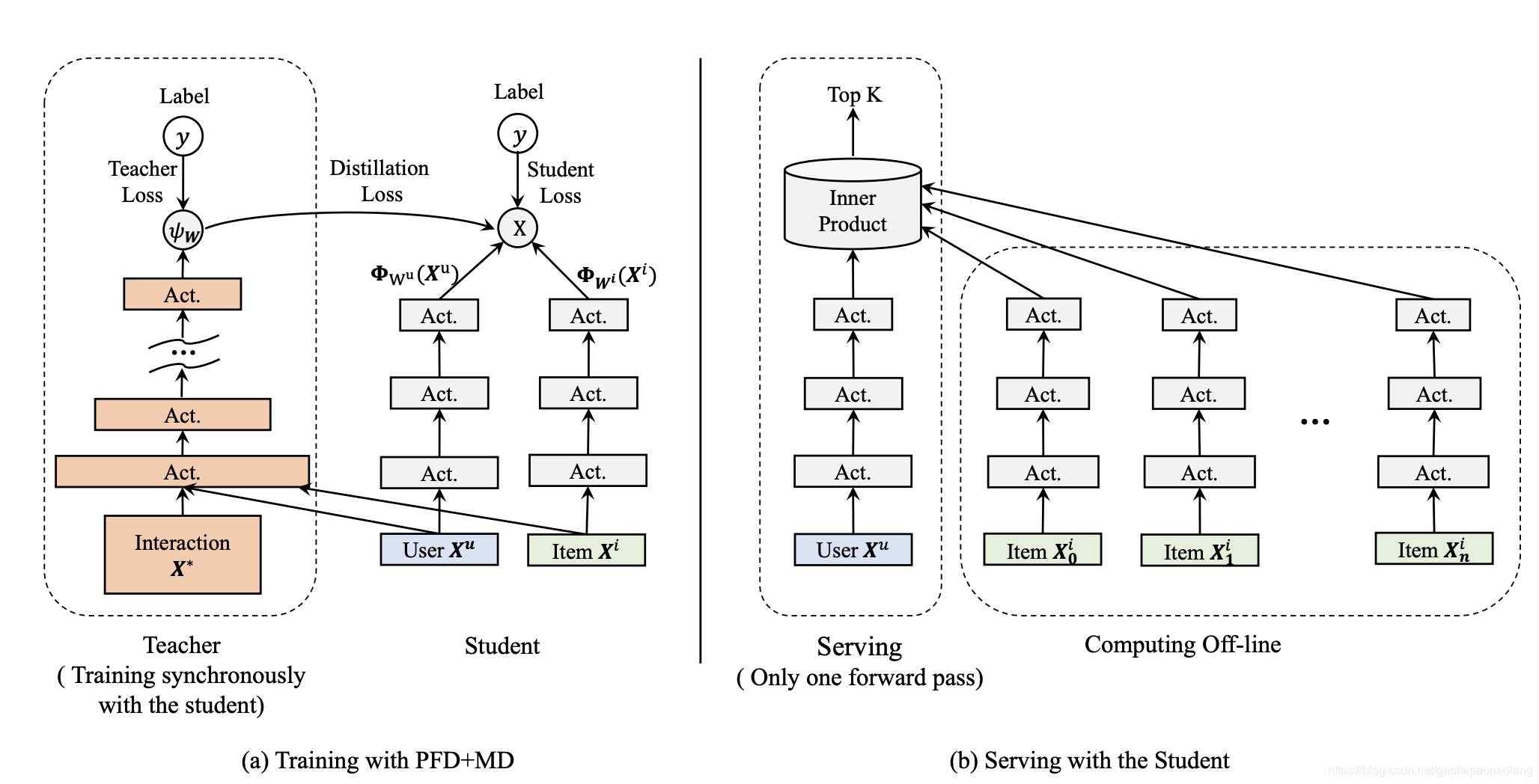
扩展:PFD+MD.如图1,PFD从特权特征中蒸馏知识,MD从更复杂的导师模型中蒸馏知识。两种蒸馏技术相互补充。一个自然的扩展方式是将二则结合,构造一个更准确的导师模型指导学生模型。

















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









