








最近在研究卷积网络的改性,有必要对各种卷积层的结构深入熟悉一下。为此写下这篇学习笔记。
文章大部分内容来自于网络的各种博客总结,本博文仅仅作为本人学习笔记,不做商业用途。
目录
空间可分离卷积(separable convolution)
深度可分离卷积(depthwise separable convolution)
扩张卷积(空洞卷积 Dilated Convolutions)
反卷积(转置卷积 Transposed Convolutions)
2D卷积
信号处理中,卷积被定义为:一个函数经过翻转和移动后与另一个函数的乘积的积分。

在深度学习中,卷积中的过滤函数是不经过翻转的。故此,深度学习中的卷积本质上就是信号/图像处理中的互相关(cross-correlation)
首先通过下面一张动图,清晰看出什么是卷积
(3*3kernel,padding为1)
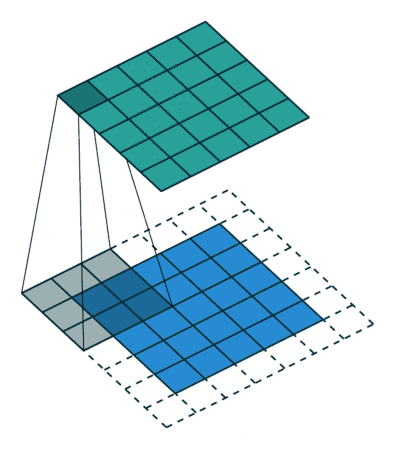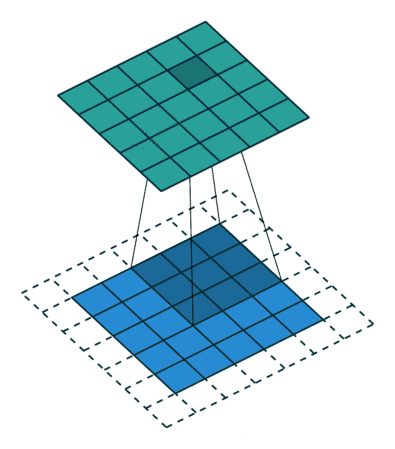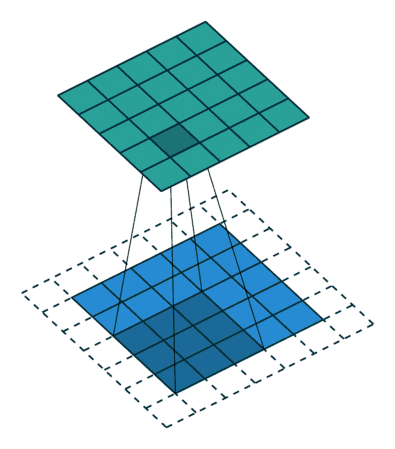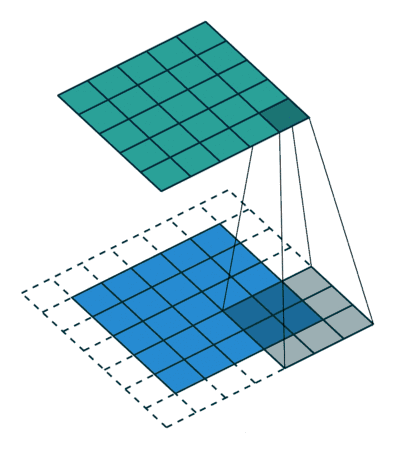
(3*3kernel,padding为0)

执行卷积的目的是从输入中提取有用的特征。在图像处理中,执行卷积操作有诸多不同的过滤函数可供选择,每一种都有助于从输入图像中提取不同的方面或特征,如水平/垂直/对角边等。类似地,卷积神经网络通过卷积在训练期间使用自动学习权重的函数来提取特征。所有这些提取出来的特征,之后会被「组合」在一起做出决策。
CONV的优点:权重共享(weights sharing)和平移不变性(translation invariant),可以考虑像素空间的关系。
单通道版本的卷积操作如下图所示:
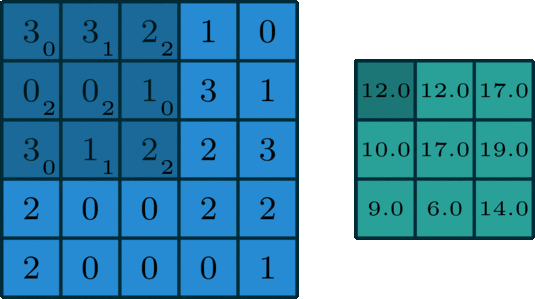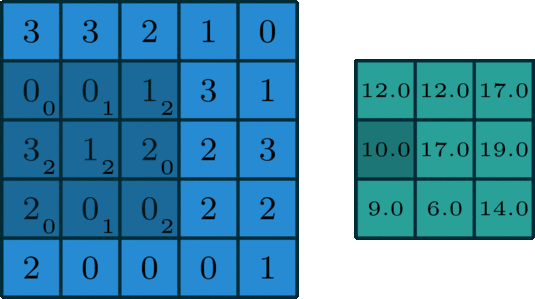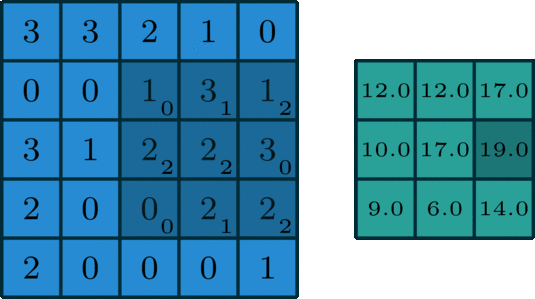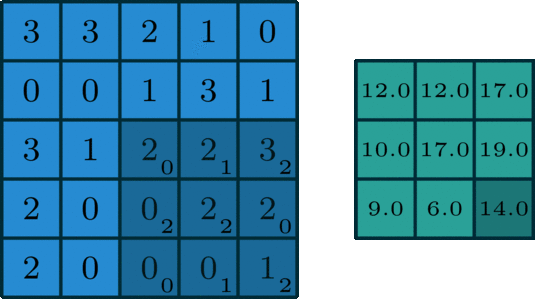
下面再通过动图,清晰看出什么是卷积
(3*3kernel,padding为1)
(3*3kernel,padding为0)
多通道卷积(空间卷积)
对于实际的图片,往往是RGB三通道的。而对于卷积层而言,也是如此,一个卷积层往往也是多个通道组成的,每个通道描述一个方面的特征。
生成一个输出通道,就需要将每一个卷积核应用到前一层的输出通道上,这是一个卷积核级别的操作过程。对所有的卷积核都重复这个过程以生成多通道,之后,这些通道组合在一起共同形成一个单输出通道。设输入层是一个 5 x 5 x 3 矩阵,它有 3 个通道。过滤器则是一个 3 x 3 x 3 矩阵。首先,过滤器中的每个卷积核都应用到输入层的 3 个通道,执行 3 次卷积后得到了尺寸为 3 x 3 的 3 个通道。如下图所示

之后,这 3 个通道都合并到一起(元素级别的加法)组成了一个大小为 3 x 3 x 1 的单通道。这个通道是输入层(5 x 5 x 3 矩阵)使用了过滤器(3 x 3 x 3 矩阵)后得到的结果。
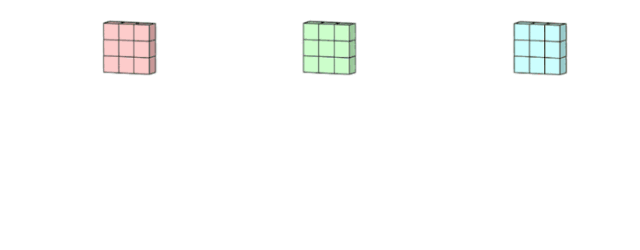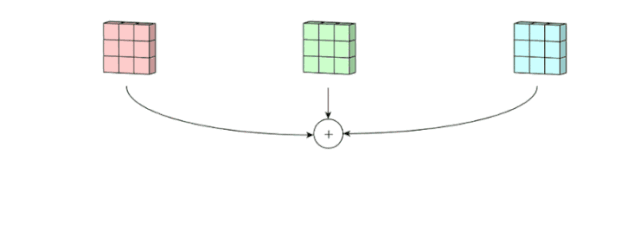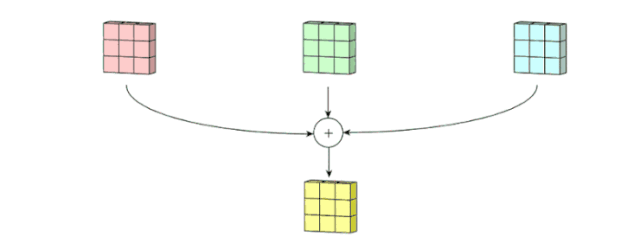
可以将这个过程视作将一个 3D 过滤器矩阵滑动通过输入层。注意,这个输入层和过滤器的深度都是相同的(即通道数=卷积核数)。这个 3D 过滤器仅沿着 2 个方向(图像的高&宽)移动(这也是为什么 3D 过滤器即使通常用于处理 3D 体积数据,但这样的操作还是被称为 2D 卷积)

现在我们可以看到如何在不同深度的层之间实现过渡。假设输入层有 Din 个通道,而想让输出层的通道数量变成 Dout ,我们需要做的仅仅是将 Dout 个过滤器应用到输入层中。每一个过滤器都有 Din 个卷积核,都提供一个输出通道。在应用 Dout 个过滤器后,Dout 个通道可以共同组成一个输出层。标准 2D 卷积。通过使用 Dout 个过滤器,将深度为 Din 的层映射为另一个深度为 Dout 的层

进一步地,对于卷积网络的设计需要记住以下公式:

3D卷积
上一节中最后一张图虽然实现了空间卷积,但是本质上,还是2D卷积。而在 3D 卷积中,过滤器的深度要比输入层的深度更小(卷积核大小<通道大小),结果是,3D 过滤器可以沿着所有 3 个方向移动(高、宽以及图像的通道)。每个位置经过元素级别的乘法和算法都得出一个数值。由于过滤器滑动通过 3D 空间,输出的数值同样也以 3D 空间的形式呈现,最终输出一个 3D 数据。如下图所示:

1*1卷积
对于1*1卷积而言,表面上好像只是feature map每个值乘了一个数,但实际上不仅仅如此,首先由于会经过激活层,所以实际上是进行了非线性映射,其次就是可以改变feature 的channel数目。

上图中描述了:在一个维度为 H x W x D 的输入层上的操作方式。经过大小为 1 x 1 x D 的过滤器的 1 x 1 卷积,输出通道的维度为 H x W x 1。如果我们执行 N 次这样的 1 x 1 卷积,然后将这些结果结合起来,我们能得到一个维度为 H x W x N 的输出层。
在执行计算昂贵的 3 x 3 卷积和 5 x 5 卷积前,往往会使用 1 x 1 卷积来减少计算量。此外,它们也可以利用调整后的线性激活函数来实现双重用途。
空间可分离卷积(separable convolution)
在一个可分离卷积中,我们可以将内核操作拆分成多个步骤。我们用y = conv(x,k)表示卷积,其中y是输出图像,x是输入图像,k是内核。这一步很简单。接下来,我们假设k可以由下面这个等式计算得出:k = k1.dot(k2)。这将使它成为一个可分离的卷积,因为我们可以通过对k1和k2做2个一维卷积来取得相同的结果,而不是用k做二维卷积。

以通常用于图像处理的Sobel内核为例。你可以通过乘以向量[1,0,-1]和[1,2,1] .T获得相同的内核。在执行相同的操作时,你只需要6个而不是9个参数。(如下所示,其实有点类似矩阵的分解,在线性系统的时候学过类似的)

比起卷积,空间可分离卷积要执行的矩阵乘法运算也更少。假设我们现在在 m x m 卷积核、卷积步长=1 、填充=0 的 N x N 图像上做卷积。传统的卷积需要进行 (N-2) x (N-2) x m x m 次乘法运算,而空间可分离卷积只需要进行 N x (N-2) x m + (N-2) x (N-2) x m = (2N-2) x (N-2) x m 次乘法运算。空间可分离卷积与标准的卷积的计算成本之比为:
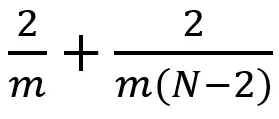
深度可分离卷积(depthwise separable convolution)
空间可分离卷积(上一小节),而在深度学习中,深度可分离卷积将执行一个空间卷积,同时保持通道独立,然后进行深度卷积操作。
假设我们在一个16输入通道和32输出通道上有一个3x3的卷积层。那么将要发生的就是16个通道中的每一个都由32个3x3的内核进行遍历,从而产生512(16x32)的特征映射。接下来,我们通过将每个输入通道中的特征映射相加从而合成一个大的特征映射。由于我们可以进行此操作32次,因此我们得到了期望的32个输出通道。
那么,针对同一个示例,深度可分离卷积的表现又是怎样的呢?我们遍历16个通道,每一个都有一个3x3的内核,可以给出16个特征映射。现在,在做任何合并操作之前,我们将遍历这16个特征映射,每个都含有32个1x1的卷积,然后才逐此开始添加。这导致与上述4608(16x32x3x3)个参数相反的656(16x3x3 + 16x32x1x1)个参数。
下面再进行详细说明。
前面部分所提到的 2D 卷积核 1x1 卷积。让我们先快速过一下标准的 2D 卷积。举一个具体的案例,假设输入层的大小为 7 x 7 x 3(高 x 宽 x 通道),过滤器大小为 3 x 3 x 3,经过一个过滤器的 2D 卷积后,输出层的大小为 5 x 5 x 1(仅有 1 个通道)。如下图所示:

一般来说,两个神经网络层间应用了多个过滤器,现在假设过滤器个数为 128。128 次 2D 卷积得到了 128 个 5 x 5 x 1 的输出映射。然后将这些映射堆叠为一个大小为 5 x 5 x 128 的单个层。空间维度如高和宽缩小了,而深度则扩大了。如下图所示

接下来看看使用深度可分离卷积如何实现同样的转换。
首先,我们在输入层上应用深度卷积。我们在 2D 卷积中分别使用 3 个卷积核(每个过滤器的大小为 3 x 3 x 1),而不使用大小为 3 x 3 x 3 的单个过滤器。每个卷积核仅对输入层的 1 个通道做卷积,这样的卷积每次都得出大小为 5 x 5 x 1 的映射,之后再将这些映射堆叠在一起创建一个 5 x 5 x 3 的图像,最终得出一个大小为 5 x 5 x 3 的输出图像。这样的话,图像的深度保持与原来的一样。

深度可分离卷积—第一步:在 2D 卷积中分别使用 3 个卷积核(每个过滤器的大小为 3 x 3 x 1),而不使用大小为 3 x 3 x 3 的单个过滤器。每个卷积核仅对输入层的 1 个通道做卷积,这样的卷积每次都得出大小为 5 x 5 x 1 的映射,之后再将这些映射堆叠在一起创建一个 5 x 5 x 3 的图像,最终得出一个大小为 5 x 5 x 3 的输出图像。
深度可分离卷积的第二步是扩大深度,我们用大小为 1x1x3 的卷积核做 1x1 卷积。每个 1x1x3 卷积核对 5 x 5 x 3 输入图像做卷积后都得出一个大小为 5 x 5 x1 的映射。

这样的话,做 128 次 1x1 卷积后,就可以得出一个大小为 5 x 5 x 128 的层。

深度可分离卷积完成这两步后,同样可以将一个 7 x 7 x 3 的输入层转换为 5 x 5 x 128 的输出层。

故此,从本质上说,深度可分离卷积就是3D卷积kernel的分解(在深度channel上的分解),而空间可分离卷积就是2D卷积kernel的分解(在WH上的分解)
因此,做深度可分离卷积的优势是什么?高效!相比于 2D 卷积,深度可分离卷积的执行次数要少得多。
让我们回忆一下 2D 卷积案例中的计算成本:128 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算总数为 128 x 3 x 3 x 3 x 5 x 5 = 86,400 次。
那可分离卷积呢?在深度卷积这一步,有 3 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算次数为 3x3x3x1x5x5 = 675 次;在第二步的 1x1 卷积中,有 128 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算次数为 128 x 1 x 1 x 3 x 5 x 5 = 9,600 次。因此,深度可分离卷积共需要进行的乘法运算总数为 675 + 9600 = 10,275 次,花费的计算成本仅为 2D 卷积的 12%。
深度可分离卷积与 2D 卷积之间的乘法运算次数之比为:

分组卷积(Group convolution)
Group convolution 分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。

下面描述分组卷积是如何实现的。首先,传统的 2D 卷积步骤如下图所示。在这个案例中,通过应用 128 个过滤器(每个过滤器的大小为 3 x 3 x 3),大小为 7 x 7 x 3 的输入层被转换为大小为 5 x 5 x 128 的输出层。针对通用情况,可概括为:通过应用 Dout 个卷积核(每个卷积核的大小为 h x w x Din),可将大小为 Hin x Win x Din 的输入层转换为大小为 Hout x Wout x Dout 的输出层。

在分组卷积中,过滤器被拆分为不同的组,每一个组都负责具有一定深度的传统 2D 卷积的工作。下图的案例表示得更清晰一些。

上图表示的是被拆分为 2 个过滤器组的分组卷积。在每个过滤器组中,其深度仅为名义上的 2D 卷积的一半(Din / 2),而每个过滤器组都包含 Dout /2 个过滤器。第一个过滤器组(红色)对输入层的前半部分做卷积([:, :, 0:Din/2]),第二个过滤器组(蓝色)对输入层的后半部分做卷积([:, :, Din/2:Din])。最终,每个过滤器组都输出了 Dout/2 个通道。整体上,两个组输出的通道数为 2 x Dout/2 = Dout。之后,我们再将这些通道堆叠到输出层中,输出层就有了 Dout 个通道。
扩张卷积(空洞卷积 Dilated Convolutions)
扩张卷积引入另一个卷积层的参数被称为扩张率。这定义了内核中值之间的间距。扩张速率为2的3x3内核将具有与5x5内核相同的视野,而只使用9个参数。 想象一下,使用5x5内核并删除每个间隔的行和列。(如下图所示)
系统能以相同的计算成本,提供更大的感受野。扩张卷积在实时分割领域特别受欢迎。 在需要更大的观察范围,且无法承受多个卷积或更大的内核,可以才用它。

直观上,空洞卷积通过在卷积核部分之间插入空间让卷积核「膨胀」。这个增加的参数 l(空洞率)表明了我们想要将卷积核放宽到多大。下图显示了当 l=1,2,4 时的卷积核大小。(当l=1时,空洞卷积就变成了一个标准的卷积)

在图像中,3 x 3 的红点表明经过卷积后的输出图像的像素是 3 x 3。虽然三次空洞卷积都得出了相同维度的输出图像,但是模型观察到的感受野(receptive field)是大不相同的。l=1 时,感受野为 3 x 3;l=2 时,感受野是 7 x 7;l=3 时,感受野增至 15x15。有趣的是,伴随这些操作的参数数量本质上是相同的,不需要增加参数运算成本就能「观察」大的感受野。正因为此,空洞卷积常被用以低成本地增加输出单元上的感受野,同时还不需要增加卷积核大小,当多个空洞卷积一个接一个堆叠在一起时,这种方式是非常有效的。
反卷积(转置卷积 Transposed Convolutions)
对于反卷积的,之前本人在复现老师的FSRCNN的时候已经用过了(执行upsample操作)。详细可参考博文《基于pytorch的FSRCNN的复现》《学习笔记之——基于pytorch的FSRCNN》

octave convolution
关于octconv的介绍可以参考本人之前博文《实验笔记之——基于SRResNet的Octave Convolution实验记录》
来自论文《Drop an Octave Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution》
是一种将feature map分为高频与低频特征的特殊的卷积层。可以降低存储量与计算量,增加感受野。即插即用。
参考资料:
https://blog.csdn.net/Chaolei3/article/details/79374563
https://zhuanlan.zhihu.com/p/28749411
http://www.cnblogs.com/marsggbo/p/9737991.html















 1602
1602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









