







目标检测/人体姿态估计:Objects as Points论文解读
论文地址:https://arxiv.org/abs/1904.07850
论文代码:https://github.com/xingyizhou/CenterNet
参考博客:扔掉anchor!真正的CenterNet——Objects as Points论文解读;论文精读——CenterNet :Objects as Points
论文概述
- 本论文的思想是将目标检测的问题看成是检测目标的bbox中心点,然后再回归出其它的目标信息,如尺寸(2D目标检测)、3D坐标、方向(3D目标检测)、姿态(人体姿态估计)。
- 方法在COCO数据集上实现了最好的speed-accuracy trade-off。
- 是一种anchor-free的目标检测方法。相比于one-stage和two-stage的框架,速度和精度都有不小的提升。


1. 简介
- 相比于one-stage和two-stage的目标检测方法,CenterNet方法的特点:
- Two-stage detectors :对每个潜在框重新计算图像特征,然后将那些特征进行分类。
- One stage detectors :在图像上滑动复杂排列的可能bbox(即锚点),然后直接对框进行分类,而不会指定框中内容。
- CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是背景 - 因为每个目标只对应一个“anchor”,这个anchor是从heatmap中提取出来的,所以不需要NMS再进行来筛选。
- CenterNet的输出分辨率的下采样因子是4,比起其他的目标检测框架算是比较小的(Mask-Rcnn最小为16、SSD为最小为16)。
2. 从中心点检测扩展到目标其它信息
- 2D目标检测:在每个热图peak(中心点)的图像特征预测出目标bbox的长和宽。
- 3D目标检测:直接回归得到目标的深度信息,3D框的尺寸,目标朝向;
- 人体姿态估计:将关节点(2D joint)位置作为中心点的偏移量,直接在中心点位置回归出这些偏移量的值。

2.初步


3. Bbox、3D、body pose等的回归
3.1 Bbox的回归


3.2 3D detection的回归

3.3 Body pose回归

4. 实施细节
我们实验了4个结构:ResNet-18, ResNet-101, DLA-34, Hourglass-104. 我们用deformable卷积层来更改ResNets和DLA-34,按照原样使用Hourglass 网络。

-
Hourglass
堆叠的Hourglass网络通过两个连续的hourglass 模块对输入进行了4倍的下采样,每个hourglass 模块是个对称的5层 下和上卷积网络,且带有skip连接。该网络较大,但通常会生成最好的关键点估计。 -
ResNet
Xiao et al.等人对标准的ResNet做了3个up-convolutional网络来dedao更高的分辨率输出(最终stride为4)。为了节省计算量,我们改变这3个up-convolutional的输出通道数分别为256,128,64。up-convolutional核初始为双线性插值。 -
DLA
即Deep Layer Aggregation (DLA),是带多级跳跃连接的图像分类网络,我们采用全卷积上采样版的DLA,用deformable卷积来跳跃连接低层和输出层;将原来上采样层的卷积都替换成3x3的deformable卷积。在每个输出head前加了一个3x3x256的卷积,然后做1x1卷积得到期望输出。 -
Training
训练输入图像尺寸:512x512; 输出分辨率:128x128 (即4倍stride);采用数据增强方式:随机flip, 随机scaling (比例在0.6到1.3),裁剪,颜色jittering;采用Adam优化器;
在3D估计分支任务中未采用数据增强(scaling和crop会影响尺寸);
更详细的训练参数设置(学习率,GPU数量,初始化策略等)见论文~~ -
Inference
采用3个层次的测试增强:没增强,flip增强,flip和multi-scale(0.5,0.75,1.25,1.5)增强;For flip, we average the network
outputs before decoding bounding boxes. For multi-scale,we use NMS to merge results.
5. 实验
5.1 Object detection
在COCO数据集上,
118k training images (train2017), 5k validation images (val2017) and 20k hold-out testing images (test-dev)。

5.2 3D detection
KITTI dataset
7841 training images

5.3 Pose estimation
MS COCO dataset
在COCO test-dev上验证

效果图

补充
目标检测网络结构:
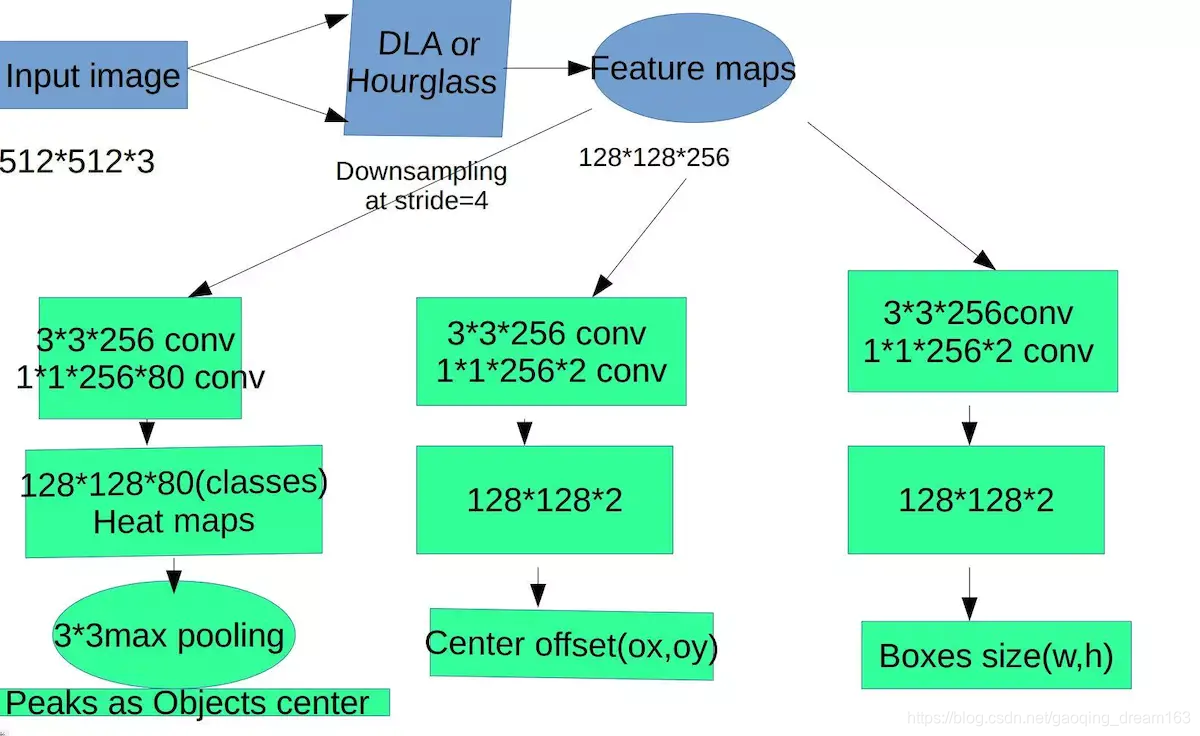
不同的网络arch结构:


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









