






片上网络拓扑结构: 潜力、技术挑战、最新进展和研究方向
摘要
集成技术的进步对系统级芯片(SoC)产生了影响,在单个芯片上支持异构内核。在支持大量异构内核的基础上,必须在系统设计的各个层面考虑相关处理器之间的高效通信,以确保全局互联。这可以通过设计友好、灵活、可扩展和高性能的互连架构来实现。值得注意的是,芯片上多个内核之间的互连在吞吐量、端到端延迟和数据包丢失率方面对芯片设计的性能和通信有相当大的影响。虽然分层架构解决了传统互连技术的大部分相关难题,但主要限制因素是可扩展性。片上网络(NoC)作为一种可扩展、结构良好的替代解决方案,能够解决片上系统中的通信问题。在此背景下,人们提出了几种 NoC 拓扑,以支持各种路由技术并满足不同的芯片架构要求。本书的这一章回顾了一些现有的 NoC 拓扑及其相关特性。此外,还考虑了 NoC 的应用映射算法和一些关键挑战。
1. 1. 引言
分布式或并行系统一直是满足需要大量计算的应用需求的主要方法。在这些系统中,许多处理元件通过互连网络连接在一起。值得注意的是,传统的片外架构中,不同的处理元件相互连接,无法满足可扩展性、高吞吐量和低功耗的要求。这是由于现有计算机芯片的延迟和硬件复杂性增加所致[1, 2]。
现代应用和服务对计算能力的要求不断提高,使研究重点转向半导体技术的改进。这导致了片上网络的发展。与片外网络相比,片上网络具有占用空间小、功耗低等显著特点,因此受到越来越多的关注。片上系统(SoC)和多处理器片上系统(MPSoC)就是这种片上架构的实例[3]。
此外,各种片上网络组件通过共享总线和总线等各种互连网络进行连接。在基于总线的拓扑结构中,设备之间的通信通常通过总线链路进行,而在共享总线拓扑结构中,则采用线集合。相比之下,共享总线架构提供了低成本的解决方案和简单的控制功能。这些优点使共享总线网络成为片上集成处理单元间通信的首选架构[1, 4]。
此外,由于知识产权(IP)内核和其他片上资源的数量不断增加,基于总线的 SoC 要满足不同应用的要求具有挑战性[2]。此外,混合处理网元还提出了多样化的通信要求。这些限制主要是由于基于总线的互连架构无法提供支持大量片上资源所需的延迟、可扩展性、带宽和功耗。因此,SoC 架构要满足这些要求具有挑战性。实施片上网络(NoC)可有效解决片上通信瓶颈问题。与基于总线的 SoC 相比,NoC 除了能解决总线架构延迟和拥塞相关问题外,还能以更低的功耗和更高的效率满足通信要求 [1、4、5]。
本章全面概述了 NoC 架构的演变及其相关特性。在这方面,本章重点关注拓扑、路由和交换等一些主要且有前景的片上研究领域。此外,还介绍了用于提高片上性能的不同应用映射算法。此外,本章还讨论了片上通信设计和实施中的未决问题。本章内容安排如下。第 2 节对 SoC 进行了全面讨论,重点介绍了片上互连的发展。第 4 节深入讨论了典型的 NoC 架构组件。此外,还讨论了基于 NoC 的应用任务表示和应用映射。第 5 节重点介绍了各种 NoC 拓扑性能评估和一些模型指标。第 6 节还讨论了片上方案面临的相关挑战,第 8 节给出了结束语。
2. 片上系统
本节重点介绍片上互连的发展。从概念上讲,片上系统包括嵌入在硬币大小的小芯片上并与微处理器或微控制器集成的电路。此外,在 SoC 中,单个芯片被划分为功能块和互连(通信)网络。根据不同的应用,SoC 设计通常包含存储设备、RAM/ROM 存储块、中央处理器(CPU)、输入/输出端口和外围接口,如定时器、集成电路(I2
C)、通用异步接收器/发送器(UART)、图形处理器(GPU)、控制器区域网络(CAN)、串行外设接口(SPI)等外设接口。此外,还可根据要求加入浮点运算单元、模拟或数字信号处理系统。
此外,通过创新的集成技术,单个芯片可支持大量异构内核 [6,7]。因此,在设计这种芯片时,多个内核之间的互连对系统性能和通信有相当大的影响。例如,片上通信架构除了负责所有内存事务外,还负责 I/O 流量管理。此外,它还为处理器之间的数据共享提供了可靠的通道。因此,在 SoC 设计中,高性能和可扩展的片上通信是非常必要的[8]。然而,在片上组件之间实现高效通信是一项挑战[1, 2, 4, 8]。图 1 展示了片上互连架构的演变。
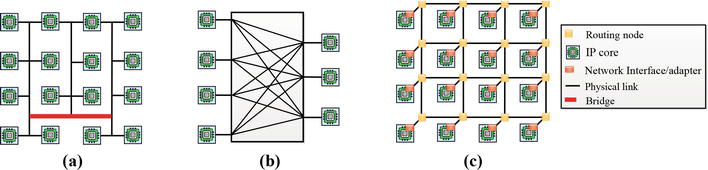
Figure 1.On-chip interconnect architectural evolution: (a) bus, (b) crossbar, and (c) 4×44×4 mesh-based NoC.
2.1 总线架构
如前所述,传统的片上总线互连技术之所以得到广泛应用,部分原因是其协议和架构设计简单。总线拓扑的其他显著特点是低面积开销和可预测的延迟。例如,基于总线的互连主要适用于片上元件数量较少的情况。此外,它不仅功耗低,而且硅成本低[1, 4, 8]。
此外,如图 1(a)所示,该架构使用单一控制/数据总线来支持多个组件的交互。这有助于确保简单的主从连接。此外,在基于总线的架构中,当多个主站需要与同一个从站通信时,也会出现资源争用的情况。在这种情况下,需要进行仲裁以确保有效通信。因此,在大型 SoC 中,基于总线架构的可扩展性具有挑战性 [8]。
2.2 交叉条(矩阵交换结构)架构
如 2.1 小节所述,当需要支持多个主从数据交易时,单个共享总线架构由于相关延迟而不是合适的解决方案。这是因为共享介质上的主接口之间需要进行仲裁。因此,可以采用交叉条拓扑结构来解决片上互连的可扩展性问题。如图 1(b) 所示,交叉条架构由矩阵交换结构组成。为促进多重通信,该矩阵将整个输入端与整个输出端连接起来。基于交叉条拓扑结构的优势,SoC 设计人员通过合并多条共享总线来实现全输入-全输出的连接矩阵[8, 9]。然而,由于导线布局复杂,基于交叉条的架构设计复杂度较高[8]。
2.3 片上网络架构
NoC 提供了另一种模块化平台,具有很高的可扩展性。此外,它还支持高效的片上通信,有利于基于 NoC 的多处理器架构实现高功能多样性和结构复杂性[3]。这使它成为高度集成 SoC 架构的事实上的片上通信标准。此外,无论网络大小如何,它都能通过流水线方式支持并行(多并发)通信。此外,在 NoC 中,不是在所有 IP 块之间建立连接,而是在芯片内创建网络。这使得每个 IP 都能发挥网络节点的作用。例如,为确保有效通信,采用路由器网络连接相关的巨大内核。在这方面,SoC 中的总线已被路由器网络取代,路由器网络负责控制已建立网络中节点之间的通信过程。在此基础上,NoC 呈现出低延迟、高带宽和可扩展性等一系列特点 [10,11]。
在 NoC 中,互连被适当地组织起来,形成合适的拓扑结构。此外,其中的通信通常在 IP 内核之间进行,并符合所采用的拓扑结构。而且,这可以通过异步或同步模式来实现[11]。因此,在这些拓扑结构中,节点之间的数据包路由可以采用某些路由技术[10]。如图 1(c) 所示,数据包路由需要路由器和通道(互连链路)等组件 [11]。值得注意的是,有些路由技术是专门为 NoC 设计的。因此,这些技术经过精心设计,无死锁1 [10]。
此外,图 1(c) 展示了一个 4×4网状 NoC 架构,该架构通过常规尺寸的导线和路由器连接多个处理内核/处理元件(PE)。PE 可以是特定应用集成电路 (ASIC) 块和微处理器等组件 [12]。此外,还可以使用不同类型的内核,如管理器、常规内核和备用内核。而且,根据应用的不同,这些内核可以是同构的,也可以是异构的。常规内核通常执行指定应用的任务,备用内核是额外的内核,可在常规内核或管理器内核出现故障时使用,而管理器内核用于跟踪和管理所有处理内核。此外,当处理核心出现故障时,管理核心会执行任务迁移[13]。
此外,值得注意的是,在 NoC 架构中遇到的设计问题与基于总线的架构类似。在这种情况下,要建立一个能满足特定应用要求的通信结构,就需要在可靠性、功耗、面积、成本和性能之间进行权衡[12]。例如,表 1 列出了共享总线、分段总线、点对点和 NoC 互联的渐近成本函数,以及 n 个系统模块的渐近成本函数如表 1 所示。这表明,随着 n时,NoC 架构的功耗更低、所需布线面积更小、工作频率更高,因此是一种可扩展且极具吸引力的架构 [14]。
| Power Dissipation | Operation Frequency | Total area | |
|---|---|---|---|
| Shared bus | O(nn−−√)Onn | O(1n2)O1n2 | O(n3n−−√)On3n |
| Segmented bus | O(nn−−√)Onn | O(1n)O1n | O(n2n−−√)On2n |
| Point-to-Point | O(nn−−√)Onn | O(1n)O1n | O(n2n−−√)On2n |
| NoC (Mesh) | O(n)On | O(1)O1 | O(n)On |
Table 1.Asymptotic cost functions for interconnection architectures.
3. 先进的片上总线架构
由于不同供应商提供的各种 IP 具有不同的标准接口,芯片设计人员必须通过通用标准或内部接口进行连接。因此,灵活、开放的 IP 核接口标准对于实用的片上互连设计和 SoC 集成至关重要。这可以通过采用标准接口协议来实现,这些协议可提供可重复使用的配置文件,支持各种片上互连设计和 SoC 集成。此外,片上互连的运行还取决于总线架构的效率。因此,具有额外数据传输周期、更快的时钟速度、更强的吞吐量和宽度的总线架构对于缩短产品上市时间、降低成本和提高 SoC 效率极具吸引力。本节将概述标准片上总线结构和协议,如 ARM 高级微控制器总线架构 (AMBA)、IBM CoreConnect 和 Altera Avalon。
3.1 基于 AMBA 的总线协议架构
AMBA 总线协议是 ARM 的互连规范,用于多个功能块之间的片上通信。在这些设计中,一个或多个微处理器/微控制器可与其他各种组件和外设集成在一个芯片上。图 2 描述了基于 AMBA 2.0 的传统 SoC 设计,该设计采用高级系统总线 (ASB) 或高级高性能 (AHB) 协议和高级外设总线 (APB) 协议,分别用于高带宽和低带宽外设互连[15]。
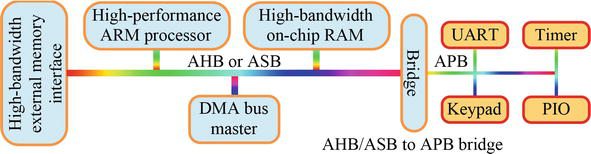
Figure 2.A typical AMBA based SoC design. PIO: Peripheral I/O, UART: Universal asynchronous receiver/transmitter.
此外,为了提高连接性并解决 AHB/ASB 协议可有效支持的 IP 数量的限制,AMBA 3 提出了用于点对点连接协议的高级可扩展接口(AXI)互连。AXI 协议的一些主要特点包括:可发布多个未完成事务、使用字节选通进行非对齐数据传输、控制/地址和数据阶段分离、同时读写数据通道以保证低成本直接内存访问(DMA),以及无序数据功能。图 3 显示了 AXI 互连,使 IP 能够通过主从协议进行通信。值得注意的是,可以采用能够支持多个 AXI 主站和从站的互联设计,如交换机设计、常规交叉条或离线 NoC。此外,APB 总线上支持的外设阵列通过 AXI 到 APB 桥接器连接[15, 16]。
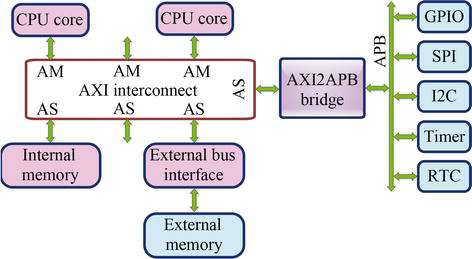
Figure 3.An AXI interconnect. GPIO: General purpose input/output.
此外,智能手机等便携式移动设备中的 SoC 配备了双核/四核/八核处理器和共享集成缓存,这就要求在内存子系统中实现硬件管理的一致性,因此在 AMBA 4 中开发了 AXI 一致性协议扩展 (ACE)。 此外,随着当前为提高数据中心、并行和高性能计算 (HPC) 应用性能而采用异构计算的趋势,需要大量异构计算元件、处理器内核和 IO 子系统。为了支持这些要求,AMBA 5 协议中提出了相干集线器互连(CHI)协议,以改进 AXI/ACE 协议设计。例如,为了获得更好的可扩展性,AXI/ACE 中基于信号的相关协议被改为 CHI 中基于数据包的分层协议。支持的部分功能包括高速缓存存储、高速缓存去分配事务、原子事务和持久高速缓存维护操作(CMO)。其他具有额外高效翻译服务和更高性能的 AMBA 规范是分布式翻译接口(DTI)和本地翻译接口(LTI)协议[16, 17]。
3.2 WishBone 总线协议架构
WishBone 互联主要侧重于设计重用,通过在 IP 核之间建立通用接口来解决集成问题。这有助于提高系统的可移植性和可靠性。这种互连包括两个接口,即主接口和从接口。IP 是主接口,可以启动总线周期。同时,从接口接受启动的总线周期。此外,它的硬件实现与数据流、交叉条交换、共享总线和点对点等各种互连兼容[16]。
此外,WISHBONE 还规定了单一、简单、逻辑、同步的主/从总线和 IP 核接口,只需很少的逻辑门。此外,它还支持一些标准数据传输协议,如 BLOCK READ/WRITE 循环、SINGLE READ/WRITE 循环和读-修改-写(RMW)循环。此外,相关的流量控制和内核之间的通信也可通过握手机制实现。此外,它的多处理能力可实现广泛的 SoC 配置[17, 18]。
3.3 开放内核协议
开放内核协议(OCP)是一种开放标准、非专有、以内核为中心的协议,用于满足 IP 内核系统级集成的要求。同时,它定义了一个时钟系统,提供单向数据传输,有助于简化内核集成、实施和时序分析。此外,基于其高度的可配置性和灵活性,它支持独立的 IP 内核设计,促进了 IP 的重复使用。在此基础上,它增强并确保了 IP 模块化,无需重新设计。此外,所有测试/调试和边带信号都由 OCP 提供,用于保护或中断等多种功能。此外,它的某些功能和信号是可选的。这有助于用户选择最适合其 IP 核的配置[17]。
跨片上互连的典型 OCP 操作如图 4 所示。在这种配置中,IP 核中集成了一个 OCP 主/从元件。实现过程包括一个请求通道和一个响应通道。主 IP 核发出读取命令,导致请求通道上的传输。在响应通道上,从 IP 核对主 IP 核做出响应。此外,OCP 协议支持的一些扩展包括突发数据传输、数据握手扩展、失序响应和测试控制扩展 [16]。
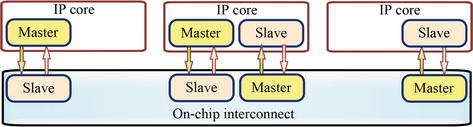
Figure 4.Typical block diagram of OCP.
3.4 IBM CoreConnect 架构
IBM CoreConnect™ 架构是另一种开放式片上总线结构,为高效实现复杂的 SoC 设计提供了框架。如图 5 所示,它有三个独立的总线用于内核、定制逻辑和库宏的互连,即片上外设总线 (OPB)、处理器本地总线 (PLB) 和设备控制寄存器总线 (DCR)。该架构可用于高性能嵌入式应用、存储、网络、有线/无线通信和低功耗普适应用中不同客户和特定应用的 SoC 设计。在这种情况下,高性能外设可以连接到低延迟、高带宽的 PLB。此外,设备步进外设内核通常连接到 OPB。这有助于减少 PLB 上的流量,从而提高系统性能。此外,DCR 总线还为控制、初始化和状态信息提供了相对低速的数据路径 [16,18]。
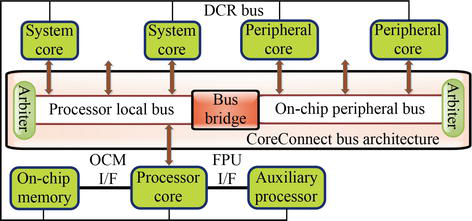
Figure 5.Typical block diagram of CoreConnect.
3.5 Altera Avalon 架构
Avalon 提供了一种简单的总线架构,用于将片上外设和处理器连接到可编程系统芯片(SOPC)。同时,所提供的接口定义了连接主从组件的端口以及组件通信的时序。此外,它还支持多个主站,为 SOPC 系统的构建提供了灵活性。在主站和从站的交互中使用从站端仲裁。因此,如果多个主站试图同时访问同一个从站,从站侧仲裁逻辑会控制哪个主站获得从站访问权,以完成请求的事务。图 6 展示了 Avalon 总线模块的典型框图,其中包含一系列连接的外设 [17,19]。
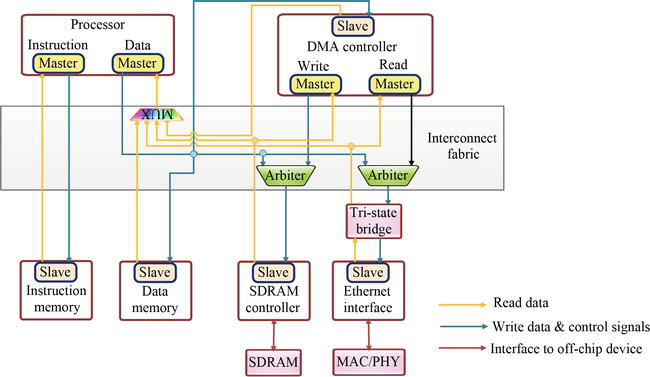
Figure 6.Typical block diagram of Avalon.
此外,Avalon 总线模块包括数据、地址和控制信号,以及连接外设组件所需的仲裁逻辑。此外,其操作还包括用于选择外设的地址解码和用于支持慢速外设的等待状态生成。此外,除了简单和优化资源利用外,总线还提供同步操作和动态大小。主外设和从外设之间还可以实现不同的事务处理。同样,总线还支持多总线主控、流式外设和延迟感知外设等不同的高级功能。因此,在单个总线事务中,外设之间可以传输多个数据单元 [18,19]。表 2 比较了不同的 SoC 总线。
| Protocol | Bus Owner | Bus Topology | Arbitration | Bus Width (bits) | Transfers | |
|---|---|---|---|---|---|---|
| Data | Address | |||||
| AXI | ARM | Bus-Matrix & Hierarchical | Static Priority, TDMA, Lottery, Round-Robin, Token-passing and CDMA | 8, 16, 32, 64, 128, 256, 512, or 1024 | 32 | Handshaking, Split, Pipelined and Burst |
| Wishbone | OpenCores.org & Silicore Cooperation | Point-to-Point, Crossbar Connection, Shared & Data-flow Interconnection | Static Priority, TDMA, Lottery, Round-Robin, Token-passing and CDMA. | 8,16,32,64 | 1–64 | Handshaking & Burst |
| OCP | OCP Int. Partnership | Interconnect Topology | Vary depending on logic on the bus side of OCP. | Configurable | Configurable | Handshaking, Split, Pipelined & Burst |
| Avalon | Altera | Point-to-Point, Pipelined, Multiplexed | Static Priority, TDMA, CDMA, Round-Robin, Lottery, Token-passing | 1–128 | 1–32 | Pipelined and Burst |
| CoreConnect | IBM | Hierarchical | Static Priority | PLB (32, 64, 128 or 256); OCB (8, 16 or 32) and DCR (32) | PLB and OPB (32) and DCR (10) | Handshaking, Split, Pipelined and Burst |
Table 2.Comparison of SoC busses.
4. 片上网络组件
如上所述,NoC 中采用了路由器网络来控制节点间的通信过程。针对 NoC 架构提出了多种拓扑结构和不同的路由算法。值得注意的是,网络拓扑选择是网络设计的首要步骤。此外,流量控制技术和路由策略在很大程度上取决于拓扑结构。本节重点介绍网络拓扑、交换和路由算法等典型架构组件。此外,还介绍了任务表示和应用映射。
4.1 片上网络拓扑结构
NoC 拓扑表示其架构的物理组织,是一个关键的设计标准。在这种情况下,NoC 元素互连的方式是其特征。NoC 被认为是基于规则瓦片的拓扑结构,适用于连接同质内核。此外,为支持具有不同尺寸、功能和通信要求的异构内核,基于定制、特定领域的不规则拓扑结构也备受关注[3]。本小节将讨论其中一些拓扑结构。
4.1.1 常规拓扑
在常规拓扑中,可以预测功耗和网络区域的可扩展性会随着规模的增加而增加。需要注意的是,常规网络拓扑通常适用于大多数 NoC [20]。本小节重点介绍最常用的常规拓扑结构及其优缺点。
4.1.2 环形拓扑:
环形拓扑是广泛采用的 NoC 拓扑之一。在这种拓扑结构中,每个节点只用一根线连接。因此,无论环的大小如何,每个节点都有相邻的节点,如图 7(a) 所示。因此,在环形拓扑中,每个节点的阶数2 都是2。这意味着每个节点都有相应的可用带宽。虽然环形拓扑的部署和故障排除相对更容易,但它的主要缺点是其直径会随着节点数量的增加而增大。因此,除了网络扩展会降低性能(可扩展性问题)外,环形拓扑还容易出现单点故障(路径多样性差)[1, 21]。
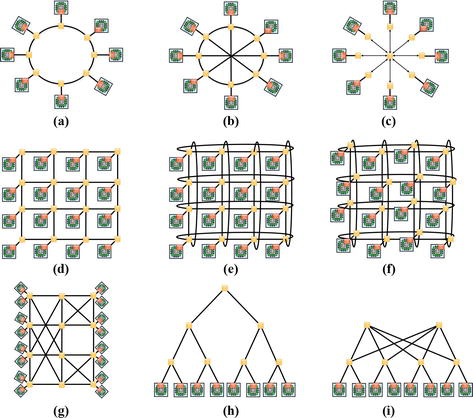
Figure 7.NoC topologies: (a) ring, (b) octagon (c) star, (d) 4×44×4 mesh, (e) 4×44×4 torus, (f) 4×44×4 folded torus, (g) butterfly, (h) binary tree, (i) fat tree.
4.1.3 八边形拓扑
另一种流行的 NoC 拓扑是八边形。典型的八边形拓扑包括八(8)个节点和十二(12)个双向链路。此外,与环形拓扑结构一样,每个节点都与前一个节点和后一个节点相连。因此,节点对之间有两跳通信。同时,网络之间的数据包路由可以采用简单的最短路径路由。此外,与共享总线拓扑相比,可以实现更高的总吞吐量。此外,该架构可以连接起来,以支持更大的设计,从而实现更好的可扩展性。
4.1.4 星型拓扑
图 7(c) 所示的星形拓扑结构是将所有节点连接到一个中心节点。假设 N个节点,其中 N-1个节点连接到中心节点。在这种结构中,中心节点的阶数为 N-1因此,无论其大小如何,星形拓扑的直径都是 2。在这方面,它的主要优点是提供了简单性,并且由于相关的直径较小,最小跳数为 2 [21]。虽然节点是分开的,不会受到故障节点的潜在影响,但中心节点故障会导致整个网络瘫痪。此外,随着节点数量的增加,中心节点的直径也会增加,中心节点可能会出现通信瓶颈[1]。
4.1.5 网状拓扑结构
网状结构是广泛采用的互连拓扑结构。典型的 4×4网状拓扑图如图 7(d) 所示。除了边缘的路由器外,网状拓扑中的每个路由器都通过通信通道与一个计算资源和四个相邻路由器相连。采用网状拓扑结构,可以在规则形状的结构中集成大量的 IP 内核[4]。因此,这种拓扑结构为路径多样性和可扩展性提供了极具吸引力的解决方案。同样,这种拓扑结构还能容忍连接一对节点的多条路径导致的链路故障 [21]。然而,这种拓扑结构面临的一个主要挑战是,其直径会随着节点数量的增加而显著增大。这是由于度数的不规则性造成的 [1]。例如,角节点、边节点和内节点的度数分别为 2、3 和 4 [21]。此外,不同节点的相关带宽也往往不同,角节点和边节点的带宽较小 [1, 21]。
4.1.6 环形拓扑
典型的环形拓扑结构如图 7(e) 所示。其架构与网状拓扑非常相似。不过,网状拓扑的直径较小。因此,环形拓扑结构解决了网状拓扑结构直径随网络规模增大而增大的难题。这是通过在同列或同行的末端节点之间增加直接连接来实现的 [21]。例如,在环形拓扑中,边缘路由器与对边路由器的连接采用了环绕信道,从而提高了分段带宽,减少了平均跳数。然而,由于采用了冗长的环绕连接,环形拓扑会产生相当大的延迟[1, 4]。
此外,折叠环形拓扑也是环形拓扑的一种替代方案。折叠环形拓扑的链路长度更短,从而减少了实施面积和数据包在互连链路之间的移动时间。与环形拓扑相比,折叠环形拓扑具有更高的路径多样性,因此容错性更高。此外,如上所述,环形拓扑结构有助于减少相关的网状延迟。不过,环形链路较长,可能会造成不必要的延迟。如图 7(f) 所示,可通过折叠环形拓扑解决这一难题。
4.1.7 蝴蝶拓扑
典型的蝴蝶拓扑如图 7(g)所示。它在任何源节点到目的节点对之间提供固定的跳数距离,路由器阶数为 2,因此路由器成本较低。由于从源节点到目的节点只有一条路径,因此该拓扑缺乏路径多样性,导致链路容错能力低和带宽低。此外,这种拓扑通常需要较长的导线,相关的复杂导线布局会导致更多的能耗[1, 21]。
4.1.8 二叉树拓扑
如图 7(h) 所示,二叉树拓扑由顶部(根)节点和底部(叶)节点组成。在这种配置中,除了根节点外,每个节点都有两个子节点。此外,除了没有父节点的根节点外,其他每个节点都有自己的父节点和子节点,分别位于自己的正上方和正下方。这种拓扑结构中的节点可以访问更广泛的网络资源,并得到多家供应商的支持。但是,它的瓶颈是根节点,根节点的故障会导致整个网络瘫痪。此外,随着树长度的增加,网络配置也变得更加复杂。
4.1.9 胖树拓扑
胖树拓扑的概念基于使用中间路由器作为转发路由器,并将离开路由器连接到客户机,如图 7(i)所示。虽然这种拓扑结构具有出色的路径多样性和更好的带宽,但路由器与客户机的比例极高,布线布局也很复杂。因此,应整合多个路由器,以连接更少的客户端[1]。
基于立方体的拓扑结构: 目前已设计出许多基于立方体的拓扑结构。超立方体拓扑就是其中一种合适的架构。然而,它的主要缺点是由于度数限制,网络规模受到限制。为了解决这一限制,人们提出了各种变体,如折叠超立方体、双立方体、交叉立方体、立方体连接循环、分层立方体和元立方体。图 8 展示了其中的一些拓扑结构,这些拓扑结构主要侧重于减少相关节点度和/或最小化网络直径,同时使直径尽可能小[10, 21, 22]。

Figure 8.Cube-based topologies: (a) cube, (b) crossed cube, (c) hypercube and (d) reduced hypercube.
在折叠超立方体中,每个节点都与最远的不同节点相连。因此,与超立方体拓扑相比,其直径大大缩小。然而,这是以增加链接为代价的。此外,还可以通过将超立方体中的一些边换位来实现交叉立方体。这有助于在不增加链路复杂度的情况下减少直径。在缩小的超立方体中,为了最小化节点度,边会从 n-维的超立方 [22]。一个(n, n)分层立方体网络由 n 个簇,每个簇有 n-个立方体。此外,分层超立方体是一种双立方体结构。这种拓扑结构包含两类(0 和 1)簇。此外,每个簇包含 2m个节点。同样,在 m-双立方体中,每个节点的二进制地址长度为 1+2m位长。同样,立方体连接的循环提供了一种带有虚拟节点的超立方体实现方式。在这种拓扑结构中,每个虚拟节点不是单个节点,而是一个有三个端口的圆。此外,元立方体拓扑也是一种两级超立方体架构。它是一种直径短、节点度小的对称网络。从结构上看,这种多级拓扑是双立方体的扩展形式[21]。
4.1.2 不规则拓扑
不规则拓扑基于各种形式(通常是规则结构)以不同方式的整合。在这方面,可以采用混合、分层或不对称的方法。此外,与传统的共享总线相比,不规则拓扑结构旨在增加可用带宽。此外,与规则拓扑相比,它有助于缩短节点之间的距离 [12]。此外,不规则拓扑结构通常与面积和功率呈非线性关系。它们通常基于聚类概念,并针对特定应用进行调整 [20]。图 9 展示了一些不规则拓扑结构,如缩小(优化)的网状结构(图 9(a)- i 和 ii)和基于集群的混合结构(网状+环状-图 9(b)
环--图 9(b))。
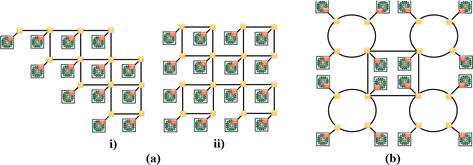
Figure 9.Irregular topologies: (a) reduced mesh structures and (b) cluster-based hybrid.
此外,除了第 4.1.2 小节讨论的分类外,NoC 拓扑还可分为直接3 和间接4 拓扑。例如,环形拓扑、总线拓扑、网状拓扑和环形拓扑都属于直接拓扑。另一方面,闭合、蝴蝶、贝尼斯和胖树是间接拓扑的良好实例 [11,12]。
4.2 片上网络路由选择
有了合适的拓扑结构,片上 IP 之间就能建立起网络,确保有效通信。通信可以通过适当的算法实现,将数据包从源节点路由到目的节点。在这种情况下,路由算法可在数据包穿越节点时对其进行高效、正确的路由控制。如前所述,无饥饿5 和无死锁路由算法在 NoC 中至关重要[10]。此外,路由算法可根据一系列相互关联的特性进行选择,从而在决定路由算法质量的功耗、数据包延迟和占用空间等相关指标之间进行权衡。例如,当路由电路保持简单时,路由所需的功率可以降到最低,从而降低功耗。此外,为提高性能,应尽量减少路由表。这将有助于确保低延迟、增强鲁棒性、低占地面积和有效利用网络 [8,12]。一般来说,NoC 路由算法可根据路由路径、距离和决策状态等因素进行分类。在这种情况下,其 NoC 路由算法主要可分为静态路由算法和动态路由算法。此外,路由决策还可以基于分布式、源、最小和非最小路由算法。本小节主要介绍静态路由算法和动态路由算法。
4.2.1 静态路由
静态路由,也称为遗忘路由或确定性路由,是 NoC 中最简单也最广泛使用的路由算法。它采用固定(预定义)路径在特定源和目的地之间传输数据。此外,静态路由不考虑网络的当前状态。因此,在做出路由决策时,它不会考虑链路和路由器的负载。静态路由只需要很少的路由器逻辑,因此很容易实现。此外,数据包可以按计划在源和目的地之间的几条路径之间分割。而且,在只使用一条路径的情况下,静态路由可以保证按顺序传送数据包。在此基础上,无需在 NI 处为数据包添加比特,即可在目的地进行正确识别和重新排序 [12]。随机漫步路由、定向泛洪、概率泛洪、维序路由(DOR)、目的地标签、转向模型、XY、周围 XY和伪适应 XY等都是静态路由算法的例子。XY路由是一种分布式确定路由算法。在这种算法中,目的地址的坐标被用于通过网络传送数据包。数据包最初沿着 X坐标(水平方向)到达列。然后,沿 Y坐标垂直传送到目的地 [5]。XY 路由是基于环形和网状拓扑的首选算法 [10,11],而且无死锁。不过,由于网络中间通常会产生负载,因此相关的流量可能会不规则[10],而 XY算法无法避开拥塞和繁忙的链路 [5]。
4.2.2 动态路由
自适应路由或动态路由的路由决策基于底层网络的现有状态。在这种路由选择方案中,路由选择决策会考虑系统可用性和链路负载状况等因素。因此,随着应用需求和流量条件的变化,源和目的地之间的路径也会发生相应的变化。与静态路由相比,动态路由能更有效地在不同路由器之间分配流量。此外,在某些 NoC 链路出现网络拥塞的情况下,它还可以利用替代路径。因此,其拓扑结构可以支持更多流量,并最大限度地提高网络带宽利用率。自适应路由的这些显著特点是由于它能够利用当前流量状态的全局知识来进行最优路径选择[23]。不过,这种方案的自适应能力是以需要额外资源为代价的,这些资源用于持续监控网络状态,以确保路由路径发生相应的动态变化。这通常会增加路由器设计的复杂性。此外,由于可转发给每个路由器的全局知识量受到限制,再加上干扰,自适应路由的有效性也受到了限制[23]。如前所述,静态路由方案通常用于具有稳定和已知流量需求的场景,而动态路由主要适用于不可预测和不规则的流量条件[8, 12]。拥塞前瞻(congestion look-ahead)、松弛时间感知(slack time aware)、完全自适应(fully adaptive)、最小自适应(minimal adaptive)、可能时回转(turnback when possible)、回转-回转(turnaround-turnback)、奇偶校验(odd-even)、偏转(hot potato)等方案都是自适应路由算法的例子。
在 NoC 中,为了在源端和目的端之间进行通信,可以采用自适应路由算法和确定性路由算法。奇偶路由算法是一种自适应路由,它是一种无死锁转向模型。因此,在网格网络中,偶数列禁止从东到南和从东到北转弯。同时,在奇数列中禁止由北向西和由南向西转弯。因此,奇偶路由算法有助于消除系统中潜在的死锁6 [5,10]。
偏转路由技术无需缓冲区,因此成本效益高。因此,路由器接收到的数据包不会被缓冲,而是根据路由表同时向目的地移动。然而,当繁忙的路由器收到另一个数据包时,可能会发生错误路由。在严重的情况下,网络中的错误路由数据包会导致更多的错误路由,使得每个数据包都像烫手山芋一样在网络中跳来跳去 [12]。如果数据包之间有足够的间隔,就能大大缓解误路由问题 [10]。
4.3 片上网络交换
NoC 交换方案表示路由器中用于数据控制的交换技术,并规定了数据传输的粒度。包交换和电路交换是 NoC 中的关键交换技术。切换方案如图 10 所示,本小节将对其进行讨论。
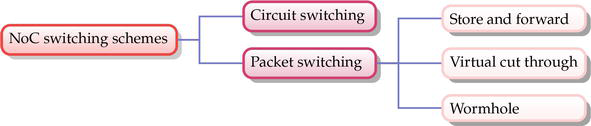
Figure 10.NoC switching schemes.
4.3.1 电路交换
电路交换的基础是在数据传输前在源和目的地之间建立由路由器和链路组成的预留物理路径(链路预留)。电路交换虽然能充分利用链路带宽,提供低延迟传输,但在没有数据传输时会浪费已建立的链路,从而导致可扩展性问题。此外,为了提高网络的可扩展性,还可以采用虚拟电路交换。它有助于在单个物理链路上复用多个虚拟链路。同时,分配的缓冲区决定了物理链路可支持的虚拟链路总数[12]。
4.3.2 分组交换
数据包交换是另一种流行的交换模式。与电路交换在数据传输前建立路径不同,在分组交换中,数据包传输前无需创建路径(无链路预留)。在这种情况下,传输的数据包会沿着独立的路径(不同的路由)从源到目的地。因此,数据包将经历不同的延迟。此外,电路交换通常会产生启动等待时间和固定的最小延迟,而分组交换则不同,通常会产生零启动时间和因争用而产生的可变延迟。此外,由于存在竞争,与电路交换相比,分组交换的服务质量7 (QoS)难以保证。虫洞、虚拟穿通以及存储和转发是广泛采用的分组交换方案[12]。
4.4 片上网络应用映射
在超级计算和并行计算中,应用映射通常用于映射共享资源的应用,使其靠近以尽量减少网络延迟。这也适用于基于共享总线的芯片多处理器架构,其中应用映射应考虑基本的片上互连设计。根据所采用的拓扑结构,映射算法的实施有助于将 IP 内核定位到 NoC 板块。此外,其性能在很大程度上取决于所采用的路由接口和共享内存架构[8]。
在 MPSoC 中,应用映射可以采用很多技术。此外,多种不同的 MPSoC 架构也使问题更加复杂。因此,在实际应用中,最好根据应用体系结构类别重建映射方法[8]。此外,如图 11 所示,NoC 应用映射算法根据分配任务的时间大致分为静态和动态两类。在这种情况下,任务分配给 IP 核进行处理的时间被考虑在内。例如,在动态映射中,应用任务的聚类、排序和向内核的分配都是在应用执行过程中实施的(实时)。此外,动态映射还能根据内核的运行时负载进行映射,因此是一种高效的解决方案。此外,通过对流量负载的分析,可以在内核之间分配工作负载,以解决网络拥塞问题。在此基础上,可以确定任何核心的性能瓶颈。然而,由于相关的计算复杂度(开销),实时映射算法的实施不仅会产生执行延迟,还会消耗更多能源[24, 25]。
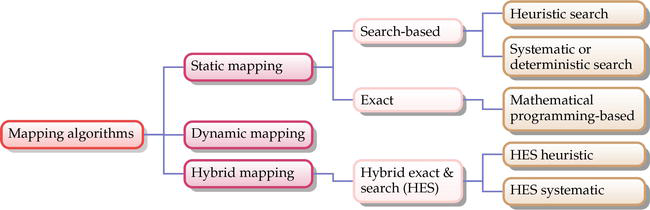
Figure 11.NoC mapping algorithms classification.
在静态映射中,应用任务映射是在设计期间离线执行的。在这种情况下,映射通常在应用执行前完成。由于相关的应用场景在设计期间就已知晓,因此可以制定出最优或至少接近最优的解决方案。这使得静态映射算法成为解决动态映射相关额外通信开销的好办法。因此,相关的延迟和能耗可以降到最低。然而,静态映射无法处理自然界中通常遇到的动态场景。此外,静态映射主要分为精确算法(基于数学)和搜索算法。基于搜索的映射算法又可分为启发式和确定式(系统式)[24, 25]。
此外,人们还提出了混合应用映射算法,以利用上述映射算法的优势应对挑战。在这方面,混合算法提供了高效的应用映射解决方案。关于 NoC 映射算法分类的更多信息,请参见 [24, 25]。此外,另一个前景广阔的领域是将多层处理内核集成到 3D 设计中。这将大大有助于降低功耗、面积和信号传输延迟。在此基础上,三维多核架构被认为是未来高性能系统的潜在解决方案。然而,三维架构的相关高集成度带来了温度升高的额外问题。这种效应会带来高温梯度和热热点,使系统变得不可靠,进而降低性能。因此,三维热管理需要进一步的研究关注[24]。
5. 拓扑性能评估
一些特性决定了基于 NoC 的系统的性能,并影响相关拓扑实施的有效性。本节介绍各种拓扑性能评估和指标。
5.1 拓扑参数
分段宽度、直径、度数和链路复杂度等各种因素是区分拓扑和其他拓扑的一些参数。下面各小节将讨论其中一些参数。
5.1.1 节点度
如前所述,如果整个节点的阶数相同或不相同,则网络可以是规则的,也可以是不规则的。节点度是与节点相连的边的数量。此外,节点度定义了节点的 I/O 复杂性,根据拓扑结构的不同,节点度会随网络规模的变化而变化或不变。而且,节点度恒定和节点度较小等拓扑特征通常是可扩展网络的理想特征。例如,前者减轻了在现有网络中添加新节点所需的工作量,而后者则有利于降低链路的硬件成本。此外,在节点的直接邻居数量方面,节点度总是存在限制。此外,值得注意的是,由于通信协议和硬件的限制,节点限制也会增加。这与节点度和节点可支持的端口数有关。网络可扩展性和空间复杂性等其他因素也是限制有效节点通信的性能考虑因素。
5.1.2 直径
在网络拓扑中,直径是节点对之间的最大最短距离(路径)。此外,在两个节点之间不存在直接连接的情况下,从源节点发出的信息必须经过多个中间节点才能到达目的地。在这种情况下,就会产生多跳延迟。此外,这种延迟与到达目的地的总跳数相对应。因此,在网络拓扑中,最大最短路径长度是一个重要指标。一般来说,除了能够提供可预测的流量和路由路径外,小直径还有助于提供低延迟,并方便网络故障排除。
5.1.3 链路复杂度
在拓扑结构中,链路复杂度定义了链路或互连的总数量。需要注意的是,链路复杂度与网络规模成正比,全连接网络的复杂度最高。此外,在某些网络中添加额外链路时,其直径会减小。这有助于提供更好的通信,降低节点之间的延迟。然而,除了带来的复杂性外,额外链路的成本也很高。此外,高链路复杂度还可能导致高开销(即成本、面积等)和硬件复杂度。
5.1.4 分段宽度
分段宽度是将网络拓扑结构分成大小基本相等的两半(子网络)所需删除的最小边数。需要注意的是,为了提高网络的稳定性,通常需要较大的分割宽度。这是因为两个子网络实体之间提供了更多的路径,从而有助于提高整体性能。此外,大的分段宽度还能获得大的分段带宽。分段带宽 Bb可表示为:
...............................................................................................................................
5.2.4 平均队列占用率
按数据包测量的平均队列长度即为平均队列长度。此外,它还可用于表示缓冲区利用率。因此,队列越短,表示缓冲区利用率越低,队列延迟越短。此外,为了获得利用率,每个时隙都要对队列长度进行采样[21]。此外,不同的主动队列管理技术,如随机早期检测、赤字轮循、公平队列、掉尾、随机公平队列和随机指数标记,可用于不同源节点和目的节点之间的数据包流量控制。这可以通过管理中间路由器的缓冲区来实现 [28]。
6. NoC 面临的挑战
如前所述,NoC 提供了一个可扩展的模块化平台,可提供高效的片上通信,以应对 SoC 集成化的趋势,但仍需要关注某些相关挑战,以进一步提高系统性能。本节将讨论一些片上挑战。
6.1 链路
由于并行或串行链路的相关特性,选择并行或串行链路进行数据传输一直是 NoC 的首要问题之一。例如,串行链路可以大大节省面积、减少噪声和干扰。但是,数据传输需要串行器和解串行器电路。另一方面,并行链路有助于降低功耗,但由于其基于缓冲区的架构,会消耗更多面积[10, 29]。
6.2 路由器架构
嵌入式系统的主要因素之一是产品成本。此外,底层架构必须体积小,因此功耗低。因此,路由协议设计需要在成本和性能之间做出权衡。例如,复杂的路由协议会使路由器设计变得复杂。在这种情况下,将消耗更多的面积和功率,从而不经济。另一方面,更简单的路由协议将是一种具有成本效益的解决方案,但其在流量路由方面的性能却不尽如人意[10, 29]。
6.3 NoC 面积/空间优化
在 NoC 体系结构中,通信是通过路由器网络中的长链路通过连接的模块进行的。此外,针对不同拓扑结构的链路大小、数据包大小、缓冲区大小、流量/拥塞控制和交换协议等各种方案,不仅为 NoC 设计提供了巨大的空间,也使开放基准测试面临挑战。因此,要提高系统性能,链路优化势在必行。虽然这一问题可以通过中继器实现来解决,但会占用更多芯片面积 [10,29]。同样,为促进 NoC 技术的广泛应用,需要可与当前标准工具无缝集成的高效空间评估和实施设计工具。此外,由于 NoC 系统的复杂性,网络仿真时间将非常紧迫。因此,为了优化仿真速度,需要采用创新技术。此外,为确保为应用选择合适的架构,还需要开放的基准来比较不同的性能特征[12]。
6.4 延迟
在 NoC 中,延迟的增加是由于 NI 上数据打包/解包的额外延迟造成的。这也可归因于容错协议开销和流量/拥塞控制延迟。此外,由于争用和缓冲,路由延迟也会影响网络性能。因此,为了提高网络性能(即满足严格的延迟约束),需要本机 NoC 支持、低直径拓扑和先进的流量控制方法 [12]。
6.5 功耗泄漏
根据不同的应用,NoC 中的链路利用率可能会有所不同,在某些情况下,利用率会非常低。为了满足最坏情况下的要求,NoC 被设计为保留冗余链路,并以较低的链路利用率运行。尽管如此,即使有理想的链路,由于相关的复杂路由逻辑块和 NI,NoC 的功耗也相对较高。因此,要进一步提高其降低泄漏功耗的性能,需要创新的架构和电路技术[10, 29]。
7. 仿真分析和结果
在本节中,我们在仿真分析中考虑了 4×4 2D 网格、环形和基于胖树的 NoC 进行仿真分析,并给出有关其性能的结果。仿真基于 OPNET 网络仿真器。我们假设各功能内核在遵循负指数分布的时间间隔内独立生成数据包。此外,我们还假设了一种统一的流量模式,即每个处理器以相等的概率将数据包转发给其他处理器。同样,我们使用了 256 至 1024 字节的有效载荷数据包大小,以实现多样化的提供负载。端到端(ETE)延迟(时延)和吞吐量是我们考虑的性能指标。
所考虑的 NoC 普遍存在漂移模式,从而导致类似的性能展示。图 12(a) 描述了平均延迟,表明它随着提供负载的增加而增加,并且在饱和后上升得更快。例如,采用网状拓扑结构时,平均延迟小于 2 μ秒,随后又急剧增加。这种饱和负载后的快速增长可归因于网络拥塞。此外,在 70 μs 时,网状、环状和胖树的提供负载分别约为 0.45、0.48 和 0.56。此外,图 12(a) 显示了不同提供负载下的吞吐量,并显示在饱和之前,吞吐量随着提供负载的增加而增加。例如,当提供的负载为 0.6 时,网格、环和胖树的吞吐量分别约为 150、160 和 180 Gbit/s。
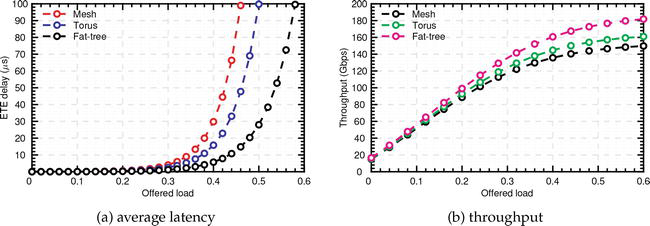
Figure 12.Performance analysis of the considered topologies under different offered loads and at 256 bytes packet.
此外,图 13(a) 显示了考虑到不同提供负载和数据包长度的平均延迟。值得注意的是,根据数据包的大小,网络在不同的负载下会达到饱和。例如,在饱和负载之前,平均延迟相对较低,而在饱和负载之后,平均延迟会大幅上升。因此,与较大的数据包相比,256 字节数据包的饱和负载较低。此外,随着数据包大小的增加,相邻数据包大小的平均延迟曲线之间的变化也会变小。同样,图 13(b) 展示了基于不同提供负载和数据包大小的网络吞吐量。
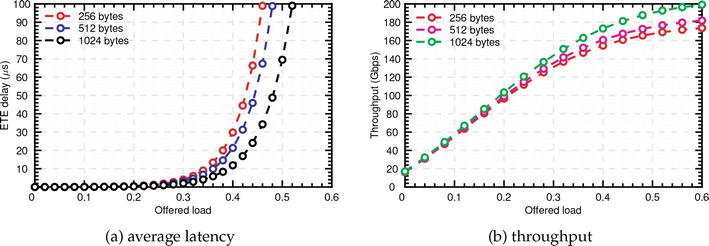
Figure 13.Performance analysis of 4××4 mesh network under different offered loads and packet lengths.
致谢
这项工作得到了欧洲区域发展基金 (FEDER) 和葡萄牙 2020 (P2020) 框架下的国际化运营计划 (COMPETE 2020) 的支持,项目包括 DSPMetroNet (POCI-01-0145-FEDER-029405) 和 UIDB/50008/2020-UIDP/50008/2020 (DigCORE),以及 FCT/MCTES 通过国家基金提供的支持,并在适用情况下,通过 UIDB/50008/2020-UIDP/50008/2020 项目(QuRUNNER 行动)共同获得欧盟基金的资助。
References
- 1.A. Kalita, K. Ray, A. Biswas, and M. A. Hussain. A topology for network-on-chip. In 2016 International Conference on Information Communication and Embedded Systems (ICICES), pages 1–7, 2016.
- 2.Haytham Elmiligi, Ahmed A. Morgan, M. Watheq El-Kharashi, and Fayez Gebali. Power optimization for application-specific networks-on-chips: A topology-based approach. Microprocessors and Microsystems, 33(5):343–355, 2009.
- 3.D. Bertozzi and L. Benini. Xpipes: a network-on-chip architecture for gigascale systems-on-chip. IEEE Circuits and Systems Magazine, 4(2):18–31, 2004.
- 4.T. N. Kamal Reddy, A. K. Swain, J. K. Singh, and K. K. Mahapatra. Performance assessment of different Network-on-Chip topologies. In 2014 2nd International Conference on Devices, Circuits and Systems (ICDCS), pages 1–5, 2014.
- 5.Zulqar Nain, Rashid Ali, Sheraz Anjum, M. Afzal, and S. Kim. A Network Adaptive Fault-Tolerant Routing Algorithm for Demanding Latency and Throughput Applications of Network-on-a-Chip Designs. Electronics, 9(1076):1–18, 2020.
- 6.Isiaka A. Alimi, Ana Tavares, Cátia Pinho, Abdelgader M. Abdalla, Paulo P. Monteiro, and António L. Teixeira. Enabling Optical Wired and Wireless Technologies for 5G and Beyond Networks, chapter 8, pages 1–31. IntechOpen, London, 2019.
- 7.Cátia Pinho, Isiaka Alimi, Mário Lima, Paulo Monteiro, and António Teixeira. Spatial Light Modulation as a Flexible Platform for Optical Systems, chapter 7, pages 1–21. IntechOpen, London, 2019.
- 8.Haseeb Bokhari and Sri Parameswaran. Network-on-Chip Design, chapter 5, pages 461–489. Springer Netherlands, Dordrecht, 2017.
- 9.G. Passas, M. Katevenis, and D. Pnevmatikatos. Crossbar NoCs Are Scalable Beyond 100 Nodes. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 31(4):573–585, 2012.
- 10.H. J. Mahanta, A. Biswas, and M. A. Hussain. Networks on Chip: The New Trend of On-Chip Interconnection. In 2014 Fourth International Conference on Communication Systems and Network Technologies, pages 1050–1053, 2014.
- 11.S. Johari and V. Sehgal. Master-based routing algorithm and communication-based cluster topology for 2D NoC. The Journal of Supercomputing, 71:4260–4286, 2015.
- 12.Sudeep Pasricha and Nikil Dutt. Networks-On-Chip, chapter 12, pages 439–471. Systems on Silicon. Morgan Kaufmann, Burlington, 2008.
- 13.B. N. K. Reddy, D. Kishan, and B. V. Vani. Performance constrained multi-application network on chip core mapping. International Journal of Speech Technology, 22:927–936, 2019.
- 14.Evgeny Bolotin and Israel Cidon and Ran Ginosar and Avinoam Kolodny. Cost considerations in network on chip. Integration, 38(1):19–42, 2004.
- 15.D. Flynn. AMBA: enabling reusable on-chip designs. IEEE Micro, 17(4):20–27, 1997.
- 16.Rohita P. Patil and Pratima V. Sangamkar. Review of System-On-Chip Bus Protocols. International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering, 4(1):271–281, 2015.
- 17.María Dolores Valdés Peña Juan José Rodríguez Andina, Eduardo de la Torre Arnanz. Embedded Processors in FPGA Architectures.
- 18.Mohandeep Sharma and D. Kumar. Wishbone bus architecture - a survey and comparison. International Journal of VLSI design & Communication Systems (VLSICS), 3(2):107–124, 2012.
- 19.Altera. Avalon Bus Specification. Reference manual: 2.3, July 2003.
- 20.Tobias Bjerregaard and Shankar Mahadevan. A Survey of Research and Practices of Network-on-Chip. ACM Comput. Surv., 38(1):1–es, June 2006.
- 21.J. Chen, P. Gillard, and Cheng Li. Network-on-Chip (NoC) Topologies and Performance: A Review. In Proceedings of the 2011 Newfoundland Electrical and Computer Engineering Conference (NECEC), pages 1–6, 2011.
- 22.Y. Li and S. Peng. Dual-cubes: A new interconnection network for high-performance computer clusters. In International Computer Symposium, Workshop on Computer Architecture, pages 1–7, 2000.
- 23.S. Ma, N. E. Jerger, and Z. Wang. DBAR: An efficient routing algorithm to support multiple concurrent applications in networks-on-chip. In 2011 38th Annual International Symposium on Computer Architecture (ISCA), pages 413–424, 2011.
- 24.W. Amin, F. Hussain, S. Anjum, S. Khan, N. K. Baloch, Z. Nain, and S. W. Kim. Performance Evaluation of Application Mapping Approaches for Network-on-Chip Designs. IEEE Access, 8:63607–63631, 2020.
- 25.Pradip Kumar Sahu and Santanu Chattopadhyay. A survey on application mapping strategies for Network-on-Chip design. Journal of Systems Architecture, 59(1):60–76, 2013.
- 26.V. F. Pavlidis and E. G. Friedman. 3-D Topologies for Networks-on-Chip. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 15(10):1081–1090, 2007.
- 27.Xingang Ju and Liang Yang. Performance analysis and comparison of 2××4 network on chip topology. Microprocessors and Microsystems, 36(6):505–509, 2012.
- 28.S. Patel and A. Sharma. The low-rate denial of service attack based comparative study of active queue management scheme. In 2017 Tenth International Conference on Contemporary Computing (IC3), pages 1–3, 2017.
- 29.A. Agarwal and R. Shankar. Survey of Network on Chip (NoC) Architectures & Contributions. volume 3, pages 21–27, 2009.
Notes
- A deadlock happens in the NoCs when one or more packets remain blocked for an indefinite time. It can be addressed either by imposing routing restrictions or by employing additional hardware resources.
- Router degree is a parameter that specifies the number of on-chip components and neighboring routers that it is connected to. It is noteworthy that the router microarchitecture complexity increases with an increase in its degree.
- In this topology, there is a direct connection of each router to at least a core.
- In this topology, some of the employed routers are not directly connected to any of the cores.
- Starvation usually occurs in NoCs when specified priority rules are employed for routing, mainly in favor of the high priority packets, making low priority packets wandering in the network. It can be attended to by reserving some resources for the low priority packets and adopting fair routing algorithms.
- A livelock arises in NoCs when a packet bounces around indefinitely between routers without reaching its destination. It is typically associated with adaptive routing and can be addressed by employing uncomplicated priority rules.
- Quality of Service implies performance bounds regarding the delay, bandwidth, and jitter; and can be categorized into differentiated service, guaranteed service, and best effort.
- The flits are fundamental packets for the execution of link flow control operations and synchronization between routers.

















 3645
3645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









