







最近工作涉及到文本分类问题,就尝试用了一下fastText库,fastText是facebook开源的一个词向量计算以及文本分类工具库,准确率比肩深度学习。如其名,fastText在训练时贼快,这也是该库最大的优势,相比cnn动辄几小时、十几小时的漫长训练过程,fastText只需几分钟就训练完成,比如我训练使用280万左右数据,30个分类,不到1分半钟就训练完成。该库已经开源,c++和python版本均有,原始代码由c++编写,默认开发环境为linux,如果是windows开发环境,可以自己使用vs创建工程,然后将源码依次移植过来,就可以编译调试了。这里有一点需要注意,我按照tutorials/supervised-learning.md文档步骤训练时,如果训练集是中文,会出现乱码问题,将训练集文件编码修改为ansi就可以了。如果使用python版本训练,则需要linux运行环境,python版本的库在windows下执行,计算的准确率及召回率都是NaN。由于该库已经有很多博客介绍过,无论从理论上还是源码分析,都可以找到很多好文章,下面是一些参考文章:
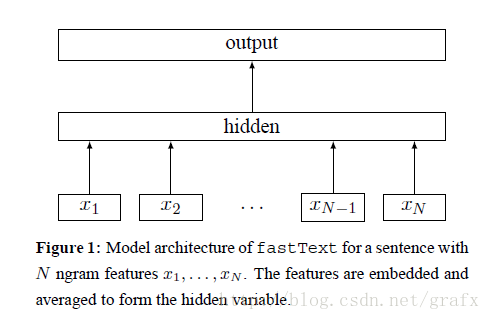
fastText源码由c++编写,有些地方用到了c++ 11中的一些知识点,并且注释非常少,读起来有些晦涩。首先要清楚的是输入与输出,这里以文本分类为例,可以直接定位到FastText::train()函数,该函数首先读取训练集,完成词表的构建,词表可以看做是一个巨大的集合,训练集文本中所有词都保存在词表内,在构建过程中还会计算每个词的数量、索引、类型(语料还是标签)。随后的代码主要是定义输入、输出矩阵,搞清楚算法输入与输出后,在结合算法流程图就好懂多了。关于输入矩阵,相信很多人会有疑惑,既然初始输入都是随机值,那么我们训练集中的文本起了什么作用,貌似啥作用也没有起,好像没有参加任何加减乘除运算,但是实际上在词向量空间中,这些相似的文本有近似的词向量,这些近似的词向量又对应相同的分类标签,在迭代训练过程中,这种相关性会不断传播,直至训练出准确的分类模型。


如果选用层次softmax训练,还需要以每个标签的数量为权重,构建霍夫曼树,叶子节点就是标签,该方法可以加快训练过程。如果用普通softmax训练,每个标签都需要计算,而采用霍夫曼树,标签数量多,权重就高,霍夫曼编码自然就越短,这样按照霍夫曼编码路径计算标签,就可以极大减少计算量。这一步有两个输出:paths和codes,codes保存的是霍夫曼编码,paths保存的是编码路径每个父节点对应的编号,这个编号在计算输出矩阵时会用到(也就是输出矩阵的行号 )。训练过程的大部分运算集中在void Model::update()方法内,上面我的参考文章已经讲解很清楚了,我这里仅仅补充一下我在看源码时的一些疑惑。最后,简单说一下使用fastText的感受,该库很简单、轻量,训练速度快,准确度可以接受,不需要额外训练词向量,用起来很方便。在补充一下,如果训练时设置了word_ngrams参数(默认为1,可以设置为2,以提升准确率) ,需要同时显示的设置bucket参数,否则会提示内存不足。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









