









原来泰勒级数也能被拿来做语音增强
扫盲=前言
这些储备知识有的忘记了,有的就没学过,还要从头慢慢来学
泰勒级数
定义
【摘抄百度】泰勒级数是以于1715年发表了泰勒公式的英国数学家布鲁克·泰勒(Sir Brook Taylor)的名字来命名的。通过函数在自变量零点的导数求得的泰勒级数又叫做麦克劳林级数,无限项连加式(级数)来表示一个函数,这些相加的项由函数在某一点的导数求得。说到此其实跟傅里叶级数也有一些相似之处。假设 f ( x 0 ) f(x_0) f(x0)在 x 0 x_0 x0附近有任意阶导数,则 f ( x 0 ) f(x_0) f(x0)在 x 0 x_0 x0点展开的泰勒级数为 ∑ n = 0 ∞ f ( n ) ( x 0 ) n ! ( x − x 0 ) n = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + . . . + f ( n ) ( x 0 ) n ! ( x − x 0 ) n + . . . \sum_{n=0}^\infty \frac{f^{(n)}(x_0)}{n!}(x-x_0)^n=f(x_0)+f^\prime(x_0)(x-x_0)+\frac{f^{\prime\prime}(x_0)}{2!}(x-x_0)^2+...+\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n+... n=0∑∞n!f(n)(x0)(x−x0)n=f(x0)+f′(x0)(x−x0)+2!f′′(x0)(x−x0)2+...+n!f(n)(x0)(x−x0)n+...
泰勒级数扩展
根据定义,令
δ
x
=
x
0
−
x
\delta x=x_0-x
δx=x0−x,一个函数
f
(
x
)
f(x)
f(x)在某一处
x
x
x位置展开的泰勒形式改写如下:
f
(
x
+
δ
x
)
=
f
(
x
)
+
f
′
(
x
)
δ
x
+
1
2
!
f
′
′
δ
x
2
+
1
3
!
f
′
′
′
δ
x
3
+
.
.
.
f(x+\delta x)=f(x)+f^\prime(x)\delta x+\frac{1}{2!}f^{\prime\prime}\delta x^2+\frac{1}{3!}f^{\prime\prime\prime}\delta x^3+...
f(x+δx)=f(x)+f′(x)δx+2!1f′′δx2+3!1f′′′δx3+...如果
δ
x
\delta x
δx非常小,高阶项可以忽略,用二阶截止展开开近似:
f
(
x
+
δ
x
)
≈
f
(
x
)
+
f
′
(
x
)
δ
x
+
1
2
!
f
′
′
δ
x
2
f(x+\delta x)\approx f(x)+f^\prime(x)\delta x+\frac{1}{2!}f^{\prime\prime}\delta x^2
f(x+δx)≈f(x)+f′(x)δx+2!1f′′δx2在工程误差允许的范围,甚至直接用一阶线性展开
f
(
x
+
δ
x
)
≈
f
(
x
)
+
f
′
(
x
)
δ
x
f(\bold x+\delta \bold x)\approx f(\bold x)+f^\prime(x)\delta x
f(x+δx)≈f(x)+f′(x)δx
多变量泰勒级数
对于多变量函数
f
(
x
)
=
f
(
x
1
,
.
.
.
,
x
N
)
f(\bold x)=f(x_1,...,x_N)
f(x)=f(x1,...,xN),同样被展开为泰勒级数,工程中一般用到二阶展开较多:
f
(
x
+
δ
x
)
≈
f
(
x
)
+
∑
j
=
1
N
∂
f
(
x
)
∂
x
j
δ
x
j
+
1
2
!
∑
i
=
1
N
∑
j
=
1
N
∂
2
f
(
x
)
∂
x
i
∂
x
j
δ
x
i
δ
x
j
f(x+\delta x)\approx f(x)+\sum_{j=1}^N\frac{\partial f(\bold x)}{\partial x_j}\delta x_j+\frac{1}{2!}\sum_{i=1}^N\sum_{j=1}^N\frac{\partial^2 f(\bold x)}{\partial x_i\partial x_j}\delta x_i\delta x_j
f(x+δx)≈f(x)+j=1∑N∂xj∂f(x)δxj+2!1i=1∑Nj=1∑N∂xi∂xj∂2f(x)δxiδxj
假设
δ
x
=
[
δ
x
1
,
.
.
.
,
δ
x
N
]
T
\delta \bold x=[\delta x_1, ..., \delta x_N]^T
δx=[δx1,...,δxN]T,并令
g
\bold g
g作为梯度向量
g
=
g
f
(
x
)
=
▽
f
(
x
)
=
[
∂
f
(
x
)
∂
x
1
,
.
.
.
,
∂
f
(
x
)
∂
x
N
]
T
\bold g=\bold g_f(\bold x)= \triangledown f(\bold x)=[\frac{\partial f(\bold x)}{\partial x_1},...,\frac{\partial f(\bold x)}{\partial x_N}]^T
g=gf(x)=▽f(x)=[∂x1∂f(x),...,∂xN∂f(x)]T,令
H
\bold H
H表示为黑塞矩阵(多元函数的二阶偏导数构成的方阵)
H
=
H
f
(
x
)
=
d
d
x
g
f
(
x
)
=
[
∂
2
f
(
x
)
∂
x
1
2
⋯
∂
2
f
(
x
)
∂
x
1
∂
x
N
⋮
⋱
⋮
∂
2
f
(
x
)
∂
x
N
∂
x
1
⋯
∂
2
f
(
x
)
∂
x
N
2
]
\bold H=\bold H_f(x)=\frac{d}{d\bold x}\bold g_f(\bold x)= \begin{bmatrix} \frac{\partial^2 f(\bold x)}{\partial x_1^2} & \cdots & \frac{\partial^2 f(\bold x)}{\partial x_1\partial x_N} \\ \vdots & \ddots & \vdots \\ \frac{\partial^2 f(\bold x)}{\partial x_N\partial x_1} & \cdots & \frac{\partial^2 f(\bold x)}{\partial x_N^2} \end{bmatrix}
H=Hf(x)=dxdgf(x)=⎣⎢⎢⎡∂x12∂2f(x)⋮∂xN∂x1∂2f(x)⋯⋱⋯∂x1∂xN∂2f(x)⋮∂xN2∂2f(x)⎦⎥⎥⎤
用向量和矩阵来表达
f
(
x
+
δ
x
)
≈
f
(
x
)
+
g
T
δ
x
+
1
2
!
x
T
H
δ
x
f(\bold x+\delta \bold x)\approx f(x)+\bold g^T\delta \bold x+\frac{1}{2!}\bold x^T \bold H \delta \bold x
f(x+δx)≈f(x)+gTδx+2!1xTHδx
多变量矢量函数的泰勒展开
在多变量的基础上,一组函数的向量表达如下:
f
(
x
)
=
[
f
1
(
x
)
,
.
.
.
,
f
M
(
x
)
]
T
\bold f(\bold x)=[f_1(\bold x),...,f_M(\bold x)]^T
f(x)=[f1(x),...,fM(x)]T
联系上节内容,某一项的展开为
f
i
(
x
+
δ
x
)
≈
f
i
(
x
)
+
g
i
T
δ
x
+
1
2
!
x
T
H
i
δ
x
f_i(x+\delta x)\approx f_i(x)+\bold g_i^T\delta \bold x+\frac{1}{2!}\bold x^T \bold H_i \delta \bold x
fi(x+δx)≈fi(x)+giTδx+2!1xTHiδx
但是矢量合成的二维展开的二阶项是一个张量(三维),太烧脑,所以一般只保留一阶项展开
f
(
x
+
δ
x
)
≈
f
(
x
)
+
J
f
(
x
)
δ
x
\bold f(\bold x+\delta \bold x)\approx \bold f(\bold x)+\bold J_f(\bold x) \delta \bold x
f(x+δx)≈f(x)+Jf(x)δx
这里
J
f
(
x
)
\bold J_f(\bold x)
Jf(x)即向量函数
f
(
x
)
\bold f(\bold x)
f(x)的雅可比矩阵():
J
f
(
x
)
=
d
d
x
=
[
f
1
⋮
f
M
]
[
∂
∂
x
1
.
.
.
∂
∂
x
N
]
=
[
∂
f
1
∂
x
1
⋯
∂
f
1
∂
x
N
⋮
⋱
⋮
∂
f
M
∂
x
1
⋯
∂
f
M
∂
x
N
]
\bold J_f(\bold x)=\frac{d}{d\bold x}=\begin{bmatrix} f_1\\ \vdots \\ f_M \end{bmatrix}[\frac{\partial}{\partial x_1}...\frac{\partial}{\partial x_N}]\\ =\begin{bmatrix} \frac{\partial f_1}{\partial x_1} & \cdots & \frac{\partial f_1}{\partial x_N} \\ \vdots & \ddots & \vdots \\ \frac{\partial f_M}{\partial x_1} & \cdots & \frac{\partial f_M}{\partial x_N} \end{bmatrix}
Jf(x)=dxd=⎣⎢⎡f1⋮fM⎦⎥⎤[∂x1∂...∂xN∂]=⎣⎢⎡∂x1∂f1⋮∂x1∂fM⋯⋱⋯∂xN∂f1⋮∂xN∂fM⎦⎥⎤
应用方向
以下是总知网看到的一个介绍【2】,差不多概括了vts在降噪领域的一个应用方向
矢量泰勒级数是一种有效的抗噪声鲁棒语音识别算法.虽然在对数谱域,美尔滤波器组的不同通道之
间有较强的相关性,因而难以从含噪语音中准确估计噪声的方差.但是基于矢量泰勒级数的倒谱域特
征补偿算法,用一个高斯混合模型描述语音倒谱特征的分布,通过矢量泰勒级数从含噪语音中估计噪
声的均值和方差.能明显提高语音识别系统的性能.
那么如何应用,有何好处呢,说来话长了。
VTS在变换域的鲁棒性应用
追溯VTS最早的文章是1996年的《A vector Taylor series approach for environmentindependent speech recognition》,是CMU大学做语音识别的一遍论文,联系到当时GMM-HMM的主流模型,这篇文章也是在此框架下的一个改进。改论文不仅建模了VTS分析方法,还提出了应用的两个方向:
- 直接对语音进行补偿(语音增强),然后识别
- 利用VTS的公式改进HMM统计模型。
上述两个方法仅仅需要的是待识别的受噪声污染的语音片段,通过VTS模型来实现环境鲁棒性的补偿。不仅如此,论文还强调了改方法针对各种统计模型都是有效果的,利用统一的方法就可以实现噪声和信道的重估计。
环境建模
典型的环境噪声是加性和卷积混叠的,为了分析方便往往认为卷积和加性是串联的,如下图【4】:
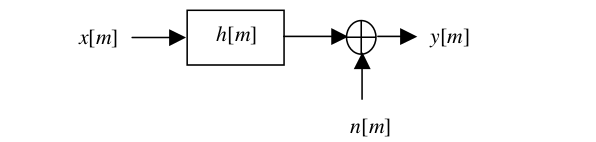
由此对于数字序列来说,得到如下IPO公式:
y
(
m
)
=
x
(
m
)
∗
h
(
m
)
+
n
(
m
)
y(m)=x(m)*h(m) + n(m)
y(m)=x(m)∗h(m)+n(m)变换到频域的功率(幅度平方)表征:
∣
Y
(
f
k
)
∣
2
=
∣
X
(
f
k
)
∣
2
∣
H
(
f
k
)
∣
2
+
∣
N
(
f
k
)
∣
2
+
2
R
e
{
X
(
f
k
)
H
(
f
k
)
N
∗
(
f
k
)
}
|Y(f_k)|^2=|X(f_k)|^2|H(f_k)|^2+|N(f_k)|^2+2Re\{X(f_k)H(f_k)N^*(f_k)\}
∣Y(fk)∣2=∣X(fk)∣2∣H(fk)∣2+∣N(fk)∣2+2Re{X(fk)H(fk)N∗(fk)}
上面这个公式还是容易理解的,但不容易操作,所以假设x(m)和n(m)是统计独立的,最后一项的 期望就是零均值,而经过试验也能证明这一项的误差是可以接受的,所以就大胆的省掉难看的尾项
∣
Y
(
f
k
)
∣
2
=
∣
X
(
f
k
)
∣
2
∣
H
(
f
k
)
∣
2
+
∣
N
(
f
k
)
∣
2
|Y(f_k)|^2=|X(f_k)|^2|H(f_k)|^2+|N(f_k)|^2
∣Y(fk)∣2=∣X(fk)∣2∣H(fk)∣2+∣N(fk)∣2换到对数谱领域,
Y
l
n
=
l
n
(
∣
Y
(
f
k
)
∣
2
)
=
>
∣
Y
(
f
k
)
∣
2
=
e
x
p
(
Y
l
n
)
Y_{ln}=ln(|Y(f_k)|^2)=>|Y(f_k)|^2=exp(Y_{ln})
Yln=ln(∣Y(fk)∣2)=>∣Y(fk)∣2=exp(Yln)进行带入:
l
n
(
e
x
p
(
Y
l
n
)
)
=
l
n
(
e
x
p
(
X
l
n
H
l
n
)
+
e
x
p
(
N
l
n
)
)
=
l
n
(
e
x
p
(
X
l
n
H
l
n
)
)
+
l
n
(
1
+
e
x
p
(
N
l
n
)
e
x
p
(
X
l
n
H
l
n
)
)
ln(exp(Y_{ln}))=ln(exp(X_{ln}H_{ln})+exp(N_{ln}))=ln(exp(X_{ln}H_{ln}))+ln(1+\frac{exp(N_{ln})}{exp(X_{ln}H_{ln})})
ln(exp(Yln))=ln(exp(XlnHln)+exp(Nln))=ln(exp(XlnHln))+ln(1+exp(XlnHln)exp(Nln))经过代数运算得出如下的通用形式,在【4】中给的推导结果如下:
l
n
∣
Y
(
f
k
)
∣
2
=
l
n
∣
X
(
f
k
)
∣
2
+
l
n
∣
H
(
f
k
)
∣
2
+
l
n
(
1
+
e
x
p
(
∣
N
(
f
k
)
∣
2
−
l
n
∣
X
(
f
k
)
∣
2
−
l
n
∣
H
(
f
k
)
∣
2
)
)
ln|Y(f_k)|^2=ln|X(f_k)|^2+ln|H(f_k)|^2+ln(1+exp(|N(f_k)|^2-ln|X(f_k)|^2-ln|H(f_k)|^2))
ln∣Y(fk)∣2=ln∣X(fk)∣2+ln∣H(fk)∣2+ln(1+exp(∣N(fk)∣2−ln∣X(fk)∣2−ln∣H(fk)∣2))这样就可以概括为一个更加通用的表达:
z
=
x
+
f
(
x
,
n
,
h
)
z=x+f(x,n,h)
z=x+f(x,n,h)此处的h参数无法估计,它表达的是在对数频谱(能量谱)域线性滤波的影响【1】。那么VTS算法关键就是拟合这个通用表达。
f
(
x
,
n
,
h
)
≈
f
(
x
0
,
n
0
,
h
0
)
+
d
d
x
f
(
x
0
,
n
0
,
h
0
)
(
x
−
x
0
)
+
d
d
n
f
(
x
0
,
n
0
,
h
0
)
(
n
−
n
0
)
+
d
d
h
f
(
x
0
,
n
0
,
h
0
)
(
h
−
h
0
)
+
.
.
.
f(x,n,h)\approx f(x_0,n_0,h_0)+\frac{d}{dx}f(x_0,n_0,h_0)(x-x_0)+\\ \frac{d}{dn}f(x_0,n_0,h_0)(n-n_0)+\frac{d}{dh}f(x_0,n_0,h_0)(h-h_0)+...
f(x,n,h)≈f(x0,n0,h0)+dxdf(x0,n0,h0)(x−x0)+dndf(x0,n0,h0)(n−n0)+dhdf(x0,n0,h0)(h−h0)+...
在【1】中,作者强调了虽然泰勒(截断)扩展普适性很强,但是如果
x
x
x符合高斯分布,那么围绕均值的扩展将更加具有魅力,所以就可以放心大胆的用截断表达来替换原来复杂的函数,一般用到一阶就够了。
与高斯模型方法的结合
【1】干净语音的统计方法即通过EM算法进行GMM建模,是经典ASR算法的基础。VTS方法试图通过纯净语音的pdf,带噪声音片段和泰勒级数建模纯净和带噪语音的关系,来估计带噪语音的pdf。而一旦带噪语音的pdf参数确定了,就可以利用MMSE方法来预测(不可观测)的干净语音序列。这篇文章还提到了如果利用HMM进行纯净语音的pdf训练,那么泰勒级数就用来估计受噪语音的HMM,从而实现路鲁棒性的语音识别,但没有展开。而针对于降噪方面,假设纯净语音是高斯的,那么VTS扩展同样是高斯的,受噪语音的pdf表示为 p ( z ) = N z ( μ z , Σ z ) p(z)=\mathcal N_z(\mu_z,\Sigma_z) p(z)=Nz(μz,Σz),这时零阶(VTS-0)扩展表示 μ z = E ( z ) = E ( x + f ( n 0 , x 0 , h 0 ) ) = μ x + f ( n 0 , x 0 , h 0 ) Σ z = Σ x \begin{aligned} \mu_z&=E(z)=E(x+f(n_0,x_0,h_0))=\mu_x+f(n_0,x_0,h_0)\\ \Sigma_z&=\Sigma_x \end{aligned} μzΣz=E(z)=E(x+f(n0,x0,h0))=μx+f(n0,x0,h0)=Σx一阶(VTS-1)扩展表示 μ z = E ( x + f ( n 0 , x 0 , h 0 ) ) = μ x + f ( n 0 , x 0 , h 0 ) + E ( d d x f ( x 0 , n 0 , h 0 ) ( x − x 0 ) ) + E ( d d n f ( x 0 , n 0 , h 0 ) ( n − n 0 ) ) + E ( d d h f ( x 0 , n 0 , h 0 ) ( h − h 0 ) ) Σ z = ( I + d d x f ( x 0 , n 0 , h 0 ) ) T Σ x ( I + d d x f ( x 0 , n 0 , h 0 ) ) + ( I + d d n f ( x 0 , n 0 , h 0 ) ) T Σ n ( I + d d n f ( x 0 , n 0 , h 0 ) ) \begin{aligned} \mu_z=&E(x+f(n_0,x_0,h_0))=\mu_x+f(n_0,x_0,h_0)+\\ &E(\frac{d}{dx}f(x_0,n_0,h_0)(x-x_0))+\\ &E(\frac{d}{dn}f(x_0,n_0,h_0)(n-n_0))+\\ &E(\frac{d}{dh}f(x_0,n_0,h_0)(h-h_0))\\ \Sigma_z=&(I+\frac{d}{dx}f(x_0,n_0,h_0))^T\Sigma_x(I+\frac{d}{dx}f(x_0,n_0,h_0))+\\ &(I+\frac{d}{dn}f(x_0,n_0,h_0))^T\Sigma_n(I+\frac{d}{dn}f(x_0,n_0,h_0)) \end{aligned} μz=Σz=E(x+f(n0,x0,h0))=μx+f(n0,x0,h0)+E(dxdf(x0,n0,h0)(x−x0))+E(dndf(x0,n0,h0)(n−n0))+E(dhdf(x0,n0,h0)(h−h0))(I+dxdf(x0,n0,h0))TΣx(I+dxdf(x0,n0,h0))+(I+dndf(x0,n0,h0))TΣn(I+dndf(x0,n0,h0))通过改进的EM算法,就可以估算出带噪的pdf。
利用MMSE方法补偿受噪话音
受噪话音的分布一旦求得,利用下面的公式进行MMSE的纯净语音 估计 x ^ M M S E = E ( x ∣ z ) = ∫ x p ( x ∣ z ) d x = ∫ ( z − f ( x , n , h ) ) p ( x ∣ z ) d x \hat x_{MMSE}=E(x|z)=\int x\ p(x|z)dx=\int (z-f(x,n,h))p(x|z)dx x^MMSE=E(x∣z)=∫x p(x∣z)dx=∫(z−f(x,n,h))p(x∣z)dx零阶下的估计范式为 x ^ M M S E = z − ∑ k = 0 M − 1 f ( μ x , k , μ n , h ) p ( k ∣ z ) \hat x_{MMSE}=z-\sum_{k=0}^{M-1}f(\mu_{x,k},\mu_n,h)p(k|z) x^MMSE=z−k=0∑M−1f(μx,k,μn,h)p(k∣z)但要记住这个估计值是在对数功率谱范式下求得,如果直接进行识别可能最好,但要恢复语音还要进行逆变换。
基于统计模型的梅尔谱维纳滤波
回顾一下加性噪声环境能量谱的公式
∣
Y
(
f
k
)
∣
2
=
∣
X
(
f
k
)
∣
2
+
∣
N
(
f
k
)
∣
2
|Y(f_k)|^2=|X(f_k)|^2+|N(f_k)|^2
∣Y(fk)∣2=∣X(fk)∣2+∣N(fk)∣2
基于此公式的维纳滤波器
G
=
∣
X
(
f
k
)
∣
2
∣
Y
(
f
k
)
∣
2
=
∣
X
(
f
k
)
∣
2
∣
X
(
f
k
)
∣
2
+
∣
N
(
f
k
)
∣
2
G=\frac{|X(f_k)|^2}{|Y(f_k)|^2}=\frac{|X(f_k)|^2}{|X(f_k)|^2+|N(f_k)|^2}
G=∣Y(fk)∣2∣X(fk)∣2=∣X(fk)∣2+∣N(fk)∣2∣X(fk)∣2。首先论文【6】提出了梅尔谱(对数能量谱)的维纳表达
G
t
,
l
=
e
x
p
(
S
t
,
l
)
/
e
x
p
(
O
t
,
l
)
≈
e
x
p
(
S
t
,
l
)
e
x
p
(
S
t
,
l
)
+
e
x
p
(
N
t
,
l
)
G_{t,l}=exp(S_{t,l})/exp(O_{t,l})\approx\frac{exp(S_{t,l})}{exp(S_{t,l})+exp(N_{t,l}) }
Gt,l=exp(St,l)/exp(Ot,l)≈exp(St,l)+exp(Nt,l)exp(St,l)
这个增益是作用在梅尔滤波器bin上的。但是实际上纯净的对数梅尔谱
S
t
,
l
S_{t,l}
St,l是无法求的,所以利用统计模型求出纯净语音的均值方差,利用
μ
S
t
,
k
,
l
\mu_{S_{t,k,l}}
μSt,k,l来替换
S
t
,
l
S_{t,l}
St,l,
N
t
,
l
N_{t,l}
Nt,l也可以估计出来,这样就能够得到基于统计模型的梅尔谱维纳滤波增益函数
G
^
t
,
k
,
l
=
e
x
p
(
μ
S
t
,
k
,
l
)
/
e
x
p
(
μ
O
t
,
k
,
l
)
\hat G_{t,k,l}=exp(\mu_{S_{t,k,l}})/exp(\mu_{O_{t,k,l}})
G^t,k,l=exp(μSt,k,l)/exp(μOt,k,l)后验概率
p
(
k
∣
O
t
)
p(k|O_t)
p(k∣Ot)加持下,可以得到估算的增益:
G
^
t
,
l
=
∑
k
=
1
K
p
(
k
∣
O
t
)
G
^
t
,
k
,
l
\hat G_{t,l}=\sum_{k=1}^Kp(k|O_t)\hat G_{t,k,l}
G^t,l=k=1∑Kp(k∣Ot)G^t,k,l
一个简单条件概率公式表达【6】:
p
(
k
∣
O
t
)
=
N
(
O
t
;
μ
o
t
,
k
,
Σ
o
t
,
k
)
∑
i
=
1
K
N
(
O
t
;
μ
o
t
,
i
,
Σ
o
t
,
i
)
p(k|O_t)=\frac{\mathcal N(O_t;\mu_{o_{t,k}},\Sigma_{o_{t,k}})}{\sum_{i=1}^K\mathcal N(O_t;\mu_{o_{t,i}},\Sigma_{o_{t,i}})}
p(k∣Ot)=∑i=1KN(Ot;μot,i,Σot,i)N(Ot;μot,k,Σot,k)
参考文档
1. A vector Taylor series approach for environmentindependent
speech recognition, P. J. Moreno, et al.,
2.基于矢量泰勒级数的鲁棒语音识别
3.Taylor series expansion
4.HMM ADAPTATION USING VECTOR TAYLOR SERIES FOR NOISY SPEECH RECOGNITION, Alex Acero, Li Deng… Microsoft Reseach
[5.Model-based compensation of the additive noise for continuous speechrecognition. Experiments using the AURORA II database and tasks]
[6.A study of mutual front-end processing method based on
statistical model for noise robust speech recognition]















 2355
2355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









