







Code:https://github.com/TQTQliu/MVSGaussian
Article:https://arxiv.org/pdf/2405.12218
1、Abstract
我们提出了一种新的可泛化的三维高斯表示方法MVS-Gaussion,该方法来源于多视点立体(MVS),可以有效地重建未见过的场景。具体来说,1)我们利用MVS对几何感知高斯表示进行编码,并将其解码为高斯参数。(简单理解就是利用MVS代替Clomp生成场景的初始化点云)2)为了进一步提高性能,我们提出了一种混合高斯渲染,它集成了一种高效的体渲染设计,用于新的视图合成。(Nerf和3D-GS两种渲染方式的混合使用)3)为了支持特定场景的快速微调,我们引入了一种多视图几何一致聚合策略,对可泛化的模型生成的点云进行有效聚合,作为逐场景优化的初始化。与之前基于可泛化的 NERF的方法(通常需要几分钟的微调和几秒钟的渲染)相比,MVS-Gaussion实现了每个场景的实时渲染和更好的合成质量。与普通的 3D-GS算法相比,MVS-Gaussion算法以更少的训练计算量实现了更好的视图合成。
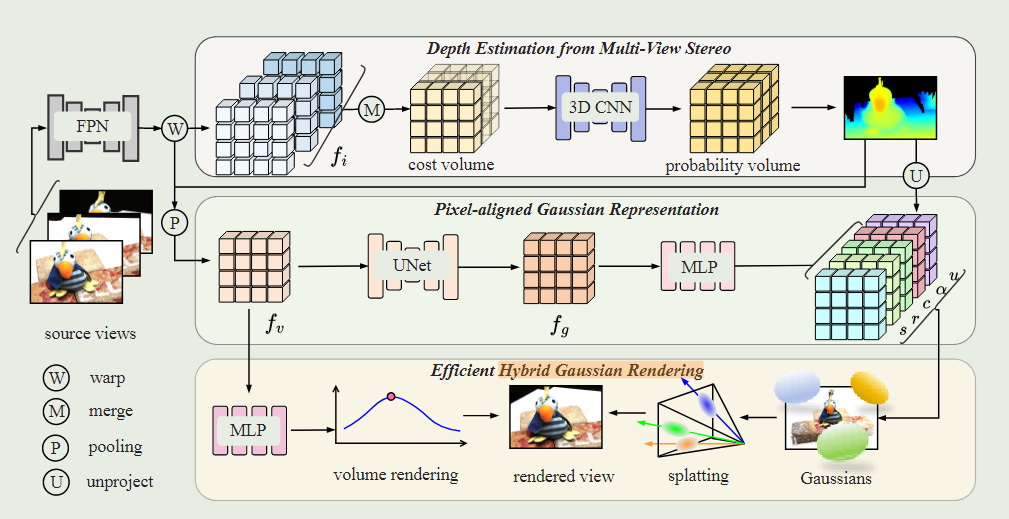
整体架构图
2、Introduction
由于3D-GS在每个场景优化最少都需要花费几分钟的时间,这极大限制3D-GS的应用。为解决这个问题,作者提出一种可泛化到未知场景的3D-GS重建模型。对于新视图的合成是需要真实的深度图。首先,与使用隐式表示的nerfs不同,3D-GS是一种参数化的显式表示,使用数百万个点云3D高斯来过拟合场景,而对于预训练后的3D-GS用到新的场景时,其位置和颜色等参数是明显不同的。与此同时,高斯和像素之间的颜色相关性是一种更复杂的多对多映射,这对模型的泛化提出了挑战。
3、Method
3.1、Depth Estimation from MVS
深度图是我们网络架构的关键组成部分,因为它连接了2d图像和3d场景表示。先在目标视图上确立多个深度假设平面,再利用单应性变换将源视图上的特征投影到目标视图,建立映射关系,便于求取视差。具体公式如下:
3.2、Pixel-aligned Gaussian Representation(用RGB代替SH函数)
利用MVSNet框架得到估计的深度图,然后做反投影获取3D点云,这时得到的是初始点云的位置信息(x,y,z)。本文对其进行特征编码,以建立一个像素对齐的高斯输入。第一步就是先通过上述的单应性变换将源视图与目标视图建立映射关系,再通过池化网络Pooling,将多视图的特征和深度图聚合为特征。但是,聚合后的特征仅仅包含单个像素的多视图信息,缺少空间信息。因此,利用2D-UNet网络对特征
进行空间信息增强,得到特征
。MLP进行解码,得到用于Gaussian渲染的参数
,分别是3D点云位置信息、高斯椭圆体缩放矩阵、高斯椭圆体旋转矩阵、不透明度、RGB颜色信息。深度图反投影的具体计算方式如下:
x代表像素信息,d代表估计深度值,即(x、y、z)。
MLP的解码具体方式和使用的激活函数如下所示:
本研究直接将特征的颜色回归为:
即用MLP解码了颜色特征,代替3D-GS通过SH函数获取颜色特征。
3.3、混合高斯渲染
研究是在3D-GS和像素之间使用简单的一对一相关性来预测精细的颜色。在这种情况下,splatting退化为具有单个像素深度感知采样点的体渲染。导致获得的视图缺乏精细的细节,使得该方法的泛化性能有限。 所以解码特征,获得了体积密度和radiance变量,通过体积渲染和高斯渲染两种方式平均求得,提高视图重建的精细。
3.4、逐场景优化的一致聚合
由于MVS方法固有的局限性,可泛化的模型预测的深度可能不完全准确,导致得到的高斯点云中存在噪声。直接使用这些点云信息是包含大量噪音的,这不仅会影响重建质量还会降低效率。最简单粗暴的方式就是对点云做downsample操作,但这种方式在降低噪音的同时也会剔除有效的点云信息。为此,我们引入了一种基于多视图几何一致性的聚合策略。同一个3d点在不同视点上的预测深度应该具有一致性。否则,预测的深度被认为是不可靠的。这种几何一致性可以通过计算不同视图之间的重投影误差来衡量。具体验证如下图所示:
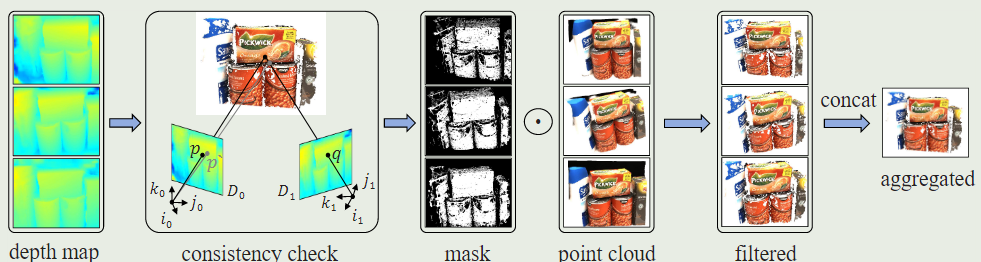
一致性聚合
给定参考视图的深度图,以及附近视图的深度图
,我们将深度图
中的像素
通过投影得到附近视图的像素点
,具体计算公式如下:
式中:表示
到
的投影变换,
为投影得到的深度。这时,我们再将像素点
估计的深度
反向投影到参考视图,得到重投影
,计算公式如下:
表示
到
的投影变换,
重投影的深度。重投影的误差计算如下所示:
参考图像将与每个剩余图像进行两两比较,以计算重投影误差。我们采用动态一致性检查算法来选择有效的深度值,主要思想是,当估计深度在少数视图中具有非常低的重投影误差或在大多数视图中具有相对低的误差时,估计深度是可靠的。可表述如下:
和
代表阈值,其值随着视图数量增加而增加。
4、损失函数
训练损失函数主要有均方根误差、SSIM Loss、感知损失函数,具体表述如下:
代表
阶段的损失函数值,
和
为损失权重值,
为整体损失值。
在逐场景优化时使用的损失函数为3D-GS损失函数,具体表述如下:
为损失权重。
注:、
、
、
、
5、结论
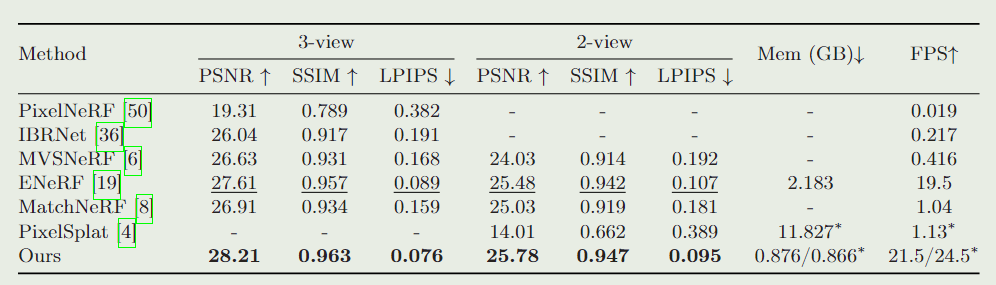
DTU数据集
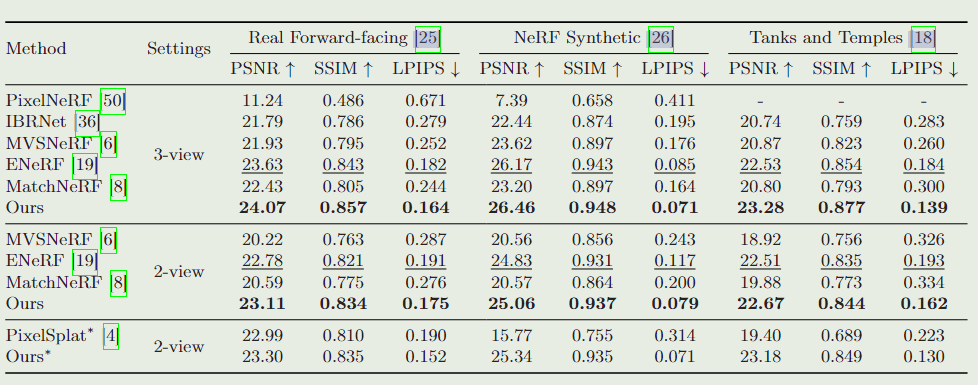
大场景重建对比















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









