







Coordinated Deep Reinforcement Learners for Traffic Light Control
本文研究了交通灯的学习控制策略。在交通灯控制问题引入了一种新的奖励函数,并提出了将DQN算法 与 传输规划transfer planning相结合的多代理深度强化学习方法。通过使用传输规划,它避免了之前多代理强化学习中存在的问题,并且允许更快和更可扩展的学习。它优于早期关于多代理交通灯控制的工作,但DQN算法可能会发生振荡,需要进行更多的研究以防止DQN不稳定。
背景
将RL应用于交通灯控制的一个难题是选择特征:状态的数量是巨大的,每个状态描述交叉点周围的确切情况。
我们对单交叉DQN方法【15】进行了修改,并研究了奖励函数的有效表达式。
为了提高训练过程的稳定性,我们测试了在交通控制背景下深度学习领域中一些最新技术的效果【22,5,17】。
此外,我们提出了使用这些技术来协调多交叉口的方法。
有两种方法来稳定DQN算法:
第一种是经验重放【10,14】,其中采样数据点 <s,a,r,s0> 存储在存储器memory中,并且在训练时批量采样这些数据点(或根据 TD-error,如优先经验重放【17】)并用于反向传播backpropagation。
第二种解决方案是 target network freezing【12】,其中Q-value估计被分成两个不同的网络,一个用于估计当前状态的Q(s,a)的值网络value network, 一个计算目标y 的目标网络target network 。
交通灯控制 - 深度强化学习DQN
STATE
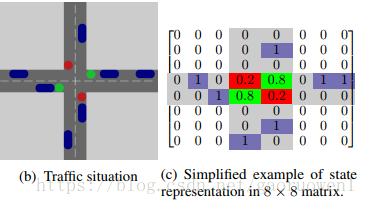
我们使用类似图像image-like的表示来表示交叉口周围的状态,如图b示。
在之前的工作【15】中,由交通灯控制的车道上车辆位置的二元矩阵表示状态,如图c示。
因此,卷积神经网络应该能够识别交通堵塞。
在当前模型中,交通灯颜色的表示使用数字来映射。
交通灯信息将是状态空间的额外层,每个交通灯颜色都具有二进制特征。
但是,这会随着状态空间的增加导致replay memory的内存问题,以及较慢的计算。
ACTION
在每个时间步,代理采取的动作在两种不同的交通灯配置间进行选择。代理选择哪个车道获得绿灯。
TRANSITION
从 s t s_t <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3779
3779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









