






-
卷积神经网络首先学会识别边界和颜色,然后将这些信息用于识别形状和图形等更复杂的实体。比如在人脸识别上,他们学会从眼睛和嘴巴开始识别最终到整个面孔,最后根据脸部形状特征识别出是不是人的脸。
-
卷积网络对不同人脸的识别
{% gp 1-3 %}
正在上传…重新上传取消
{% endgp %}
1|2深度卷积网络的缺陷
- CNN 对物体之间的空间关系 (spatial relationship) 的识别能力不强,比如上图中的嘴巴和眼睛换位置了还被识别成人
- CNN 对物体旋转之后的识别能力不强 (微微旋转还可以),比如卡戴珊倒过来就被识别成头发了
基于以上缺陷,Hinton在神经网络中提出capsule的概念,个人认为也可以叫做向量神经元,capsule不同于传统的标量神经元,而是向量神经元,具有方向性。
参考文献:Sabour, S., et al. (2017). Dynamic routing between capsules. Advances in neural information processing systems.
1|3标量神经元与向量神经元
标量神经元的计算:
- 将输入标量 x 乘上权重 w
- 对加权的输入标量求和成标量 a
- 用非线性函数将标量 a 转化成标量 h
向量神经元的计算:
- 将输入向量 u 用矩向量W 加工成新的输入向量 U
- 将输入向量 U 乘上耦合系数 C
- 对加权的输入向量求和成向量 s
- 用非线性函数将向量 s 转化成向量 v
转存失败重新上传取消]
1|4胶囊的内部结构
-
胶囊的输入向量和输出向量计算公式
正在上传…重新上传取消
其中,v代表胶囊j的输出向量,s代表胶囊的输入向量,这个转化其实是将向量s进行一个压缩和单位化的操作。
-
压缩:如果s很长,那么左边项约等于1,如果s很短,那么左边项约等于0
-
单位化:使输出向量长度为0到1之间的向量,因此长度可以表示为特征概率值
1|5层级胶囊的动态路由
-
胶囊的映射方式
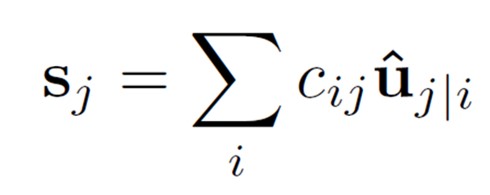
u是上一个胶囊层的输出向量,w是连接两个胶囊层的向量权重,uj|iuj|i 是上一层的神经元经过权重后的预测向量,cijcij是不同层向量元的耦合系数,s为本层的胶囊向量的输入,也是预测向量的加权和,只不过权重变成了耦合
系数,并不是标量元里面的权重值 -
动态路由系数计算

正在上传…重新上传取消
正在上传…重新上传取消
-
层级胶囊路由的伪代码

1|6数字的边际损失函数

利用向量的长度来表示capsule 实体存在的概率,因此,对于数字类别k,希望高层次的capsule 能够有一个较长的输出向量,对于每个digit capsule k:
1|7胶囊网络的结构

- 第一层卷积层:原始图像输入size为2828,采用大小为9的卷积核生成256个通道的特征图,并且用relu作为激活函数输出大小为25620*20的特征图
- 第二层卷积层(PrimaryCaps):输入的特征图大小为2562020,每个PrimaryCaps通过8个99大小卷积核,strid为2获得,一共输出32个PrimaryCaps,即每个PrimaryCaps有66个维度8D的胶囊单元,不同的map代表不同的特征类型,
同一个map中的向量代表不同的位置 - 第三层DigitCaps对第二层所有的胶囊进行动态路由连接到第三层,第二层一共3266个8D向量通过动态路由连接成10个16D的胶囊向量,相当于采用不同参数对第二层所有向量进行10次变维度映射。
1|8重构
重构的意思就是用预测的类别重新构建出该类别代表的实际图像。

Capsule的向量可以表征一个实例,将最后的那个正确预测类别的向量投入到后面的重构网络中,可以构建一个完整的图像,从而可以通过重建图像与原图像的欧式距离来评估此模型分类的效果,更能说明胶囊网络中向量神经元具有的优
越性,图中的784即为原始图像的28*28大小。
1|9重建作为调整方法
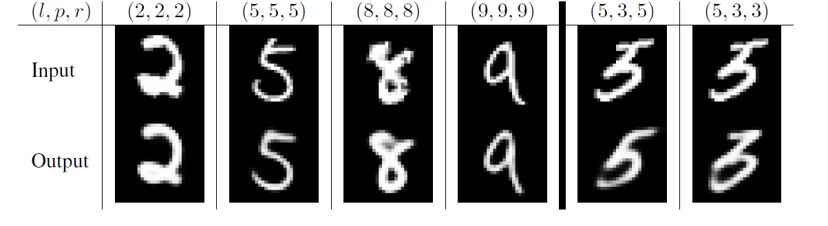
- L代表标签,p代表预测值,r重构出的图片,左边三列是正确的结果。
- 重构出来的图像形状和位置和输入极其类似,这是说明胶囊网络起了作用,Capsule的确包含了物体的多个信息:特征、位置、大小等等。
- 后面两列是预测失败的,通过重构出来的图我们可以得到原因:3和5太像了,即使人也很难清楚的分辨出来。
1|10胶囊网络的一些应用
- 可以利用胶囊向量的方向性进行物体角度估计,从而可以 弥补卷积网络在这方面的缺陷
- 可以对重叠图像中的特征进行有效识别
- 利用胶囊网络进行手语的识别,胶囊网络善于提取不同物体的角度信息,从而可以分辨不同角度的手势,为自动手语翻译提供很好的帮助
1|11胶囊网络推荐文章
- Sabour S, Frosst N, Hinton G E. Dynamic routing between capsules[C]//Advances in neural information processing systems. 2017: 3856-3866.
- Hinton G E, Krizhevsky A, Wang S D. Transforming auto-encoders[C]//International Conference on Artificial Neural Networks. Springer, Berlin, Heidelberg, 2011: 44-51.
- Hinton G. Taking inverse graphics seriously[J]. 2013.
2|0图神经网络(Graph Neural Network)
2|1图模型的相关概念
- 图是一种非结构化数据,作为一种非欧几里得形数据,图分析被应用到节点分类、链路预测和聚类等方向。图网络是一种基于图域分析的深度学习方法。
- 图表示(graph embedding)是一种图的知识表示方法,即如何将图中的节点、边和子图以低维向量的形式表现出来。受启发于表示学习(representation learning)和词嵌入(word embedding),图嵌入技术得到了长足的发展,例>如DeepWalk模型。
2|2图神经网络的分类
不同的文献对图神经网络有不一样的分类,不过基本都是根据各自的特性来进行分类的
- 文献1根据图模型结构:
Directed Graphs、Heterogeneous Graphs、Graphs with Edge Information
Zhou J, Cui G, Zhang Z, et al. Graph neural networks: A review of methods and applications[J]. arXiv preprint arXiv:1812.08434, 2018. - 文献2根据聚合函数:
graph convolution networks、graph attention networks、graph auto-encoders、graph generative networks、graph spatial-temporal networks
Wu Z, Pan S, Chen F, et al. A comprehensive survey on graph neural networks[J]. arXiv preprint arXiv:1901.00596, 2019.
2|3图模型结构
- 在图中,每个节点的定义是由该节点的特征和相关节点来共同表示的。GNN的目标是训练出state embedding函数hv,该函数包含了每个节点的邻域信息

hvhv是节点v的向量化表示,可以用来预测该节点的输出ovov(例如节点的标签),xvxv是节点v的特征表示,x_c_0x_c_0是节点v相关的边的特征表示,hnehne节点v相关的当前状态,xnexne是节点v邻接节点的特征表示,f是local transition function,被所有节点共享,根据领域信息更新当前节点装填 - g被称作local output function,用来产生节点输出,实现分类或者回归任务
2|4图模型损失函数
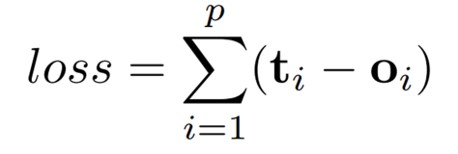
p代表图中所有有监督节点的数量。优化是基于梯度下降算法的,并且被表示如下:
- H进行迭代更新,直到T时间步
- 权重W的梯度通过loss计算得出
- 进行梯度更新
2|5图模型类型(Graph Types)
- 有向图(Directed Graphs)
- 传统的无向边可以看作是两个有向边组成的,表明两个节点之间存在着关系。然而,有向边相对与无向边来说能够表达更为丰富的信息
- 异构图(Heterogeneous Graphs)
- 包含有不同类型的几种节点,表现不同类型节点最简单的形式是,将类型用one-hot向量表示,然后与原始节点的特征向量进行拼接
- Graph Inception模型将metapath的概念引入到了异构图的传播中。我们可以对邻近节点进行分类,根据其节点的类型和其距离。对于每个邻近节点群,Graph Inception将它作为一个同构图中的子图,并将来自于不同同构图的传>播结果连接起来视为一个集合节点来表示
- 带有边信息的图(Graphs with Edge Information)
- 在图中,边也蕴含着丰富的信息,例如权重和边的类型等。有两种表示图的方式:
- 两个节点之间的边切割开成两条边,然后将边也转化成节点
- 在传播过程中,不同的边上有不同的权值矩阵
- 在图中,边也蕴含着丰富的信息,例如权重和边的类型等。有两种表示图的方式:
2|6传播类型(Propagation Types)
- 在模型中,信息的传播步骤和输出步骤是获得节点或者边隐含状态的关键步骤。不同变种的GNN的聚合函数(用来聚合图中所有点的邻域信息,产生一个全局性的输出)和节点状态更新函数如下图所示,其中常见的就是卷积聚合函数和
注意力聚合函数: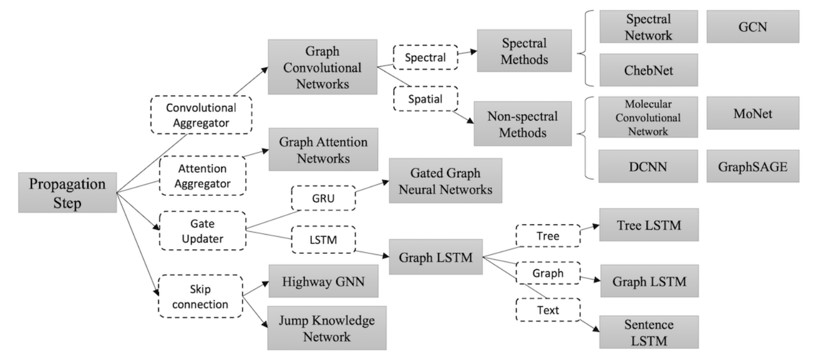
- Attention:GAT是一种注意力图网络,它将注意力机制融入到了图传播的步骤中。GAT计算每个节点的隐藏状态,通过将 “attention” 机制应用到邻近节点上,从而可以通过不同的关注力对邻接节点信息进行聚合

- 除此之外还有Gate和Skip connection传播类型,各自有不同的功能
2|7训练方法(Training Methods)
论文中还介绍了几种GNN的训练方法。比如Graph SAGE从节点的部分邻域聚合信息。Fast GCN采用样本采样方法替代节点的所有邻域信息。其宗旨都是为了改进图模型计算复杂这一缺点,这些训练方法,都使得模型的训练效率更加的高效
,随机丢弃一些邻域点还能使图模型的鲁棒性增
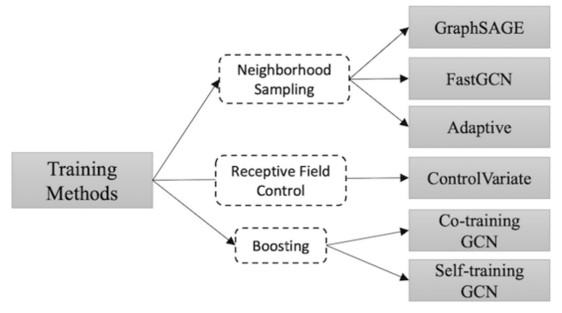
2|8应用(APPLICATIONS)
图网络被广泛的应用于包括监督学习、半监督学习、无监督学习和强化学习等方向。论文中从三个不同的场景来分别阐述图网络的应用。
-
结构化场景:数据包含有很明确的关系结构,如物理系统、分子结构和知识图谱。
-
非结构化场景:数据不包含明确的关系结构,例如文本和图像等领域。
-
其他应用场景:例如生成式模型和组合优化模型。
各个领域图网络的应用细节如下图所示:
2|9推荐文献
- Kipf, T. N. and M. Welling (2016) Semi-Supervised Classification with Graph Convolutional Networks. ArXiv e-prints
- Scarselli, F., et al. (2009). "The Graph Neural Network Model." IEEE Transactions on Neural Networks 20(1): 61-80.
- Veličković, P., et al. (2017) Graph Attention Networks. ArXiv e-prints
- Ying, R., et al. (2018) Graph Convolutional Neural Networks for Web-Scale Recommender Systems. ArXiv e-prints
- Bruna, J., et al. (2013) Spectral Networks and Locally Connected Networks on Graphs. ArXiv e-prints
3|0胶囊图神经网络(Capsule Graph Neural Network)
3|1图卷积网络(GRAPH CONVOLULTIONAL NETWORK)
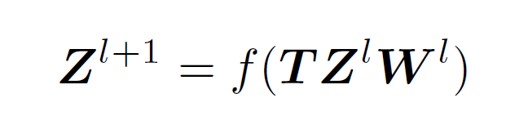
T是信息变换矩阵,是通过邻接矩阵变换得来,大小N*N,w是节点向量维度变换矩阵
3|2CapsGNN模型结构

- Block1:基本节点胶囊提取模块,利用GCN原理生成当前时刻节点状态,作为胶囊向量,向量长度为N
- Block2:高级图胶囊提取模块,融合了注意力模块和动态路由,以生成多个图胶囊
- Block3:图分类模块,再次利用动态路由,生成用于图分类的类胶囊
3|3基本节点胶囊提取模块

3|4高级图胶囊提取模块
注意力机制的目的:让模型更加注重图中更重要相关的节点或者邻域信息

将初始胶囊的每一个节点的所有通道的d维向量进行concat,生成第二个图的向量,利用注意力函数F计算出注意力值矩阵,然后对每一行进行归一化,得到每个通道不同节点的注意力值的归一化值,然后与原来初始胶囊相乘,可以得到>带有不同注意力的胶囊向量组
公式如下:
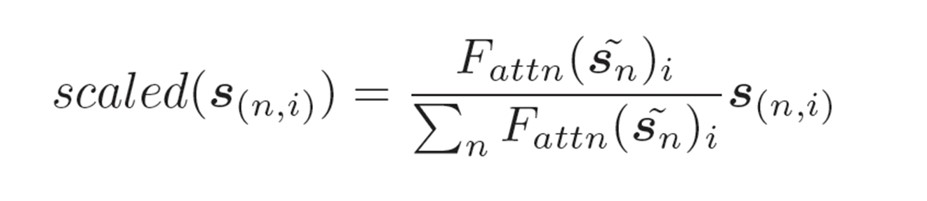
计算投票:对注意力机制生成的胶囊向量矩阵进行投票计算,其实是用一个可训练的权重矩阵对整个胶囊向量进行多次计算,最后生成P个图胶囊,每一个图胶囊都是对整个图的不同角度的观察,然后利用路由机制生成下一层的图胶囊。
3|5图分类模块
运用动态路由思想,继续将P个图胶囊路由成C个类别的分类胶囊
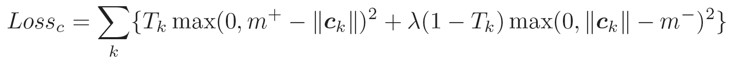
利用分类损失函数进行梯度下降,训练整个模型
3|6重建

重建损失,将分类好的胶囊向量通过多层全连接可以重建原数据,如果是图像,那么可以重建图像,并且根据重建损失来进行全连接的训练,其目的在于可以对最终分类的效果进行可视化,而不是简单给出一个概率值,有利于模型的整>体评估。
3|7结果
- 提升了图模型的分类正确率
- 提升了图模型的效率,用更少的节点可以描绘更多的信息
- 能够通过图胶囊捕捉到更多图模型的属性信息
3|8参考文献
- Zhang Xinyi, L. C. (2019). "Capsule Graph Neural Network."
3|9演讲ppt下载
参考ppt下载:图模型ppt














 2258
2258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









