







MVSNet改进
一、ARAI-MVSNet三维重建模型
1、Abstract
多视图立体(MVS)是几何计算机视觉中的一个基本问题,其目的是利用已知相机参数的多视图图像重建场景。然而,主流方法用固定的全像素深度范围和等深度间隔划分来表示场景,这将导致深度平面利用率不足和深度估计不精确。本文提出了一种新的多级粗精框架来实现自适应全像素深度范围和深度间隔。我们在第一阶段预测粗深度图,然后在第二阶段提出自适应深度范围预测模块,利用参考图像和第一阶段获得的深度图对场景进行缩放,并为后续阶段预测更准确的全像素深度范围。
在第三和第四阶段,我们提出了一个自适应深度间隔调整模块,以实现逐像素深度范围的自适应可变间隔划分。该模块中的深度区间分布采用Z-score归一化,可以在潜在地真实深度值周围分配密集的深度假设平面,反之亦然,以获得更准确的深度估计。在四种广泛使用的基准数据集(DTU, TnT, BlendedMVS, ETH 3D)上进行的大量实验表明,我们的模型达到了最先进的性能,并产生了具有竞争力的泛化能力。
2、Introduction
作者参考CasMVSNet设计了一种新的高效且有效的框架。以往研究都是用固定的全像素深度范围和等深度间隔分割来表示对象,会产生两个问题。第一、超出固定深度范围的物体无法重建,可能导致重建质量低于标准。第二、由于目标表面通常是异构的,采用等深度间隔划分策略可能导致预测深度值与实际地面真值(gt)深度值之间存在差异,影响重建的精度。提出Adaptive Depth Range Prediction (ADRP) 模块和Adaptive Depth Interval Adjustment (ADIA)模块,该机制利用z-score来计算每个深度平面的偏移,用前一阶段的深度图来实现逐像素深度范围的自适应深度间隔划分。最后还提出了一个空间金字塔特征提取网络(ASPFNet),提取上下文感知特征与更大的感受野融合。
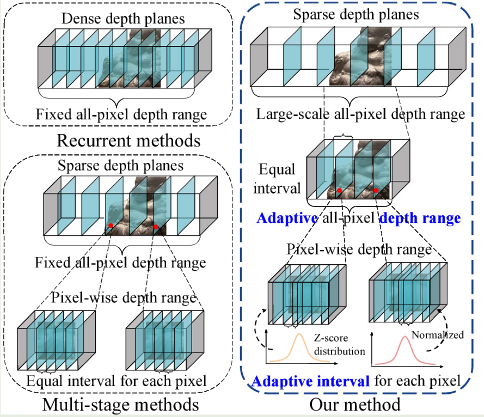
深度假设方法示意图
3.1、 ADRP模块
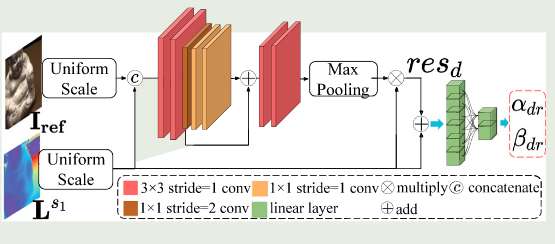
第一步先实现全像素范围的粗深度图估计,将初始深度图的最大和最小深度值作为第二阶段深度估计的边界,记为
L
s
1
(
x
m
i
n
)
\mathbf{L}^{s_{1}} ( x_{m i n} )
Ls1(xmin)和
L
s
1
(
x
m
a
x
)
\mathbf{L}^{s_{1}} ( x_{m a x} )
Ls1(xmax),
x
m
a
x
和
x
m
i
n
x_{m a x} \, \, \, \mathrm{和} \, \, \, x_{m i n}
xmax和xmin分别代表最大和最小深度值处像素的位置。首先将
L
s
\mathrm{L}^{s}
Ls(第一阶段的深度图)和
I
r
e
f
\mathbf{I}_{r e f}
Iref(参考图)输入SCN网络(如图)计算出
α
d
r
\alpha_{d r}
αdr和
β
d
r
\beta_{d r}
βdr,用来调整第二阶段的深度边界,计算公式如下所示:
d
m
i
n
s
2
=
L
s
1
(
x
m
i
n
)
+
α
d
r
×
σ
^
(
x
m
i
n
)
d
m
a
x
s
2
=
L
s
1
(
x
m
a
x
)
+
β
d
r
×
σ
^
(
x
m
a
x
)
\begin{array} {l} {{{{\bf d}_{m i n}^{s_{2}}={\bf L}^{s_{1}} ( x_{m i n} )+\alpha_{d r} \times\hat{\sigma} ( x_{m i n} )}}} \\ {{{{\bf d}_{m a x}^{s_{2}}={\bf L}^{s_{1}} ( x_{m a x} )+\beta_{d r} \times\hat{\sigma} ( x_{m a x} )}}} \\ \end{array}
dmins2=Ls1(xmin)+αdr×σ^(xmin)dmaxs2=Ls1(xmax)+βdr×σ^(xmax)
其中
σ
^
(
x
m
i
n
)
\hat{\sigma} ( x_{m i n} )
σ^(xmin)和
σ
^
(
x
m
a
x
)
\hat{\sigma} ( x_{m a x} )
σ^(xmax)是像素最小和最大位置的标准差,用来调整深度范围,计算的公式如下所示:
σ
^
(
x
i
)
=
∑
j
D
P
j
s
1
(
x
i
)
⋅
(
d
j
s
1
(
x
i
)
−
L
s
1
(
x
i
)
)
2
\hat{\sigma} ( x_{i} )=\sqrt{\sum_{j}^{D} \mathbf{P}_{j}^{s_{1}} ( x_{i} ) \cdot\left( \mathbf{d}_{j}^{s_{1}} ( x_{i} )-\mathbf{L}^{s_{1}} ( x_{i} ) \right)^{2}}
σ^(xi)=∑jDPjs1(xi)⋅(djs1(xi)−Ls1(xi))2
x
i
∈
[
x
m
i
n
,
x
m
a
x
]
x_{i} \in[ x_{m i n}, x_{m a x} ]
xi∈[xmin,xmax],
P
j
s
1
\mathbf{P}_{j}^{s_{1}}
Pjs1是第一阶段逐像素的深度概率分布,
d
j
s
1
\mathbf{d}_{j}^{s_{1}}
djs1是第一阶段的深度假设平面,
P
j
s
1
(
x
i
)
\mathbf{P}_{j}^{s_{1}} ( x_{i} )
Pjs1(xi)是第一阶段的中逐像素的深度值的可能概率。SCN模块推导公式如下所示:
r
e
s
d
=
m
a
x
p
(
w
1
(
[
L
s
1
,
I
r
e
f
]
)
⊙
L
s
1
)
,
α
d
r
,
β
d
r
=
w
2
(
r
e
s
d
+
L
s
1
)
,
\begin{array} {l} {{{r e s_{d}=m a x p ( \mathbf{w}_{1} ( [ \mathbf{L}^{s 1}, \mathbf{I}_{\mathbf{r e f}} ] ) \odot\mathbf{L}^{s 1} ) \,,}}} \\ {{{\alpha_{d r}, \beta_{d r}=\mathbf{w}_{2} ( r e s_{d}+\mathbf{L}^{s 1} ) \,,}}} \\ \end{array}
resd=maxp(w1([Ls1,Iref])⊙Ls1),αdr,βdr=w2(resd+Ls1),
输入的是第一阶段粗估计深度图以及参考图,
w
1
\mathbf{w}_{1}
w1是卷积层提取深度残差信息
r
e
s
d
r e s_{d}
resd,再将深度残差信息与粗深度图相加,最后通过线性层计算出
α
d
r
\alpha_{d r}
αdr和
β
d
r
\beta_{d r}
βdr。
3.2、 ADIA模块
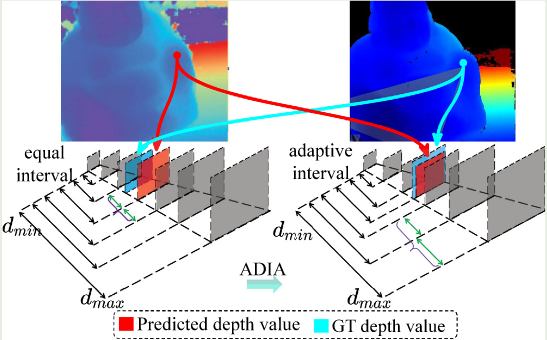
本文提出了一种自适应变间隔分割策略,在潜在地真深度值附近分配更密集的深度假设平面,在远离潜在地真深度值的地方分配相对稀疏的深度假设平面,而不是采用等间隔分割进行像素深度估计。具体计算公式如下所示:
d
i
s
3
(
x
)
=
d
i
s
3
(
x
)
+
d
^
i
n
t
e
r
s
3
(
x
)
×
o
f
f
s
e
t
i
(
x
)
{\bf d}_{i}^{s_{3}} ( x )={\bf d}_{i}^{s_{3}} ( x )+\hat{{\bf d}}_{i n t e r}^{s_{3}} ( x ) \times{\bf o f f s e t}_{i} ( x )
dis3(x)=dis3(x)+d^inters3(x)×offseti(x)
d
i
s
3
(
x
)
{\bf d}_{i}^{s_{3}} ( x )
dis3(x)是第三阶段,每个像素的的深度假设平面,
d
^
i
n
t
e
r
s
3
(
x
)
\hat{{\bf d}}_{i n t e r}^{s_{3}} ( x )
d^inters3(x)是第三阶段每个像素等间隔,
o
f
f
s
e
t
i
(
x
)
{\bf o f f s e t}_{i} ( x )
offseti(x)是每个等区间的权值,根据不同权值利用Z-score实现对等区间的缩放。通过权值关注到需要重点关注的区域的深度估计。具体计算流程如下:
首先,作者用上一阶段的深度图和概率体来计算像素的标准偏差,计算公式如下:
σ
^
(
x
)
=
∑
j
D
P
j
s
2
(
x
)
⋅
(
d
j
s
2
(
x
)
−
L
s
2
(
x
)
)
2
\hat{\sigma} ( x )=\sqrt{\sum_{j}^{D} \mathbf{P}_{j}^{s_{2}} ( x ) \cdot\left( \mathbf{d}_{j}^{s_{2}} ( x )-\mathbf{L}^{s_{2}} ( x ) \right)^{2}}
σ^(x)=∑jDPjs2(x)⋅(djs2(x)−Ls2(x))2
然后,我们利用上面的结果来计算当前阶段的像素深度范围,即像素深度范围的上边界和下边界,具体公式如下所示:
d
m
i
n
s
3
(
x
)
=
L
s
2
(
x
)
−
σ
^
(
x
)
,
d
m
a
x
s
3
(
x
)
=
L
s
2
(
x
)
+
σ
^
(
x
)
D
s
3
(
x
)
=
[
d
m
i
n
s
3
(
x
)
,
…
,
d
i
s
3
(
x
)
,
…
,
d
m
a
x
s
3
(
x
)
]
\begin{array} {l} {{{{\bf d}_{m i n}^{s_{3}} ( x )={\bf L}^{s_{2}} ( x )-\hat{\sigma} ( x ), {\bf d}_{m a x}^{s_{3}} ( x )={\bf L}^{s_{2}} ( x )+\hat{\sigma} ( x )}}} \\ {{{{\bf D}^{s 3} ( x )=[ {\bf d}_{m i n}^{s_{3}} ( x ), \ldots, {\bf d}_{i}^{s_{3}} ( x ), \ldots, {\bf d}_{m a x}^{s_{3}} ( x ) ]}}} \\ \end{array}
dmins3(x)=Ls2(x)−σ^(x),dmaxs3(x)=Ls2(x)+σ^(x)Ds3(x)=[dmins3(x),…,dis3(x),…,dmaxs3(x)]
其中,
D
s
3
(
x
)
{\bf D}^{s 3} ( x )
Ds3(x)代表第三阶段的逐像素深度假设平面,标准等间隔划分的计算公式如下所示:
d
^
i
n
t
e
r
s
3
(
x
)
=
d
m
a
x
s
3
(
x
)
−
d
m
i
n
s
3
(
x
)
D
n
u
m
\hat{\bf d}_{i n t e r}^{s_{3}} ( x )=\frac{{\bf d}_{m a x}^{s_{3}} ( x )-{\bf d}_{m i n}^{s_{3}} ( x )} {{\bf D}_{n u m}}
d^inters3(x)=Dnumdmaxs3(x)−dmins3(x)
受Z-score的启发,我们利用前一阶段的深度值(视为平均值)和标准偏差来计算每个平面的偏移量,并使用softmax来实现归一化,标准偏差权重的计算公式如下:
o
f
f
s
e
t
i
(
x
)
=
s
o
f
t
m
a
x
(
d
i
s
3
(
x
)
−
L
s
2
(
x
)
σ
^
(
x
)
)
\mathrm{o f f s e t}_{i} ( x )=s o f t m a x ( \frac{{\bf d}_{i}^{s_{3}} ( x )-{\bf L}^{s_{2}} ( x )} {\hat{\sigma} ( x )} )
offseti(x)=softmax(σ^(x)dis3(x)−Ls2(x))
4.对比实验结果
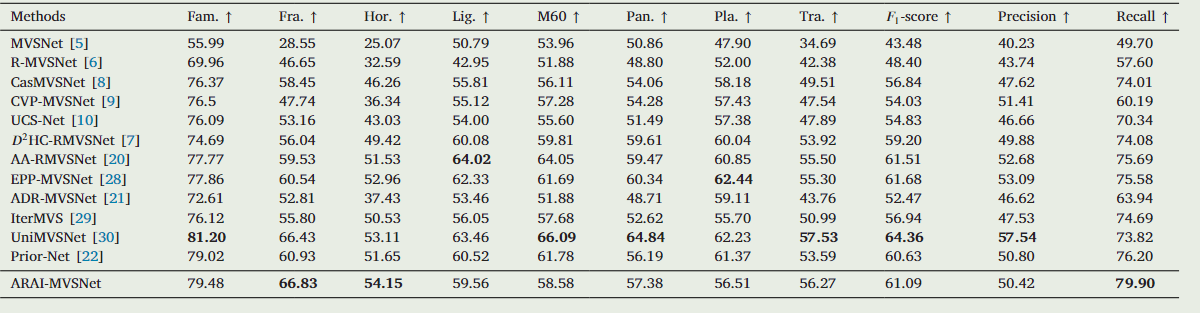
TNT结果
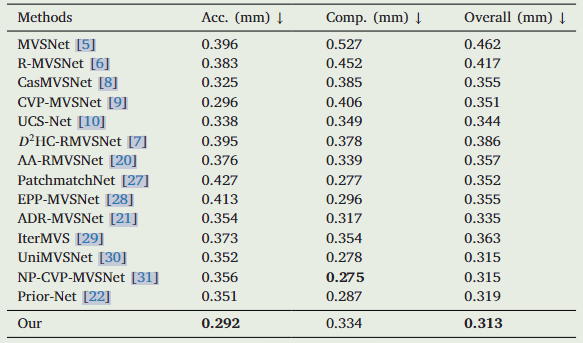
DTU结果
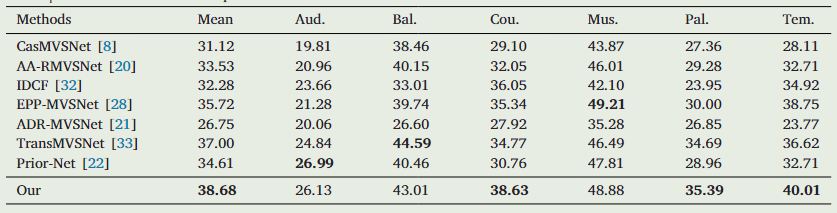
Tank and Temple 结果
二、NR-MVSNet弱纹理以及重复纹理改进
code:https://github.com/YuhsiHu?tab=repositories
1、Abstract
基于多视图3D点云重建模型与传统方法相比,虽然已经取得良好性能,但仍存在明显缺陷,比如粗到精的深度估计策略存在误差累积以及深度假设时均匀采样的不准确。因此,针对以上问题我们提出DHNC和DRRA模块来改善,具体来说,我们设计了 dhnc 模块来生成更有效的深度假设,它从具有相同法线的相邻像素中收集深度假设。因此,预测的深度可以更平滑、更准确,特别是在无纹理和重复的纹理区域。另一方面,我们通过DRRA模块在粗阶段更新初始深度图,该模块可以将参考特征和代价体特征结合,提高粗阶段的深度估计精度,解决累积误差问题。
2、Introduction
MVSNet与SFM的方法类似,核心工作均是测量相似图块之间的相似度来重建三维点云。在MVS重建任务中,我们期望得到相邻视图之间有效的区别变化,生成代价体,用于图像相关性匹配。然而,粗阶段特征变得平滑,一些细节在几个池化和卷积滤波器之后丢失。因此,邻居视图之间的微小变化不能被捕获,特别是对于无纹理、重复的纹理区域。有效的深度图输入可以生成更准确的深度假设,这对最终的重建结果至关重要。而对于级联结构的重建工作中,粗阶段的深度图是后续阶段的输入。因此,尽可能保证每一个阶段深度图的准确性,可以有效解决误差累积的问题。主要创新点有以下三点:
1)提出了一种新的基于正态一致性的深度假设模块,该模块从相邻区域收集信息,显著提高了深度假设的准确性,特别是在无纹理和重复区域。
2)为了提高粗估计阶段的深度估计精度,解决累积误差问题,提出了一种融合关注参考特征和代价体特征的深度细化模块。
模型pipline如下所示:
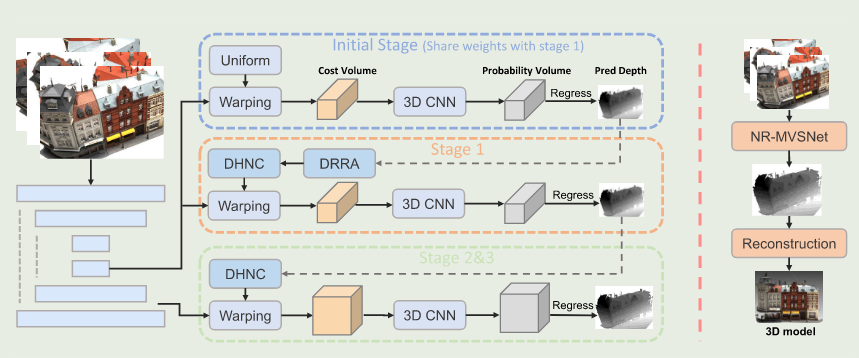
3.1、Depth Hypotheses Based on Normal Consistency(DHNC)
基于学习的方法通常使用均匀采样生成深度假设。然而,最终的预测深度图可能不太平滑,因为以这种方式没有考虑相邻像素的相关性。来自同一物理平面的像素都没有相同的深度值。相反,这些像素的法线在 3d 空间中是一致的。因此,我们提出了DHNC模块来利用自适应邻居的法线来获得更精确的深度假设。
首先,在像素点
p
p
p处给定上一阶段深度估计的预测值
D
k
−
1
D_{k-1}
Dk−1,我们根据不确定性估计置信度来动态调整深度范围
R
k
R_{k}
Rk(参考文献USC-Net模型)。像素点
p
p
p的在对应阶段的动态调整深度范围
R
k
R_{k}
Rk计算方法如下所示:
R
k
r
=
[
D
k
−
1
−
λ
U
k
−
1
,
D
k
−
1
+
λ
U
k
−
1
]
R_{k}^{r}=[ D_{k-1}-\lambda U_{k-1}, D_{k-1}+\lambda U_{k-1} ]
Rkr=[Dk−1−λUk−1,Dk−1+λUk−1]
λ
\lambda
λ是标量区间参数,
U
k
−
1
U_{k-1}
Uk−1是上一阶段深度估计的不确定值,其是从概率体中学习得到。然后,我们在动态调整深度范围
R
k
R_{k}
Rk内进行均匀采样,计算出深度范围假设
D
k
r
~
=
{
D
~
k
,
j
r
}
j
=
1
M
k
r
\tilde{\mathbf{D}_{k}^{r}}= \{\tilde{D}_{k, j}^{r} \}_{j=1}^{M_{k}^{r}}
Dkr~={D~k,jr}j=1Mkr。
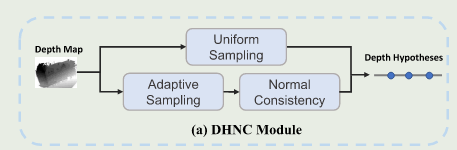
在第二个分支中,我们根据相邻像素的法线找到深度正态假设。我们在像素
p
p
p处定义一个静态领域
{
p
j
}
j
=
1
M
k
n
\{p_{j} \}_{j=1}^{M_{k}^{n}}
{pj}j=1Mkn,通过学习偏移量对领域内像素位置进行自适应更新,
Δ
p
j
\Delta p_{j}
Δpj为偏移量,
p
j
=
p
j
+
Δ
p
j
\ p_{j}=p_{j}+\Delta p_{j}
pj=pj+Δpj。我们计算3D空间中像素法线,则静态领域内的像素
p
j
\ p_{j}
pj的法线求取如下所示:
n
=
(
A
⊤
A
)
−
1
A
⊤
1
∥
(
A
⊤
A
)
−
1
A
⊤
1
∥
2
\mathbf{n}=\frac{\left( \mathbf{A}^{\top} \mathbf{A} \right)^{-1} \mathbf{A}^{\top} \mathbf{1}} {\left\| \left( \mathbf{A}^{\top} \mathbf{A} \right)^{-1} \mathbf{A}^{\top} \mathbf{1} \right\|_{2}}
n=∥(A⊤A)−1A⊤1∥2(A⊤A)−1A⊤1
A
A
A是
p
j
\ p_{j}
pj附近的坐标位置,1为全是1的矩阵,请注意,给定深度图的表面法线计算是一种固定权重的方法,不需要可学习的参数。我们对像素
p
p
p自适应领域像素
p
j
\ p_{j}
pj的表面法线来计算像素
p
p
p的深度正态假设(depth normal hypotheses)。用领域像素
p
j
\ p_{j}
pj的三维坐标和它的法线构成切平面,我们将像素点
p
p
p的三维点投影到这个切面上,得到新的三维点
p
j
′
p_{j}^{\prime}
pj′,具体计算公式和展示图如下:
p
j
′
=
p
+
n
j
n
j
⋅
(
p
j
−
p
)
∥
n
j
∥
2
p_{j}^{\prime}=p+\mathbf{n_{j}} \frac{\mathbf{n_{j}} \cdot( p_{j}-p )} {\| \mathbf{n_{j}} \|_{2}}
pj′=p+nj∥nj∥2nj⋅(pj−p)

最终,我们利用投影点
{
p
j
′
}
\{p_{j}^{\prime}\}
{pj′}和相机内参来计算深度正态假设
D
~
k
n
=
{
D
~
k
,
j
n
}
j
=
1
M
k
n
.
\tilde{\mathbf{D}}_{k}^{n}=\{\tilde{D}_{k, \, j}^{n} \}_{j=1}^{M_{k}^{n}}.
D~kn={D~k,jn}j=1Mkn.整体的深度假设范围如下:
D
~
k
=
D
~
k
r
∪
D
~
k
n
\tilde{\mathbf{D}}_{k}=\tilde{\mathbf{D}}_{k}^{r} \cup\tilde{\mathbf{D}}_{k}^{n}
D~k=D~kr∪D~kn
总数量的深度假设为
M
k
=
M
k
r
+
M
k
n
.
M_{k}=M_{k}^{r}+M_{k}^{n}.
Mk=Mkr+Mkn.
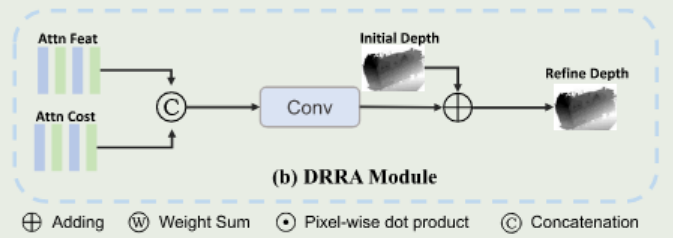
3.2、Depth Refinement With Reliable Attention(DRRA)
级联重建架构中,粗阶段的代价体是不可靠的,其预测出的深度图不是很准确,容易导致后续阶段出现误差累计。因此,本研究提出的DRRA可以将代价体的特征与参考图的特征进行融合。概率体积代表了不同假设中相似性的概率,也代表了代价体在不同深度假设中的重要性。对于初始深度图和参考图特征的提取是先将两者拼接,利用通过Conve卷积,再结合Mini-ViT实现对全局特征的提取。具体如下图所示:
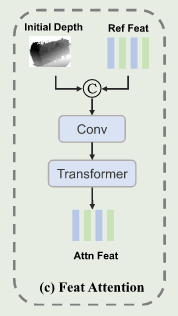
具体实现是将参考特征图与初始深度图定义为
F
F
F和
D
~
\tilde{\mathbf{D}}
D~,拼接后利用卷积层来减少特征融合的通道数。
F
c
o
o
n
=
f
(
[
F
;
D
~
]
)
F^{c o o n}=f ( [ F ; \tilde{D} ] )
Fcoon=f([F;D~])**。**与此同时,为了可以更好挖掘参考图与源视图中的相似性,我们引入代价体注意力方法,代价体表示为
V
∈
R
C
×
M
×
H
×
W
\mathbf{V} \in\ \mathbb{R}^{C \times M \times\ H \times W}
V∈ RC×M× H×W,概率体表示为
P
∈
R
M
×
H
×
W
\mathbf{P} \in\ \mathbb{R}^{ M \times\ H \times W}
P∈ RM× H×W,其中
M
M
M为上深度假设数,
C
C
C为通道数。首先求和得到
V
′
∈
R
C
×
H
×
W
,
\mathbf{V}^{\prime} \in\mathbb{R}^{C \times H \times W},
V′∈RC×H×W,具体计算公式如下:
V
m
,
h
,
w
′
=
∑
c
=
1
C
P
m
,
h
,
w
⊙
V
c
,
m
,
h
,
w
\mathbf{V}_{m, h, w}^{\prime}=\sum_{c=1}^{C} \mathbf{P}_{m, h, w} \odot\mathbf{V}_{c, m, h, w}
Vm,h,w′=∑c=1CPm,h,w⊙Vc,m,h,w
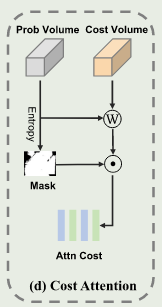
对于无纹理和重复纹理区域,他们在代价体中的相似特征对于深度细化是没有用处的。因此,为了测量相似性的置信度,计算概率体的熵图
E
∈
R
H
×
W
\mathbf{E} \in\mathbb{R}^{H \times W}
E∈RH×W,计算公式如下:
E
h
,
w
=
−
1
log
M
∑
m
=
1
M
P
m
,
h
,
w
log
(
P
m
,
h
,
w
)
E_{h, w}=-\frac{1} {\operatorname{l o g} M} \sum_{m=1}^{M} \mathbf{P}_{m, h, w} \operatorname{l o g} ( \mathbf{P}_{m, h, w} )
Eh,w=−logM1∑m=1MPm,h,wlog(Pm,h,w)
深度置信图
U
=
1
−
E
U=1-E
U=1−E。置信度分数较低的相似特征可能是错误的,然后我们合并置信度阈值来忽略注意力 代价体。
V
c
,
h
,
w
a
t
t
n
=
{
V
c
,
h
,
w
′
i
f
U
h
,
w
>
τ
0
,
o
t
h
e
r
w
i
s
e
{\bf V}_{c, h, w}^{a t t n}=\left\{\begin{array} {l l} {{{{\bf V}_{c, h, w}^{\prime}}}} & {{{\mathrm{~ i f ~} {\bf U}_{h, w} > \tau}}} \\ {{{0,}}} & {{{\mathrm{~ o t h e r w i s e}}}} \\ \end{array} \right.
Vc,h,wattn={Vc,h,w′0, if Uh,w>τ otherwise
τ
\tau
τ为置信度阈值。在获得注意参考特征和代价体特征后,通过融合两个输出来构建高维特征,然后使用卷积层学习残差深度值。
D
~
′
=
f
(
[
F
a
t
t
n
;
V
a
t
t
n
]
)
\tilde{D}^{\prime}=f ( [ F^{a t t n} ; V^{a t t n} ] )
D~′=f([Fattn;Vattn])
最终模型使用的损失函数与MVSNet一样。概率体和代价体特征融合的流程图如下所示:
三.文章下载地址
1、https://www.sciencedirect.com/science/article/pii/S0031320323005836。
附件:https://ars.els-cdn.com/content/image/1-s2.0-S0031320323005836-mmc1.pdf
2、https://www.ieee.org/publications/rights/index.html
3、
思考
有什么想法或心得体会,都可以拿出来分享下。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









