



 BA-Net是一种针对医学图像分割的深度学习模型,通过边界感知上下文神经网络解决病变区域的大小和形状差异以及低对比度带来的分割挑战。文章介绍了PEE模块用于提取边界信息,mini-MTL进行多任务学习增强特征,IA模块利用互动注意力整合任务信息,CFF模块则融合不同层级的特征。最终,解码器结合这些特征进行分割预测,整体提升了分割性能。
BA-Net是一种针对医学图像分割的深度学习模型,通过边界感知上下文神经网络解决病变区域的大小和形状差异以及低对比度带来的分割挑战。文章介绍了PEE模块用于提取边界信息,mini-MTL进行多任务学习增强特征,IA模块利用互动注意力整合任务信息,CFF模块则融合不同层级的特征。最终,解码器结合这些特征进行分割预测,整体提升了分割性能。
前言
Boundary-aware context neural network for medical image segmentation给我最深的印象就是他的注意力模型,就是他处理各层之间的信息交互和不同任务之间信息交互时候用的注意力模块处理的很简单,效果也很好。比较好的利用了上下文。
论文地址:https://arxiv.org/abs/2005.00966v1
代码:https://github.com/mathwrx/BA-Net
我就不按文章结构来了,也差不多。
一、解决什么问题?
问题:医学分割
医学分割的难题:
1.病变区域对于不同的个体具有不同的大小和形状。
2.病变与背景的低对比度也给分割带来了很大的挑战。
那这篇论文具体是解决什么问题?(如何学习更丰富的上下文仍然是分割算法提高识别性能。)
传统图像分割方法存在的问题:1)传统方法往往设计低级手工特征,进行启发式假设,这通常会限制复杂场景下的预测性能。此外,忽略了原始图像中丰富的可用信息。2)对伪影、图像质量和强度不均匀性的鲁棒性较低,这在很大程度上取决于有效的预处理。
现在用了DeepLearning后的医学分割:成功克服了传统手工制作的限制。现在方法的问题:不准确的对象边界和不满意的分割结果。原因:由于上下文信息有限,连续池化和卷积操作后的判别性特征图不足。
So总体而言,如何学习更丰富的上下文仍然是分割算法提高识别性能。
二、那怎么设计解决的
他们使用了BA-Net。在编码器每一层使用PEE(在多个颗粒度下获得边的信息,为分割目标对象提供互补线索),设计了MTL(为了丰富编码器每个层的采样信息,训练期间联合监督分割和边界图预测。)提出IA,充分利用不同人物之间的信息去监督目标区域识别的模型。最后CFF是有选择地聚合整个编码其中地不同层地特征(更好地获得上下文信息,并且保留空间信息。)解码器我们对特征图进行整合按顺序地获得分割预测地结果。
三、他们做了什么?贡献是什么?
- 提出了一个新的边界感知上下文神经网络。
- 设计了有嵌入交互式注意PEE,mini-MTL的模块,充分挖掘同一层次的上下文特征,有效利用边界信息为更好的分割预测提供强有力的线索。
- 建立了CEE模型可以有选择和聚合交叉级特征。
4.做了详尽的实验在不同的分割任务上获得了先进的分割表现
四、仔细讲一下方法?
好哒!(●’◡’●)

总体来说,我们提出的BA-Net是基于ResNet作为骨架(去掉了其中的全局池化和全连接层)。编码器的主体是一个卷积层4个残差层。在最后两个残差层我们去掉了池化,用ASPP代替,增大了感受野的同时保持了和没有去掉池化层之前一样的分辨率。介绍一下ASPP。在编码器的每个阶段,定制三个模块来充分挖掘同一层次的特征并举和来自不同层次的其他特征。解码器部分,通过聚合ASPP模块的输出特征图,编码的每个阶段的特征获得解码器的特征,以进行最终的分割预测。
4.1 PEE

猛一看以为全是残差,其实它圆圈里的是减号。
先讲一下,PEE。尝试理解一下公式。┭┮﹏┭┮
病变区域的边界很重要,但是病变区域的边界通常是复杂多样的。->获得一个强大的边界信息补充,我们设计了一个简单有效的PEE。(背景)
PEE的输入:骨干网络的每一层的最后的残差模块输出的特征图用1X1conv压缩到Fi i∈{1,2,3,4}。通过从其局部卷积特征图中减去具有不同大小的平均池化值来边缘特征的多粒度边缘特征。这个图里面的avg就是池化。然后把所有的这些输出与输入聚合起来,再用1x1卷积进行融合。这样一个多粒度边缘特征提取设计为高效提升相应水平的表示能力提供了有力的途径。通过提取和集成不同粒度的边界信息,有效改善边缘特征并抑制噪声。随后,输出图被馈送到迷你多任务模块,以促进更精细特征的提取。
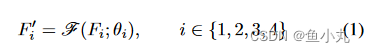
Fi是PEE的输入,那个函数是1x1conv,Fi’是输出。这个就代表进行了1次1x1conv,进行了特征图的压缩。
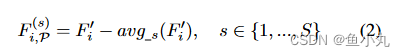
avg代表池化,这个就是上面那个图上的减法运算。
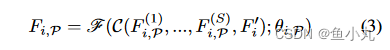
C就是连接concat,然后进行1x1conv。
4.2 mini-MTL

(光看这个图,有一个上下的交互。这是充分利用多任务的优点吗?有一个Interactive attention内部注意力。supervise是不是和监督有关系。)
PEE的输出进入到了mini-MTL。这个模块怎么想到的。
察觉到了:语义分割和边缘检测有很强的互补性。为了:不引入太多参数的情况下对目标进行分割和边界检测。目的:利用这些相关任务之间的潜在相关性,实现性能提升。这个模块的组成有两部分,特定于任务的分支和交互式注意力层。每一个任务分支有两个卷积层(编码相关任务的特征)和一个上采样层(获取相应的预测编码)。IA在第一个卷积层,用于从不同任务中挖掘交互式信息
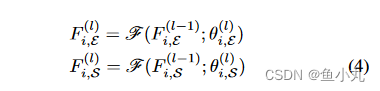
这里的这个函数代表进行3x3Conv,从第l-1层变到l层。
4.3 IA

(看这个图,它用上面的输入用sigmoid函数等生成一个权重矩阵与下面输入相乘然后与上面输入相加,得到上面任务在这一模块的输出。)
(✿◕‿◕✿)下面就是minMTL模块中的IA模块了。我们首先使用sigmoid函数生成一个权重掩码,它指示当前边缘特征图FE的重要位置,反向注意力权重就是1-这个权重掩码。最后,通过逐元素乘积操作,我们可以选择性地将分割特征中的有用信息发送给当前的边缘特征。E是边缘,S是分割。所提出的IA模块基于无附加参数的门控机制,通过这种方式,来自不同任务的信息由IA模块有效地传递。此外,有用的信息可以通过注意力调节到正确的位置,并且还可以同时在发送方和接收方抑制无用的消息。通过两个卷积层和一个交互层,聚合这两个任务的特征,我们得到了丰富当前层的上下文表示 。
下面说了用BCELoss计算两个任务的损失,把这两个任务相加就得到了整个的Loss函数。
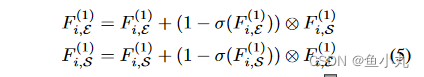
这个公式就很好的表现了IA的图。就是边缘特征是边缘提取那个分支的输入加上权重矩阵乘以分割分支的输入(权重矩阵就是1-sigmoid(边缘的输入))。
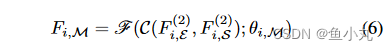
通过聚合这两个任务的特征,丰富当前阶段的上下文表示 。这个Fi,M就是Mini-MTL中的那个最后蓝色的块。

两个任务的BCELoss。
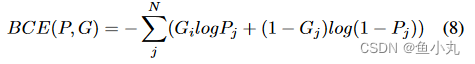
BCELoss的函数。
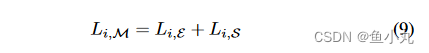
我们这两个任务的联合损失就是这两个任务的Loss相加。
4.4 CFF

(光看这个图,所有层的特征图取sigmoid作为它们的权重矩阵与自身相乘得到一个输出,这个输出乘上当前层的反注意力矩阵然后与当前层相加得到最后这个模块的输出。)
(❤´艸`❤)是怎么想出来的呢?低级特征空间细节丰富,高级特征语义信息更丰富。为了充分利用空间信息和语义信息,提出了跨特征融合模块(CFF)。
CFF选择性地聚合不同层次的特征,并细化了高级和低级特征图。CFF通过以下注意机制自适应地从多个输入特征中选择互补分量。
CFF模块将不同层次的信息进行有效整合,可以有效避免引入过多的冗余信息。因此,我们可以通过三个串联模块获得丰富的上下文特征Fi,C,在每个阶段保留丰富的细节和语义信息,用于解码器过程。
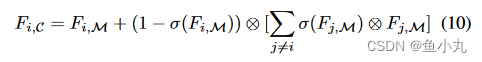
这个就是CFF的公式。
4.5解码器和优化器
解码器和优化器。解码器阶段我们通过聚合ASPP模块输出的特征映射FA并依次编码每个阶段的特征来获得解码特征,以得到最终分割输出。
整个网络的监督采用标准二进制交叉熵损耗,使解码器网络输出与地面真实值的误差最小化。端到端训练的时候,多任务模块的联合损失定义是解码器的损失+其他任务的损失*平衡参数,平衡参数按经验一般设置为1。
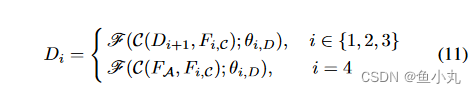
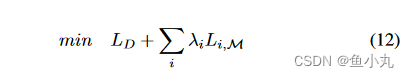
如果是多个任务的话,联合损失函数的定义。
总结
这篇论文写的简单易懂,非常推荐。之后进行代码复现,学习一下代码。
我是小白,有错误指正,谢谢!

















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









