




手部关键点检测2:YOLOv5实现手部检测(含训练代码和数据集)
目录
手部关键点检测2:YOLOv5实现手部检测(含训练代码和数据集)
5. 手部检测和手部关键点检测(Python/C++/Android)
1. 前言
手部关键点检测(手部姿势估计)的方法与人体关键点检测的方法类似,目前主流的方法主要两种:一种是Top-Down(自上而下)方法,另外一种是Bottom-Up(自下而上)方法;项目采用Top-Down(自上而下)方法,即分为两阶段,先进行手部检测,找到所有的手部框,然后再估计每只手的手部关键点;本篇文章是手部关键点检测的第一阶段,即手部检测模型算法开发,项目基于开源YOLOv5项目,实现一个高精度的手部检测算法( Hand Detection)

目前,基于YOLOv5s的手部检测精度平均值mAP_0.5=0.99919,mAP_0.5:0.95=0.79306。为了能部署在手机Android平台上,本人对YOLOv5s进行了简单的模型轻量化,并开发了一个轻量级的版本yolov5s05_416和yolov5s05_320模型;轻量化模型在普通Android手机上可以达到实时的检测效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。下表格给出轻量化模型的计算量和参数量以及其检测精度
| 模型 | input-size | params(M) | GFLOPs | mAP_0.5 | mAP_0.5:0.95 |
| yolov5s | 640×640 | 7.2 | 16.5 | 0.99919 | 0.79306 |
| yolov5s05 | 416×416 | 1.7 | 1.8 | 0.99885 | 0.78112 |
| yolov5s05 | 320×320 | 1.7 | 1.1 | 0.99826 | 0.77658 |
先展示一下手部检测以及手部关键点检测(手部姿势估计)效果:

Android手部关键点检测(手部姿势估计)APP Demo体验:https://download.csdn.net/download/guyuealian/88418582

【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/133279222
更多项目《手部关键点检测(手部姿势估计)》系列文章请参考:
- 手部关键点检测1:手部关键点(手部姿势估计)数据集(含下载链接)https://blog.csdn.net/guyuealian/article/details/133277630
- 手部关键点检测2:YOLOv5实现手部检测(含训练代码和数据集)https://blog.csdn.net/guyuealian/article/details/133279222
- 手部关键点检测3:Pytorch实现手部关键点检测(手部姿势估计)含训练代码和数据集https://blog.csdn.net/guyuealian/article/details/133277726
- 手部关键点检测4:Android实现手部关键点检测(手部姿势估计)含源码 可实时检测https://blog.csdn.net/guyuealian/article/details/133931698
- 手部关键点检测5:C++实现手部关键点检测(手部姿势估计)含源码 可实时检测https://blog.csdn.net/guyuealian/article/details/133277748

2. 手部检测数据集说明
(1)手部检测数据集
目前收集了三个手部检测数据集:Hand-voc1,Hand-voc2和Hand-voc3,总共60000+张图片;标注格式统一转换为VOC数据格式,标注名称为hand,可用于深度学习手部目标检测模型算法开发,关于手部数据集说明,请参考: 手部关键点(手部姿势估计)数据集(含下载链接) https://blog.csdn.net/guyuealian/article/details/133277630
(2)自定义数据集
如果需要增/删类别数据进行训练,或者需要自定数据集进行训练,可参考如下步骤:
- 采集图片,建议不少于200张图片
- 使用Labelme等标注工具,对目标进行拉框标注:labelme工具:GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
- 将标注格式转换为VOC数据格式,参考工具:labelme/labelme2voc.py at main · wkentaro/labelme · GitHub
- 生成训练集train.txt和验证集val.txt文件列表
- 修改engine/configs/voc_local.yaml的train和val的数据路径
- 重新开始训练

3. 基于YOLOv5的手部检测模型训练
(1)YOLOv5安装
训练Pipeline采用YOLOv5: GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite , 原始官方代码训练需要转换为YOLO的格式,不支持VOC的数据格式。为了适配VOC数据,本人新增了LoadVOCImagesAndLabels用于解析VOC数据集,以便正常训练。另外,为了方便测试,还增加demo.py文件,可支持对图片,视频和摄像头的测试。
Python依赖环境,使用pip安装即可,项目代码都在Ubuntu系统和Windows系统验证正常运行,请放心使用;若出现异常,大概率是相关依赖包版本没有完全对应
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
thop # FLOPs computation
pybaseutils==0.7.0项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境):
(2)准备Train和Test数据
下载手部检测数据集,关于手部数据集说明,请参考手部关键点(手部姿势估计)数据集(含下载链接) https://blog.csdn.net/guyuealian/article/details/133277630
(3)配置数据文件
- 修改训练和测试数据的路径:engine/configs/voc_local.yaml
- 注意数据路径分隔符使用【/】,不是【\】
- 项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
# 数据路径
path: "" # dataset root dir
# 注意数据路径分隔符使用【/】,不是【\】
# 项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!
train:
- 'D:/dataset/Hand-voc1/train/train.txt'
- 'D:/dataset/Hand-voc2/train.txt'
- 'D:/dataset/Hand-voc3/train.txt'
val:
- 'D:/dataset/Hand-voc1/test/test.txt'
test: # test images (optional)
data_type: voc
# 1.设置类别个数,和要训练的类别名称,ID号从0开始递增
nc: 1 # number of classes
names: { 'hand': 0}(4)配置模型文件
官方YOLOv5给出了YOLOv5l,YOLOv5m,YOLOv5s等模型。考虑到手机端CPU/GPU性能比较弱鸡,直接部署yolov5s运行速度十分慢。所以本人在yolov5s基础上进行模型轻量化处理,即将yolov5s的模型的channels通道数全部都减少一半,并且模型输入由原来的640×640降低到416×416或者320×320,该轻量化的模型我称之为yolov5s05。轻量化后的模型yolov5s05比yolov5s计算量减少了16倍,参数量减少了7倍。下面是yolov5s05和yolov5s的参数量和计算量对比:
| 模型 | input-size | params(M) | GFLOPs |
| yolov5s | 640×640 | 7.2 | 16.5 |
| yolov5s05 | 416×416 | 1.7 | 1.8 |
| yolov5s05 | 320×320 | 1.7 | 1.1 |
(5)重新聚类Anchor(可选)
官方yolov5s的Anchor是基于COCO数据集进行聚类获得(详见models/yolov5s.yaml文件)

考虑到手部检测数据集,目标框几乎都是正方形的矩形框;原始Anchor是在输入640×640聚类获得的,直接复用原始COCO的Anchor效果可能不太好;因此,这需要我们根据已有的数据集的标注框进行重新聚类获得新的Anchor;这里为了简单,yolov5s直接复用原始Anchor,而yolov5s05_416和yolov5s05_320由于输入分辨率变小,其Anchor也进行等比例缩小,下表给出yolov5s,yolov5s05_416和yolov5s05_320重新调整后Anchor结果:
| yolov5s.yaml | yolov5s05_416.yaml | yolov5s05_320.yaml |
 |  |  |
一点建议:
- 官方yolov5s的Anchor是基于COCO数据集进行聚类获得,不同数据集需要做适当的调整,其最优Anchor建议重新进行聚类 。
- 当然你要是觉得麻烦就跳过,不需要重新聚类Anchor,这个影响不是特别大。如果你需要重新聚类,请参考engine/kmeans_anchor/demo.py文件
(6)开始训练
整套训练代码非常简单操作,用户只需要填写好对应的数据路径,即可开始训练了。
- 修改训练超参文件data/hyps/hyp.scratch-v1.yaml (可以修改训练学习率,数据增强等方式,使用默认即可,可不修改)
- Linux系统终端运行,训练yolov5s或轻量化版本yolov5s05_416或者yolov5s05_320 (选择其中一个训练即可)
#!/usr/bin/env bash
#--------------训练yolov5s--------------
# 输出项目名称路径
project="runs/yolov5s_640"
# 训练和测试数据的路径
data="engine/configs/voc_local.yaml"
# YOLOv5模型配置文件
cfg="models/yolov5s.yaml"
# 训练超参数文件
hyp="data/hyps/hyp.scratch-v1.yaml"
# 预训练文件
weights="engine/pretrained/yolov5s.pt"
python train.py --data $data --cfg $cfg --hyp $hyp --weights $weights --batch-size 16 --imgsz 640 --workers 4 --project $project
#--------------训练轻量化版本yolov5s05_416--------------
# 输出项目名称路径
project="runs/yolov5s05_416"
# 训练和测试数据的路径
data="engine/configs/voc_local.yaml"
# YOLOv5模型配置文件
cfg="models/yolov5s05_416.yaml"
# 训练超参数文件
hyp="data/hyps/hyp.scratch-v1.yaml"
# 预训练文件
weights="engine/pretrained/yolov5s.pt"
python train.py --data $data --cfg $cfg --hyp $hyp --weights $weights --batch-size 16 --imgsz 416 --workers 4 --project $project
#--------------训练轻量化版本yolov5s05_320--------------
# 输出项目名称路径
project="runs/yolov5s05_320"
# 训练和测试数据的路径
data="engine/configs/voc_local.yaml"
# YOLOv5模型配置文件
cfg="models/yolov5s05_320.yaml"
# 训练超参数文件
hyp="data/hyps/hyp.scratch-v1.yaml"
# 预训练文件
weights="engine/pretrained/yolov5s.pt"
python train.py --data $data --cfg $cfg --hyp $hyp --weights $weights --batch-size 16 --imgsz 320 --workers 4 --project $project
- Windows系统终端运行,训练yolov5s或轻量化版本yolov5s05_416或者yolov5s05_320 (选择其中一个训练即可)
#!/usr/bin/env bash
#--------------训练yolov5s--------------
python train.py --data engine/configs/voc_local.yaml --cfg models/yolov5s.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 16 --imgsz 640 --workers 4 --project runs/yolov5s_640
#--------------训练轻量化版本yolov5s05_416--------------
python train.py --data engine/configs/voc_local.yaml --cfg models/yolov5s05_416.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 16 --imgsz 416 --workers 4 --project runs/yolov5s05_416
#--------------训练轻量化版本yolov5s05_320--------------
python train.py --data engine/configs/voc_local.yaml --cfg models/yolov5s05_320.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 16 --imgsz 320 --workers 4 --project runs/yolov5s05_320
- 开始训练:
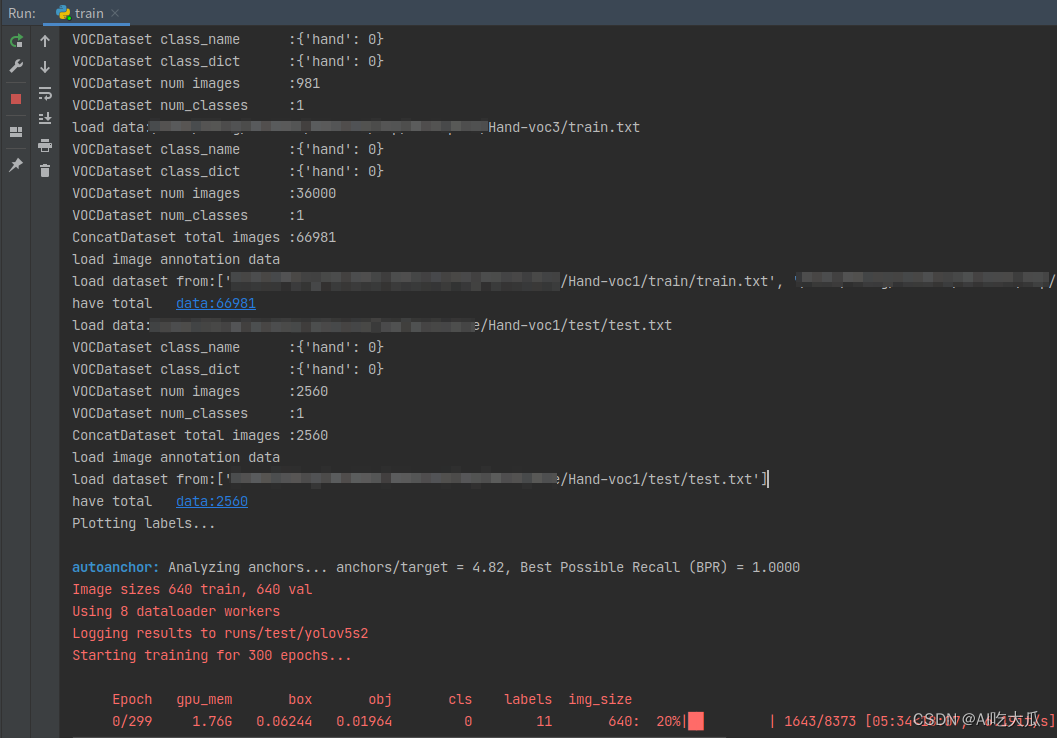
- 训练数据量比较大,训练时间比较长,请耐心等待哈
- 训练完成后,在模型输出目录中有个results.csv文件,记录每个epoch测试的结果,如loss,mAP等信息
训练模型收敛后,yolov5s手部检测的mAP指标大约mAP_0.5:0.95=0.79306;而,yolov5s05_416 mAP_0.5:0.95=0.78112左右;yolov5s05_320 mAP_0.5:0.95=0.77658左右;轻量化后的模型yolov5s05比yolov5s计算量减少了16倍,参数量减少了7倍;相比而言,yolov5s05比yolov5s mAP减小了2%左右,对于性能比较弱鸡的手机而言,这个精度是还是可以接受的。
| 模型 | input-size | params(M) | GFLOPs | mAP_0.5 | mAP_0.5:0.95 |
| yolov5s | 640×640 | 7.2 | 16.5 | 0.99919 | 0.79306 |
| yolov5s05 | 416×416 | 1.7 | 1.8 | 0.99885 | 0.78112 |
| yolov5s05 | 320×320 | 1.7 | 1.1 | 0.99826 | 0.77658 |
(7)可视化训练过程
训练过程可视化工具是使用Tensorboard,使用方法,在终端输入:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir=./data/model/yolov5s_640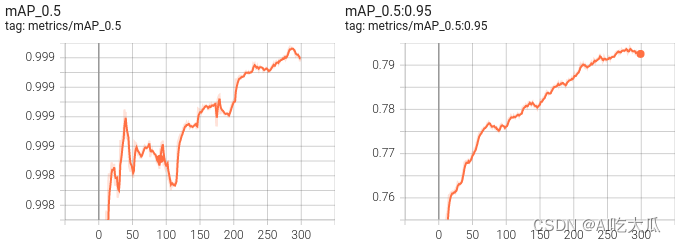
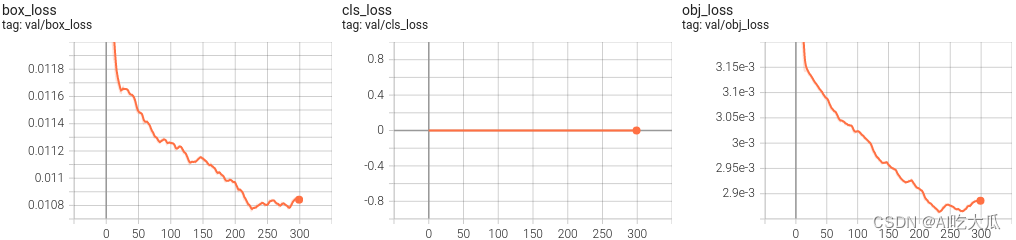
当然,在输出目录,也保存很多性能指标的图片
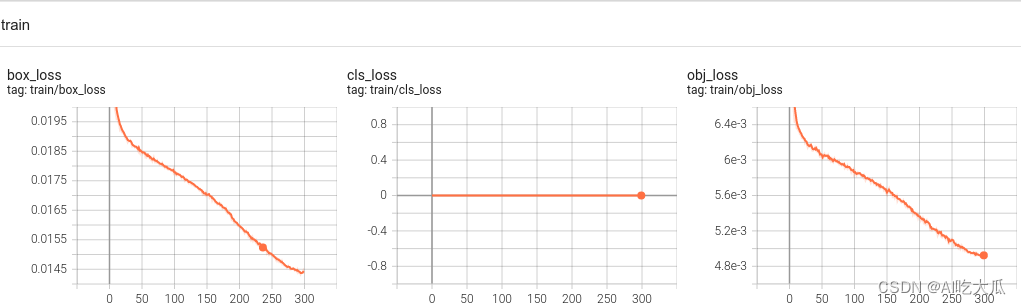
- 这是训练epoch的可视化图,可以看到mAP随着Epoch训练,逐渐提高(见result.png)

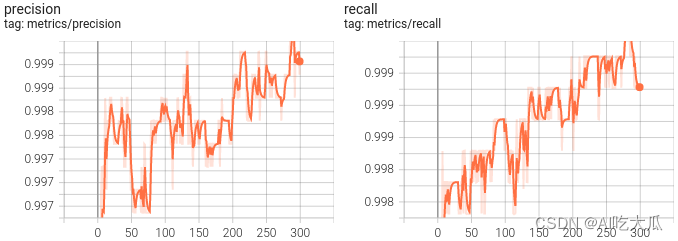
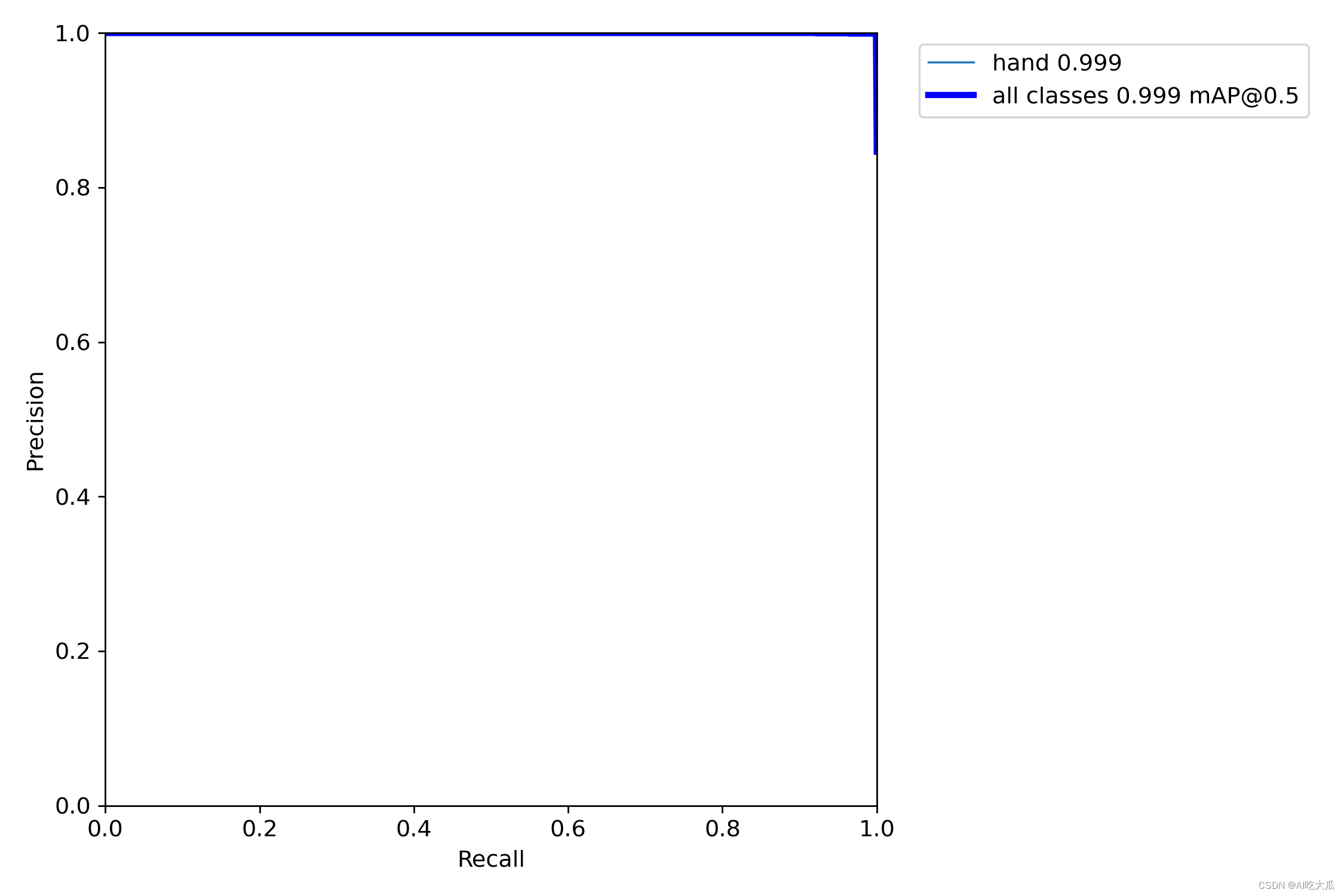
- 这是每个类别的F1-Score分数(见F1_curve.png)
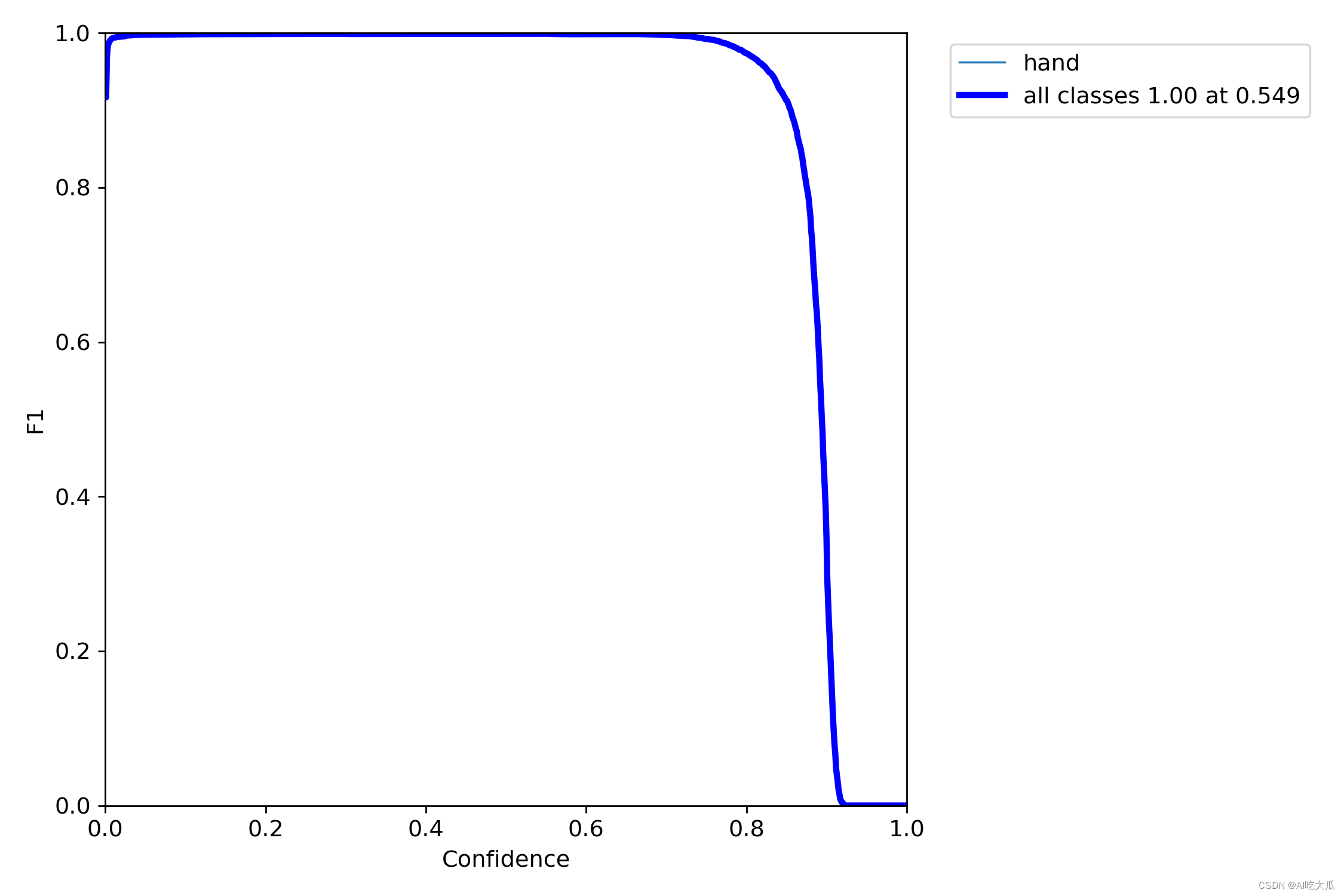
- 这是模型的PR曲线(见PR_curve.png)
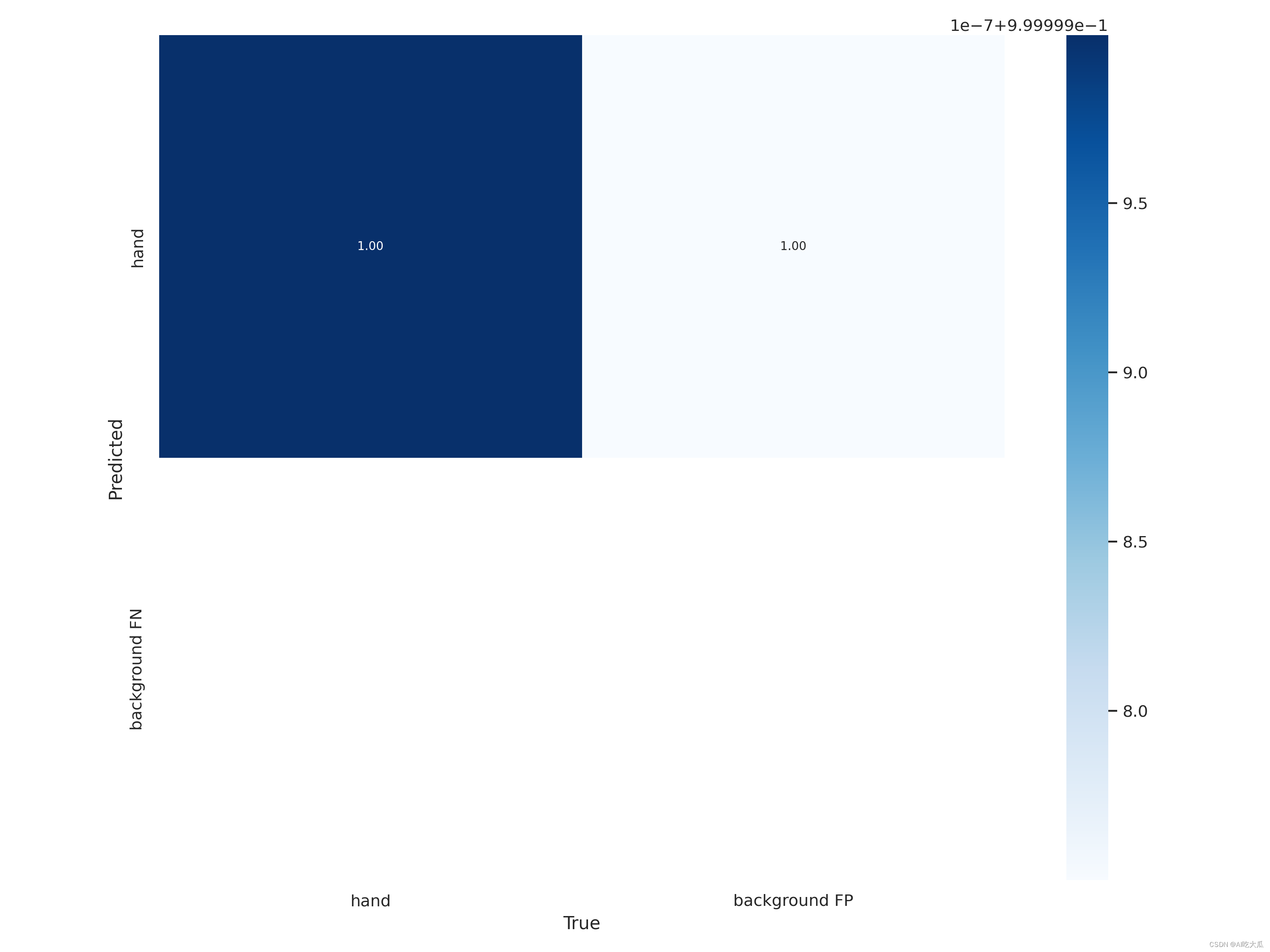
- 这是混淆矩阵(见confusion_matrix.png):
(8)常见的错误
- YOLOv5 BUG修复记录
- 项目安装教程请参考:项目开发使用教程和常见问题和解决方法
- 项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!!!!!!!!
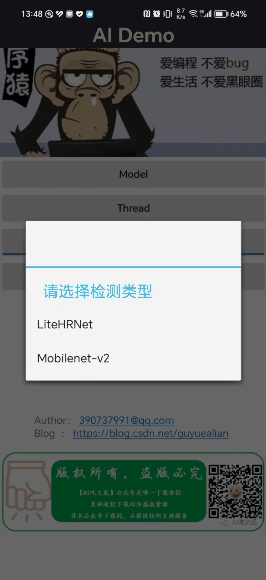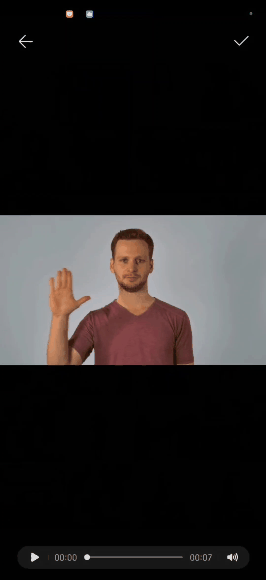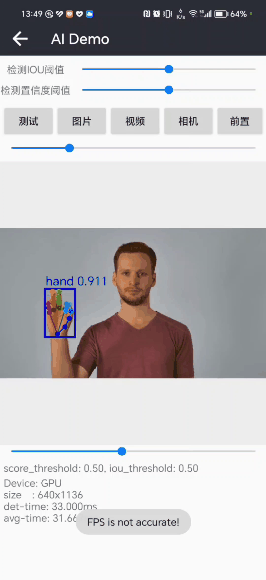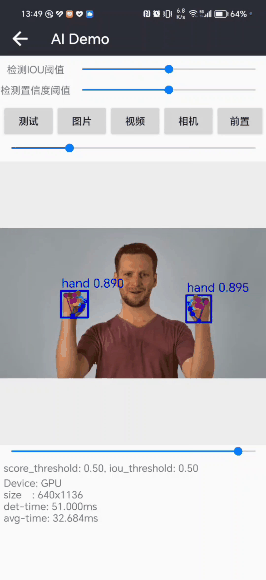
4. Python版本手部检测效果
demo.py文件用于推理和测试模型的效果,填写好配置文件,模型文件以及测试图片即可运行测试了
- 测试图片
# 测试图片(Linux系统)
image_dir='data/test_image' # 测试图片的目录
weights="data/model/yolov5s_640/weights/best.pt" # 模型文件
out_dir="runs/test-result" # 保存检测结果
python demo.py --image_dir $image_dir --weights $weights --out_dir $out_dirWindows系统,请将$image_dir, $weights ,$out_dir等变量代替为对应的变量值即可,如
# 测试图片(Windows系统)
python demo.py --image_dir data/test_image --weights data/model/yolov5s_640/weights/best.pt --out_dir runs/test-result
- 测试视频文件
# 测试视频文件(Linux系统)
video_file="data/test-video.mp4" # path/to/video.mp4 测试视频文件,如*.mp4,*.avi等
weights="data/model/yolov5s_640/weights/best.pt" # 模型文件
out_dir="runs/test-result" # 保存检测结果
python demo.py --video_file $video_file --weights $weights --out_dir $out_dir# 测试视频文件(Windows系统)
python demo.py --video_file data/test-video.mp4 --weights data/model/yolov5s_640/weights/best.pt --out_dir runs/test-result
- 测试摄像头
# 测试摄像头(Linux系统)
video_file=0 # 测试摄像头ID
weights="data/model/yolov5s_640/weights/best.pt" # 模型文件
out_dir="runs/test-result" # 保存检测结果
python demo.py --video_file $video_file --weights $weights --out_dir $out_dir
# 测试摄像头(Windows系统)
python demo.py --video_file 0 --weights data/model/yolov5s_640/weights/best.pt --out_dir runs/test-result
先展示一下手部检测(不含关键点检测)的效果:





如果想进一步提高模型的性能,可以尝试:
- 增加训练的样本数据: 目前有30W+的数据量,建议根据自己的业务场景,采集相关数据,提高模型泛化能力
- 使用参数量更大的模型: 本教程使用的YOLOv5s,其参数量才7.2M,而YOLOv5x的参数量有86.7M,理论上其精度更高,但推理速度也较慢。
- 尝试不同数据增强的组合进行训练
5. 手部检测和手部关键点检测(Python/C++/Android)
项目已经完成Android版本手部检测和手部关键点检测算法开发,APP在普通Android手机上可以达到实时的检测和识别效果,CPU(4线程)约50ms左右,GPU约30ms左右 ,基本满足业务的性能需求。
- 手部关键点检测3:Pytorch实现手部关键点检测(手部姿势估计)含训练代码和数据集https://blog.csdn.net/guyuealian/article/details/133277726
- 手部关键点检测4:Android实现手部关键点检测(手部姿势估计)含源码 可实时检测https://blog.csdn.net/guyuealian/article/details/133931698
- 手部关键点检测5:C++实现手部关键点检测(手部姿势估计)含源码 可实时检测https://blog.csdn.net/guyuealian/article/details/133277748
Android手部关键点检测(手部姿势估计)APP Demo体验:https://download.csdn.net/download/guyuealian/88418582


6.项目源码下载
如需下载项目源码,请WX关注【AI吃大瓜】,回复【手部检测】即可下载
整套项目源码内容包含:手部检测数据集 + 手部检测YOLOv5训练代码和测试代码
(1)手部检测数据集+手部关键点数据集:
手部检测数据集:包含Hand-voc1,Hand-voc2和Hand-voc3,总共60000+张图片;标注格式统一转换为VOC数据格式,标注名称为hand,可用于深度学习手部目标检测模型算法开发。
手部关键点数据集:包含HandPose-v1,HandPose-v2和HandPose-v3,总共80000+张图片;标注了手部区域目标框box,标注名称为hand,同时也标注了手部21个关键点,标注格式统一转换为COCO数据格式,可直接用于深度学习手部关键点检测模型训练。
- 详细说明,请查看《手部关键点(手部姿势估计)数据集(含下载链接)》https://blog.csdn.net/guyuealian/article/details/133277630
(2)手部检测YOLOv5训练代码和测试代码(Pytorch)
- 整套YOLOv5项目工程,含训练代码train.py和测试代码demo.py
- 支持高精度版本yolov5s训练和测试
- 支持轻量化版本yolov5s05_320和yolov5s05_416训练和测试
- 根据本篇博文说明,简单配置即可开始训练:train.py
- 源码包含了训练好的yolov5s,yolov5s05_416和yolov5s05_320模型,配置好环境,可直接运行demo.py
- 测试代码demo.py支持图片,视频和摄像头测试
- 本篇博文是手部检测,不包含手部关键点检测内容, 关于手部关键点检测的方法,可查看《Pytorch实现手部关键点检测(手部姿势估计)》https://blog.csdn.net/guyuealian/article/details/133277726
Android手部关键点检测(手部姿势估计)APP Demo体验:https://download.csdn.net/download/guyuealian/88418582



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











