







code:https://city-super.github.io/scaffold-gs/
article:https://arxiv.org/pdf/2312.00109
个人理解(仅是个人观点,理解的更透彻读者可以评论区留言讨论):
SFM的初始点云体素化—>体素网格—>网格中心点为锚点—>锚点高斯神经化—>编码锚点的观察方向和距离并权重化—>神经高斯特征做切片和重复处理—>将观察方向和距离以及神经高斯建立特征库—>用MLP解码预测神经高斯属性(即不透明度、颜色、旋转、比例)—>为了减少内存以及更细致的场景重建对锚点做的修剪和生成。
1、Abstract
3D-GS通常会导致大量冗余的高斯,试图拟合每个训练视图,而忽略了底层场景几何。因此,所得到的模型在显著的视图变化、无纹理区域和照明效果方面变得不那么鲁棒的。本研究使用Anchor points对三维高斯函数实现分布布局,并根据视图截锥内的观察方向和距离实时预测它们的属性,设计了Anchor points的增加和修剪策略。同时保证了渲染速度不会牺牲。
2、Introduction
3D场景的照片真实感和实时渲染一直是学术研究和工业领域的关键兴趣,利用GPU的光栅化渲染速度是非常快的,然而,它们(基于网格和点云)通常会产生低质量的渲染,表现出不连续和模糊的伪影。体积表示和神经辐射场利用基于学习的参数模型 ,因此可以生成具有更多细节的连续渲染结果。3D-GS保留了体积表示中发现的固有连续性,同时通过将 3D高斯splatting到 2D 图像平面上来促进快速光栅化。但也存在一些缺点:
1、它往往为了能够适应每个训练视图而过度扩展高斯椭圆球体,产生冗余,并忽略了场景结构。特别是在复杂的大规模场景中。
2、此外,视图相关的效果 bakde into 成单独的高斯参数,很少有插值能力,使其更少的鲁棒的实质性的视图变化和照明效果。
针对以上的缺陷,本研究提出以下改进策略:
1、我们构建了一个基于SFM初始点云转稀疏体素网格的锚点稀疏网格。 这些锚点中的每一个都将与一组具有可学习偏移量的神经高斯联系在一起,并且其属性(即不透明度、颜色、旋转、比例)是基于锚点特征和观看位置动态预测。通过场景的具体结构来指导3d高斯的分布,使其可以局部适应不同的视角和距离。
2、通过多Anchor points的修剪和增加,实现对场景的全覆盖。
3、此外,我们的存储需求显着减少,因为我们只需要为每个场景存储锚点和MLP 预测器。
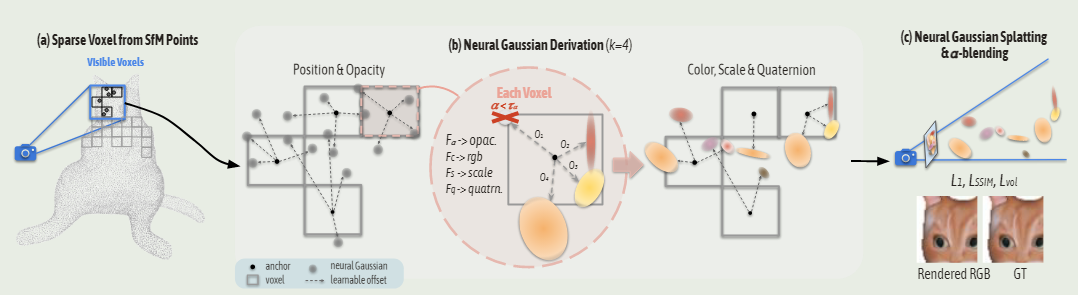
模型整体架构图
3、Method
3.1、3D-GS知识
利用SFM生成初始点云,每一个点云位置由3D高斯的均值来表示,表达式为:
其中表示3D场景中的任意位置,
是由缩放矩阵
和旋转矩阵
组成,具体表达式如下:
渲染用的是光栅化而非光线追踪方式。
3.2、Anchor Point Initialization(锚点初始化)
我们将初始的点云进行体素化,表达式如下:
其中表示体素中心,
是体素的尺寸,
表示删除点云中的不规则和冗余的信息。研究中将每一个体素的中心
作为anchor point,将其高斯神经化,使其包含局部上下文信息的特征(local context feature)(这个变量是哪来的,比较迷惑,个人理解为神经高斯的特征,即图中的灰色点)
比例因子
可以学习的偏移量
用
来表示anchor point。对于每一个
,我们创建一个特征库
,其中
表示
被做 slicing and repeating(切片和重复)
;将特征库与所有视图的权重结合,集成一个anchor feature
具体化来解释就是给定一个相机在位置
和一个 anchor在位置
,我们通过以下公式计算两者的相对距离和观察方向:
所有视图的权重是通过一个小型的MLP()计算得来,锚点的初始化具体表达式如下所示:
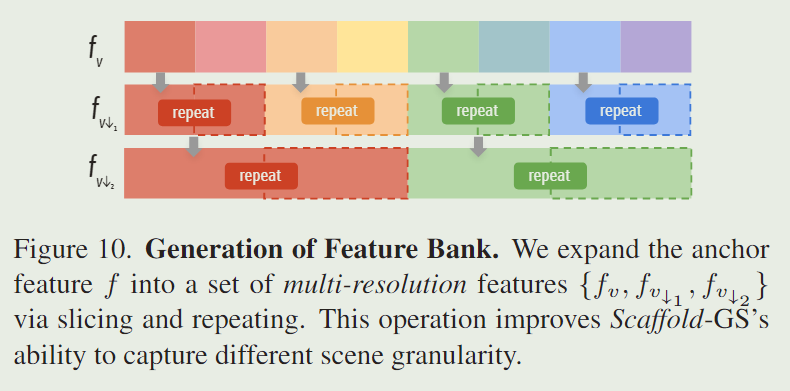
特征做切片和重复
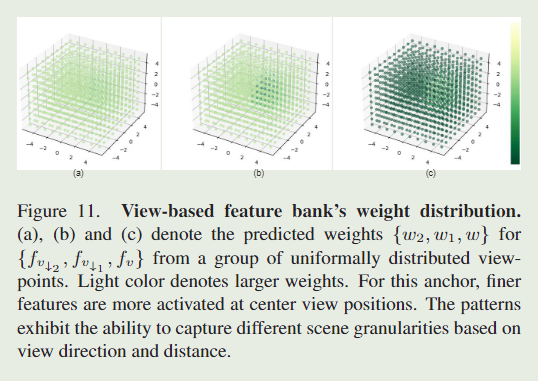
特征库的构建
颜色越浅说明权重越大,那么对于此处锚点位置可以表达更加精细的特征(权重是由此处锚点对应视锥的观察视角和距离求取,权重大则视锥内的观察角度以及距离越匹配),因此可以捕获场景内更加精细的特征。通过这个设计实现作者所说的基于观察视角和距离实现对场景结构化的指导,实现对其属性(即不透明度、颜色、旋转、比例)的动态预测。具体为什么要对神经高斯特征做切片和重复,作者解释是通过实验发现这样可以更好的实现对场景细粒度的捕捉。
3.3、Neural Gaussian Derivation
注:表示特定的MLP,除非另有说明。
我们利用锚点的位置不透明度
,协方差四元参数矩阵
,缩放矩阵
,颜色
,神经化(利用MLP编码)一个高斯函数。对于视锥内的每一个anchor point,生成K=4个神经高斯来预测anchor point的属性。具体来说,已知anchor point的位置
,其神经高斯的计算如下所示:
表示可学习偏移量,
为对应锚点对应的比例因子。
、
、
通用单独的MLPs解码为
,即获得。比如不透明度的解码如下所示:
神经高斯的属性预测是即时的(on-the-fly),这意味着只有视锥内可见的锚点可以生成神经高斯。为了渲染时的光栅化更有效,我们只保留不透明度值大于预定义阈值的神经高斯。这大大减少了计算负载,并帮助我们的方法保持与原始 3d-gs 相当的高渲染速度。

MLP解码器神经高斯的属性
注意这里输入MLP做解码的是特征库,利用MLP对其解码预测出锚点的神经高斯属性(不透明度、颜色、缩放尺寸、四元参数)。所以这个里面同样也是包含了前面提到的观察位置和距离信息的。
3.4、Anchor Points Refinement(锚点优化)
作者根据神经高斯的梯度来设计了一种锚点增长策略。通过构造大小为的体素来在空间上量化神经高斯,对于每一个体素,计算神经高斯在训练迭代N次后的平均梯度信息,记作
。当
时,体素是被认为显著的,其中
为预定义的阈值。因此,如果没有建立锚点,则在体素的中心部署一个新的锚点。我们将空间量化为多分辨率体素网格,使得可以添加新的锚点,具体表达式如下:
其中 m 表示量化级别。为了进一步调节新锚点的添加,我们对这些候选锚点应用了随机消除。这种添加点的谨慎方法有效地抑制了锚点的快速扩展。
4、Loss
损失函数如下所示:
渲染的像素颜色,
为体积正则化损失函数,具体如下:
其中场景中神经高斯的数量,
为每个神经高斯的尺度,
作向量值的乘积。
5、结论

定量结果对比

与基础3D-GS结果对比















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









