






目录
1.研究动机
- 交通拥堵代价高 -> 交叉路口交通控制是关键
- 大多数信号灯是固定时间 -> 应该根据实际交通情况动态设置
- 强化学习技术一直用于此领域 - >现有的研究还没有在真实世界的交通数据上测试该方法,只专注于研究奖励,而没有策略解释
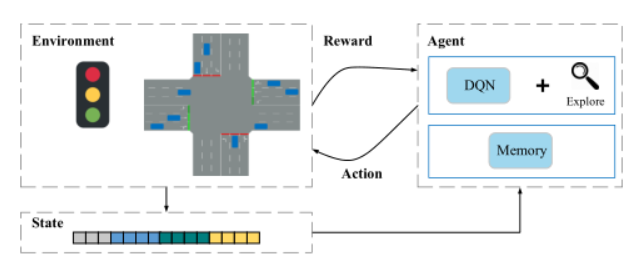 图1:深度强化学习的基本思想
图1:深度强化学习的基本思想
贡献:在本文中,我们提出了一种用于交通灯控制的更有效的深度强化学习模型
1.1 真实的交通实验数据
缺点:现有的研究都没有使用真实的交通数据,当前研究中的模拟模型通常假设车辆以恒定的速度到达,但实际交通量随时间高度动态
数据:中国济南1704个监控摄像头获得的31天的大规模真实交通数据
1.2 策略解释
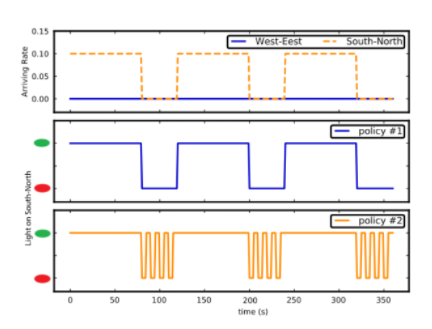
图2:两种情况奖励相同,但是策略不同,策略1优于策略2
量化交通灯控制绩效的一个常用方法是检查总体奖励,该奖励可以通过几个因素来定义,例如车辆等待时间和通过十字路口的车辆数量
缺点:然而,现有的研究很少对从模型中学到的策略进行观察,某些情况奖励可能会产生误导本文研究策略而不是简单地显示回报是重要的
1.3相位门控模型学习
缺点:先前的研究都是将相位当作一个特征,以及其他许多特征,这一个特性很可能没有起到足以影响模型输出的作用
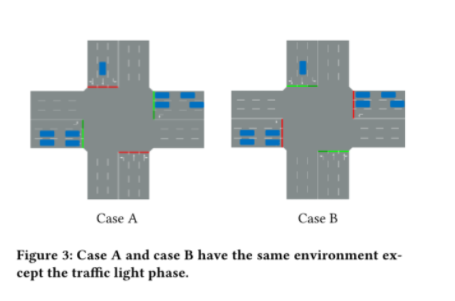
缺点:导致A和B都会做出相同的决定,但哪一种决定都不适合其中一种情况,因为A是要保持,B是要改变
在本文中,我们提出了一种相位门结合记忆宫殿强化学习代理,这是导致优异性能的关键组件
2.相关工作
2.1常规交通灯控制
- 预定时信号控制,根据历史交通需求确定所有绿色阶段的固定时间,而不考虑交通需求的可能波动
- 使用实时交通信息的车辆驱动控制方法,车辆驱动方法适用于交通随机性相对较高的情况,然而,这种方法在很大程度上取决于当前交通状况的人工规则,而没有考虑未来的情况
2.2交通灯控制的强化学习
- 以前的研究把状态设置为离散值,如车辆位置或等待车辆的数量,然而,“离散状态-动作对矩阵"需要巨大的存储空间
- 最近,提出连续状态表示深度Q学习。然而,所有这些方法都假定相对静态的交通环境,因此与实际情况相去甚远。此外,他们只关注奖励,而忽略了算法对真实流量的适应性。因此,他们无法解释为什么学习到的灯信号会随着交通而改变
- 在本文中,我们试图在更现实的交通环境中测试算法,并添加更多的解释而不是奖励
3.方法论
- 传统方法通常依赖于先前的知识来为每个灯相位设置固定时间或设置变化规则。这些规则易于动态改变流量。
- 强化学习方法通常将交通状况(例如,等待车辆的队列长度和更新的等待时间)作为状态,并尝试根据当前状态采取行动来改善交通状况
然而,目前的方法没有考虑实际情况中的复杂情况,因此可能导致陷入一种单一的行动。这将导致在复杂的交通状况下交通调节性能较差
3.1框架
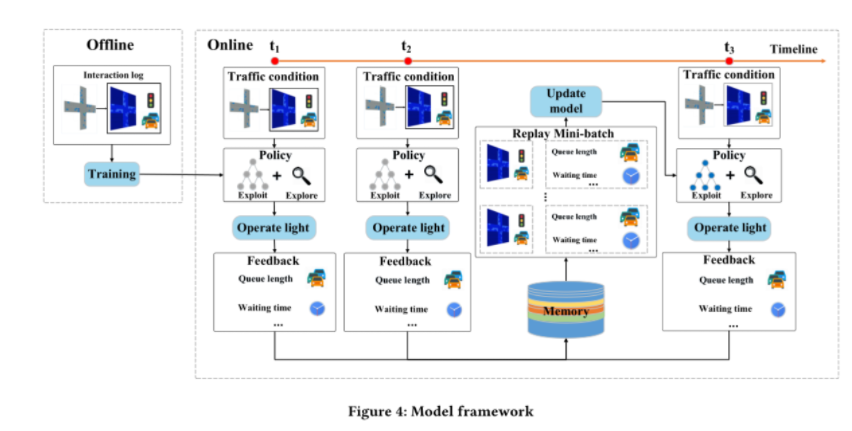 离线阶段,我们为交通灯设置了固定的时间表,让交通通过系统收集数据样本,对本阶段记录的样本进行培训后,模型将被放入在线部分
离线阶段,我们为交通灯设置了固定的时间表,让交通通过系统收集数据样本,对本阶段记录的样本进行培训后,模型将被放入在线部分
3.2Agent设计
一个交叉路口状态Stage:
对每条车道i,状态包括队列长度L,车辆数量V,车辆的更新等待时间W,一张包括车辆位置M,当前相位P和下一相位的图像
Action:
a=1:将灯切换到下一个相位Pn。a=0:保持当前相位Pc
Reward:
- 所有进场车道上的排队长度L之和:为给定车道上等待车辆的总数,速度小于0.1m/s视为等待
- 所有进场车道上的延迟D之和:车道i的延迟定义如下:
lane speed:车道的平均速度 speed limit:公路允许的最大速度
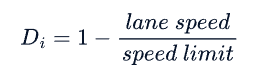
- 所有进场车道的更新等待时间之和:车辆j在时间t内的定义如下:
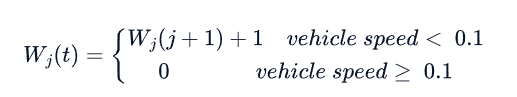
- 指示灯开关C:其中C=0表示保持电流相位,C=1表示改变电流相位
- 最后一个动作a之后,时间间隔内通过交叉口的车辆总数N
- 最后一个动作a之后,时间间隔通过交叉口的车辆的总行驶时间T,为车辆在进场车道上花费的总时间(以分钟为单位)
总奖励:
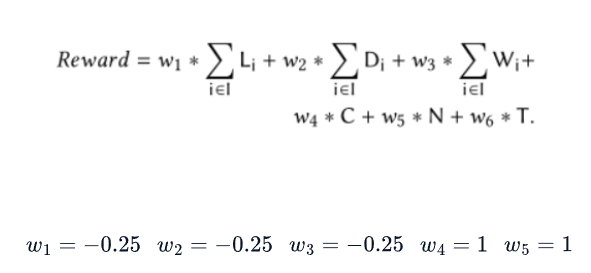
任务
给定s,根据贝尔曼方程 --》找到 导致长期最大汇报r的 --》执行动作a
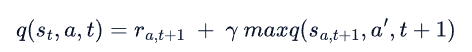
3.3网络结构
为了应对1.3提出的问题,本文提出了一个“相位门”的概念!
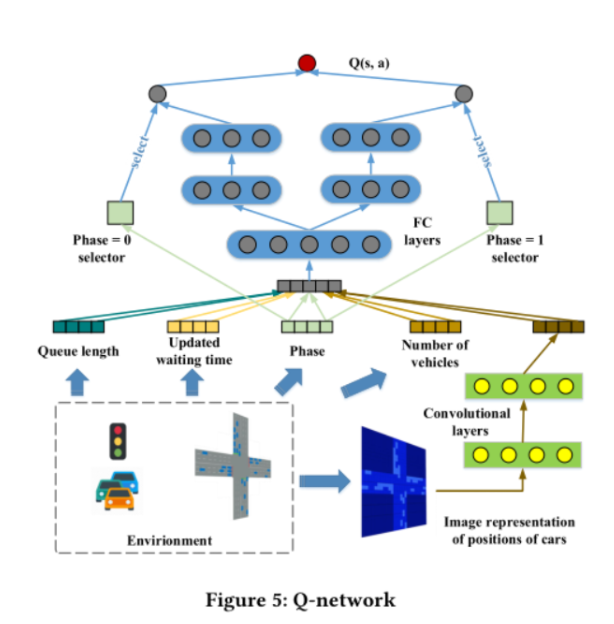
- 对于每个阶段,设计了一个单独的学习过程,将奖励映射到决策的价值Q(s,a)。这些单独的过程通过由相位控制的门来选择
- 当相位P=0时,左分支将被激活,而当相位P=1时,右分支将被启动
- 好处-解决了1.3的问题:这将区分不同阶段的决策过程,防止决策偏向于某些行动,并增强网络的适应能力
3.4记忆宫殿和模型更新
存在问题
传统的经验重放是随机取,所以很大概率取到频繁出现的状态和动作,Agent就会很好的估计这些状态和动作的奖励,但是忽略了不平常的状态-动作组合,这将导致学习的代理在不频繁的阶段动作组合上做出错误的决定
解决
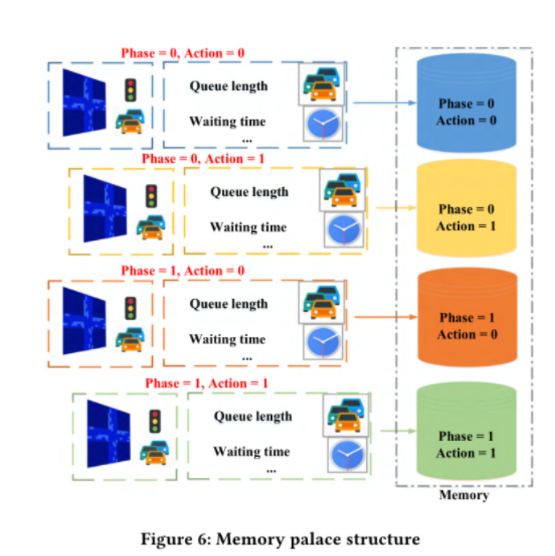
受认知心理学中记忆宫殿理论的启发,可以通过对不同阶段动作组合使用不同的记忆宫殿来解决这种失衡
这些平衡样本将防止不同的阶段动作组合干扰彼此的训练过程,因此,提高网络的拟合能力,以准确预测奖励
4.实验
4.1数据源
使用合成和真实交通数据进行实验,SUMO仿真
4.2评价指标
Reward奖励:随着时间的推移的平均回报
排队长度:一段时间内的平均排队长度。t时刻的排队长度是所有进场车道上L的总和。
延迟:随时间推移的平均延迟,其中时间t的延迟是所有进场车道的D(定义见等式1)之和。
持续时间:车辆在接近车道上花费的平均行驶时间(秒)。持续时间越短,意味着车辆通过十字路口的时间越短
总之,
- 较高的回报表明该方法的性能更好
- 而较小的队列长度、延迟和持续时间表明交通堵塞较少
4.3对比方法
- 固定时间FT:使用预先确定的周期和阶段时间计划
- 自组织交通灯控制SOTL:当等待车辆的数量超过手动调节的阈值时,交通灯将改变
- 交通灯控制的深度强化学习DRL:它仅依赖于原始交通信息作为图像
除了baseline,还有几种所提方法的变形:
IntelliLight(Base):没有记忆宫殿和相位门
IntelliLight(Base+MP):有记忆宫殿
IntelliLight (Base+MP+PG):记忆宫殿和相位门
4.4数据集
4.4.1 合成数据:符合泊松分布
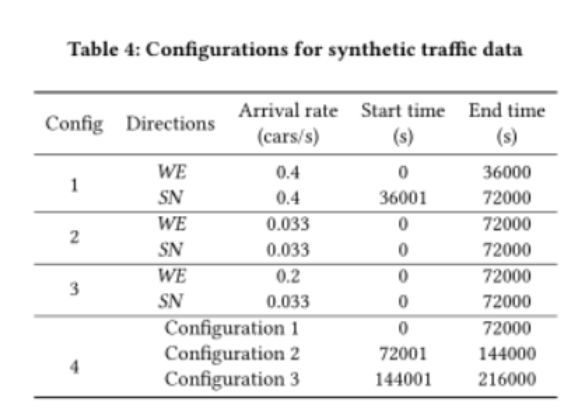
数据性能:我们的方法在配置1、2、3和4中的性能优于所有其他基线方法;添加Memory Palace有助于在配置3和4下获得更高的奖励,尽管它不会提高配置1和2下的奖励。对稳定的1,2没有很大作用。在大多数情况下,进一步增加相位门还可以缩短队列长度,并获得最高的回报,这证明了这两种技术的有效性。
4.4.2真实世界数据:
使用通过24个交叉口的车辆数量作为交通量进行实验
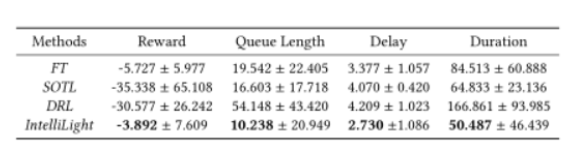
分析WE方向和SN方向 交叉口在不同场景下的交通灯政策:高峰时段与非高峰时段、工作日与周末、主干道与次干道;IntelliLight在所有比较方法中实现了最佳的奖励、队列长度、延迟和持续时间,与最佳基线方法相比,相应地提高了32%、38%、19%和22%
数据性能:
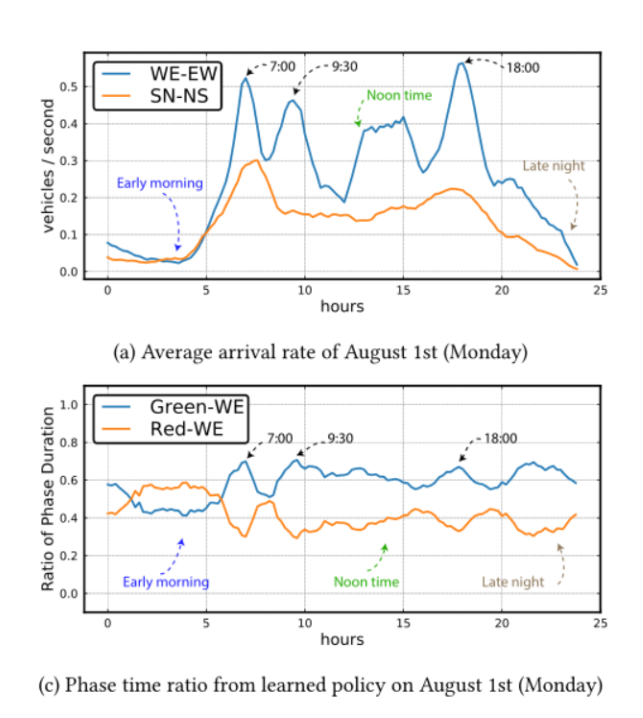
- 高峰时段 VS 非高峰时段:WE在高峰期的时候持续时间长,交通灯开放时间与车流量一致
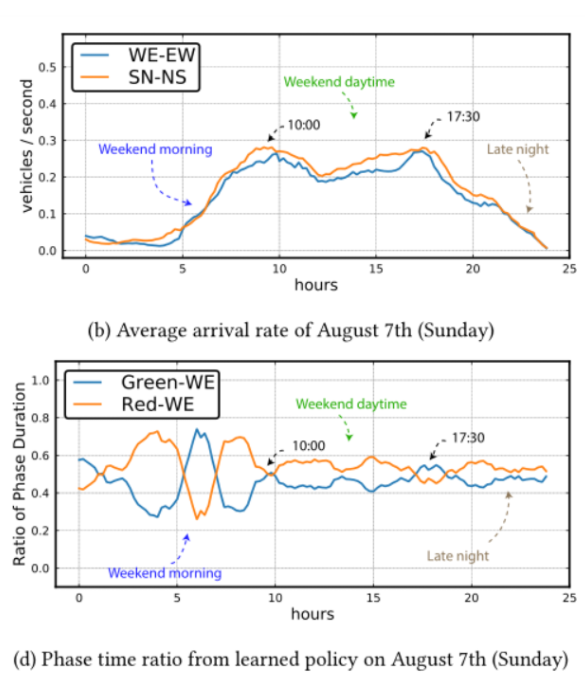
- 周末 VS 周末 :持续时间接近0.5
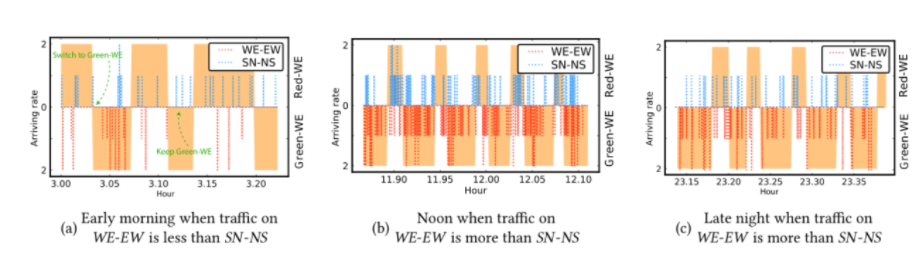
- 主干线和非主干线:
- 1)图a)红色WE阶段的总时间周期长于绿色WE,这与此时的交通量相适应。 尽管某个时候SN的交通量大于WE,但交通灯从绿色WE变为红色WE通常不是由SN方向的等待车辆触发的;WE上的道路是这些时间段的主要道路,交通灯倾向于绿色WE阶段
- 相反,在图10(b)和图10(c)中,从绿色WE到红色WE的变化通常由SN方向的等待车辆触发
5.结论
- 首先,我们可以将两相交通灯扩展到多相交通灯,这将涉及更复杂但更现实的状态转换。
- 第二,我们的论文讨论了一个简化的单交叉口案例,而现实世界的道路网络比这复杂得多。
- 解决多交叉口问题,没有明确考虑不同交叉口之间的相互作用(即,一个交叉口的相位如何影响附近交叉口的状态),并且它们仍然限于少量交叉口
- 最后,我们的方法仍然在仿真框架上进行了测试,从而对反馈进行了仿真。最终,应进行实地研究,以了解真实世界的反馈,并验证所提出的强化学习方法















 3779
3779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









