






DeepSeek-R1蒸馏模型概述与应用指南
引言
DeepSeek-R1作为一款先进的AI推理模型,在性能上已超越GPT-4o和Claude-3.5等主流开源模型。为满足更广泛应用需求,推出了基于不同架构的精简版模型,旨在提供高性能同时兼顾计算效率。模型架构与变体
本系列提供以下六种精简版模型:Qwen架构系列
+ DeepSeek-R1-Distill-Qwen-1.5B + DeepSeek-R1-Distill-Qwen-7B + DeepSeek-R1-Distill-Qwen-14B + DeepSeek-R1-Distill-Qwen-32BLlama架构系列
+ DeepSeek-R1-Distill-Llama-8B + DeepSeek-R1-Distill-Llama-70B性能概览
各精简模型在关键基准测试中表现优异:
模型优势
1. ** 高效性** :精简设计,计算效率显著提升。 2. ** 强推理能力** :继承自DeepSeek-R1的核心算法。 3. ** 开源开放** :方便开发者自由使用和扩展。与其他模型对比
与同类强化学习训练模型相比,我们的蒸馏方法:- 计算成本更低
- 性能表现更优
例如,DeepSeek-R1-Distill-Qwen-32B精简版在AIME测试中优于同规模的强化学习版本。
使用指南
方法一:Ollama平台部署
```plain ollama run deepseek-r1:32b ```方法二:vLLM框架运行
```css vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \–tensor-parallel-size 2 \
–max-model-len 32768 \
–enforce-eager
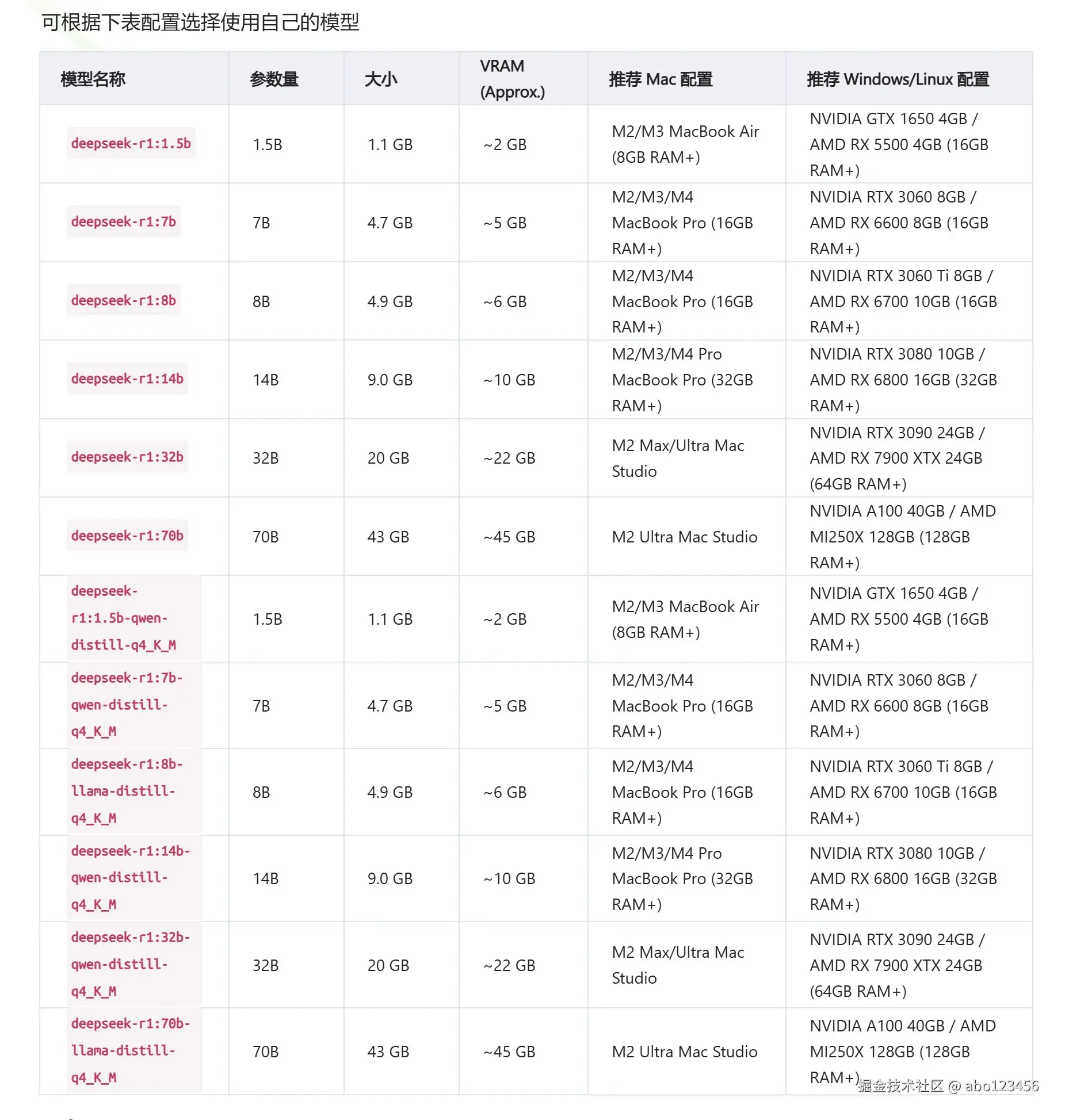
<h3 id="4c7c805c"><font style="color:rgb(51, 51, 51);">模型显卡配置表</font></h3>

















 2496
2496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









