






点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
YOLO-S.pdf,链接:
https://pan.baidu.com/s/1yoamhld79Glc4wE_SUT1DA
提取码:6d8S
计算机视觉研究院专栏
Column of Computer Vision Institute
研究者提出了YOLO-S,一个简单、快速、高效的网络。它利用了一个小的特征提取器,以及通过旁路和级联的跳过连接,以及一个重塑直通层来促进跨网络的特征重用,并将低级位置信息与更有意义的高级信息相结合。

01
简介
小目标检测仍然是一项具有挑战性的任务,尤其是在为移动或边缘应用寻找快速准确的解决方案时。在下次分享中,有研究者提出了YOLO-S,一个简单、快速、高效的网络。它利用了一个小的特征提取器,以及通过旁路和级联的跳过连接,以及一个重塑直通层来促进跨网络的特征重用,并将低级位置信息与更有意义的高级信息相结合。


02
背景介绍
航空图像中的小目标检测已经成为当今研究的热点。事实上,最近出现的无人机等数据赋能技术为广泛的客户群提供了一种具有成本效益的解决方案,根据相机轴、飞行器高度和使用的胶片类型,满足了广泛且几乎无限的用户需求。
此外,来自卫星或无人机传感器的公开可用车辆数据的日益可用性推动了该领域的研究。然而,图像中车辆的低分辨率、微小目标的较差特征、车辆类型、尺寸和颜色的可变性,以及杂乱背景或干扰大气因素的存在,仍然对卷积神经网络的车辆检测率提出了挑战。

此外,集装箱、建筑物或路标等令人困惑的物体的出现可能会增加误报的可能性。此外,在准确性和延迟时间之间进行合理的权衡是必要的。主流的目标检测器需要大量内存,通常只能在集中式高性能平台中执行。特别地,two-stage检测器不适合实时检测,而单级检测器仅在强大的资源上提供实时性能。它们中没有一个是为小目标检测而充分定制的。此外,由于数据处理成本更低、速度更快、与远程服务器的数据交换不可靠或存在安全和隐私问题,许多工业应用程序要求在靠近数据源的边缘设备上本地部署CNNs,然而这种设备的特征通常是在性能、成本等方面硬件资源有限,并且不包括GPU。因此,快速和轻量级的CNNs是强制性的,同时即使在小目标上也能保持令人满意的准确性。Tiny-YOLOv3不能保证足够的性能,因为其主干提取的特征很差,并且其输出尺度很粗糙。
其他研究工作则以准确性换取速度。在[Research on Airplane and Ship Detection of Aerial Remote Sensing Images Based on Convolutional Neural Network]中,第四个输出尺寸104×104被添加到YOLOv3中,以减少感受野,在DOTA(航空图像中对象设计的数据集)的基础上获得了3%的mAP改进,尽管推理较慢。由于YOLOv3主要检测规模为52×52的小目标。[.In Proceedings of the International Conference on AI and Big Data Application]提出了基于两个输出52×52和104×104的YOLO-E,并实现了一个双向残差子模块,以减少网络深度。它们还通过用GIoU取代并集交集(IoU)度量,并在YOLOv3损失函数中添加新的项1-GIoU,提高了对目标位置的敏感性。在VEDAI上,它获得了91.2%的mAP,几乎比YOLOv3准确五分之一,慢6.7%。在[Robust Vehicle Detection in Aerial Images Based on Cascaded Convolutional Neural Networks]中,提出了一种基于VGG16架构的级联检测器,其在VEDAI和Munich数据集上的性能优于Faster R-CNN,但推理速度要慢20-30%。此外,低分辨率航空图像由于其外观模糊性和与背景的相似性,使从车辆中提取有意义的特征变得更加困难。在[Joint-SRVDNet: Joint Super Resolution and Vehicle Detection Network]中,证明了两个超分辨率和检测网络的联合学习可以在超分辨率图像中实现更有意义的目标和更高的感知质量,这又导致检测任务的精度提高,并且在低分辨率航空图像上的性能接近于用相应的高分辨率图像馈送的现有技术方法。为了解决这个问题,其提出了一种联合超分辨率和车辆检测网络(Joint SRVDNet),该网络利用了两个相互关联的超分辨率和检测任务的互补信息。联合SRVDNet由两个主要模块组成:用于4×上采样因子的图像超分辨率的多尺度MsGAN和用于车辆检测的YOLOv3。具体而言,作者证明了两个网络的联合学习允许在超分辨率图像中获得更有意义的目标和更高的感知质量,这反过来又提高了探测任务的准确性,并提高了低分辨率航空图像的性能,接近于用相应的高分辨率航空图像提供的现有最先进的方法。

03
新框架详细分析
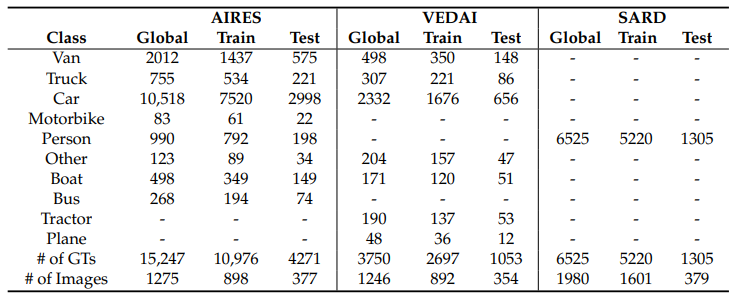
研究者介绍了AIRES(cAr detectIon fRom-hElicopter imagesS),这是一个新的车辆数据库,由1920×1080分辨率的航空全高清(FHD)图像组成,由WESCAM MX-15 EO/IR成像系统传输,该系统放置在多传感器四轴陀螺稳定炮塔系统中,安装在载人警用直升机AW169的前端。直升机在近300米至1000米的不同高度飞行,不同的摄像机角度从约5°至80°不等。这些图像是2019年6月至9月在两个不同的地理区域拍摄的:意大利北部的伦巴第大区和挪威的奥斯陆市。该数据集由1275张用LabelImg软件[36]注释的图像组成,包含15247个注释的地面实况(GT)对象,分为八类:面包车、卡车、汽车、摩托车、人、其他、船和公共汽车。统计数据汇总在表1中:大多数类别是汽车,而人口较少的类别是摩托车,占0.5%,其他类别占0.8%,后者包括推土机和建筑工地使用的其他地面移动车辆。
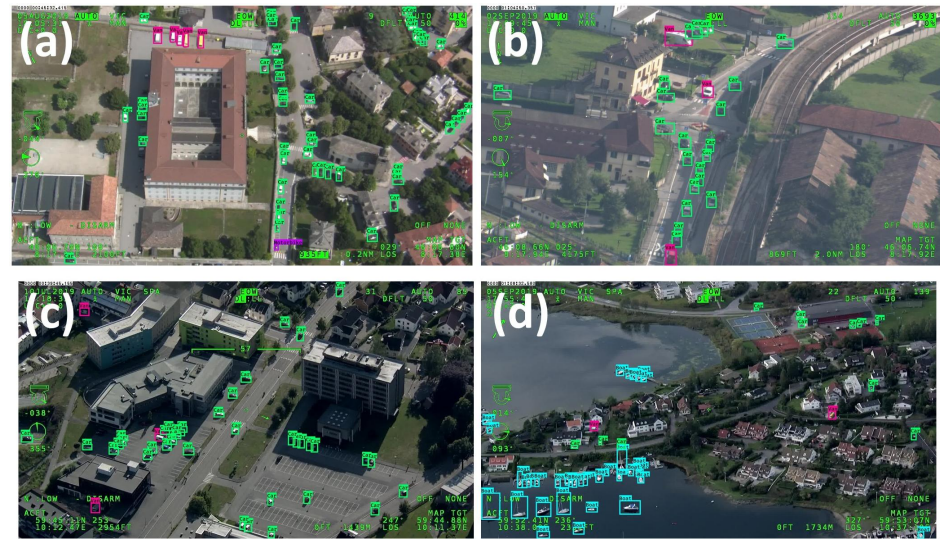
Some images of the AIRES dataset
在这项工作中,提出了两种新的类YOLO架构:YOLO-L和YOLO-S,其架构如下图所示。
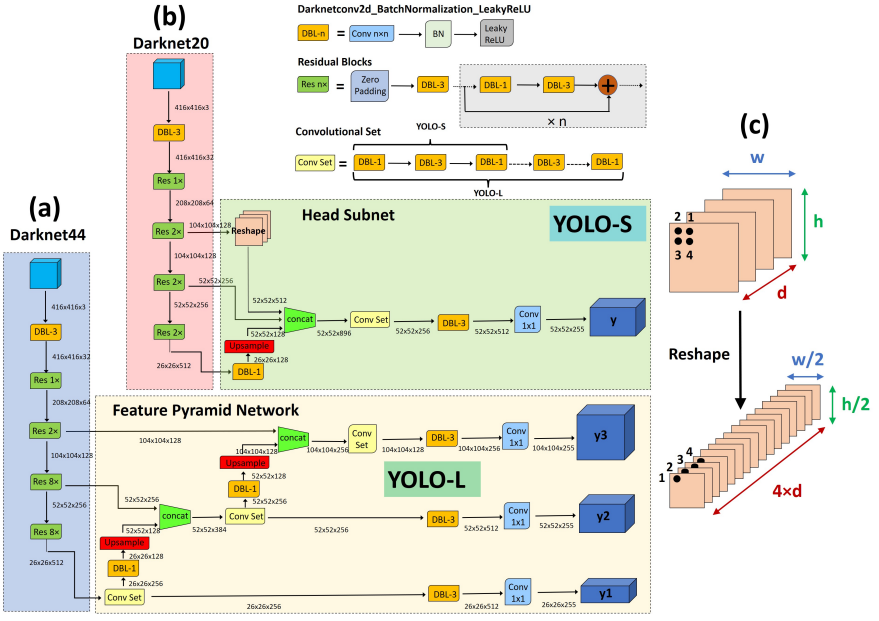
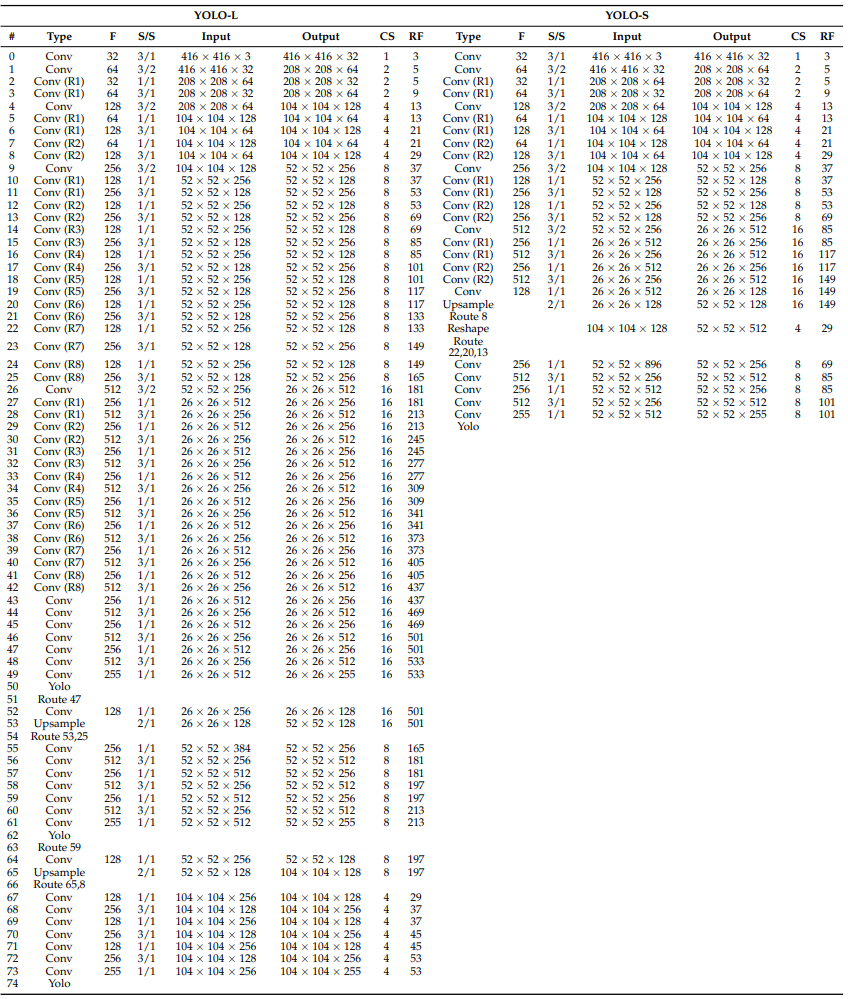
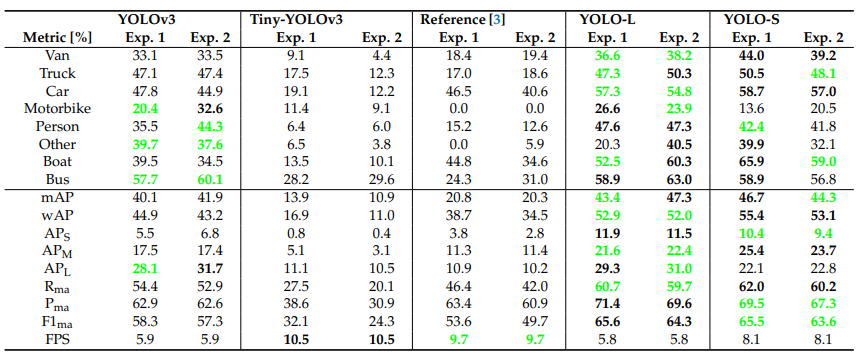
关于所提出的CNN的全部细节见下表,其中还报告了每层的感受野和累积步幅。假设输入图像的大小调整为默认大小416×416。YOLO-L由于推理速度有限,仅适用于高功率硬件上的离线处理,因此主要用于基准测试。YOLO-S,或YOLO-small,是为在边缘设备上部署高效、轻量级和精确的网络而提出的。
下表提供了进一步的细节,其中将所提出的网络与其他最先进的检测器在参数数量、体积、BFLOP和架构特性方面进行了比较。
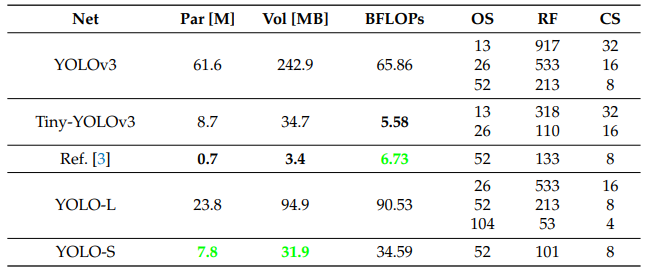
我们以YOLO-S为例,如上图b所示,是一个微小而快速的网络,它利用图c所示的特征融合和重塑穿透层的概念,将早期细粒度特征图的精确位置信息与分辨率较低的深层特征图的有意义语义信息相结合。基本上,它基于Darknet20主干,在特征提取阶段用交错卷积层和残差单元取代Tiny-YOLOv3的最大池化层,以减少下采样期间的信息损失,并有效地增加感受野。由七个残差块组成的轻量级主干还可以避免对小规模检测到的目标进行无用的卷积操作,否则在更深的架构中,这可能会导致在多次下采样后只剩下几个像素的最终特征此外,YOLO-S采用了一个具有单个输出规模52×52的head subnet和一个仅由4个交替卷积层1×1和3×3组成的较小卷积集,而不是YOLO-L和YOLOv3中的6个,以加快推理。这导致输出的感受野大到101×101,一旦源图像被重新缩放到网络预期的大小,就足以获得目标周围有意义的上下文信息。
最后,通过横向连接主干的第八层、第十三层和第十九层,分别对应于4×、8×和16×下采样的特征图,实现了跳跃连接,以提取更稳健的定位特征。由于这种特征图表现出不同的分辨率,因此将上采样应用于第十九层,并将整形应用于第八层,以在级联之前将每个尺寸与形状52×52相匹配。
总体而言,YOLO-S的模型体积比YOLOv3缩小了87%(YOLO-S尺寸仅为YOLOv3的7.9%),并且包含了近7.853M的可训练参数,因此甚至比Tiny-YOLOv3轻10%。此外,它需要34.59个BFLOP,接近SlimYOLOv3-SPP3-50,几乎是YOLOv3的一半,如上表所示。然而,在实验中,所提出的模型YOLO-S在准确性方面优于YOLOv3。

04
实验及可视化
首先,通过对每个类别进行分层抽样,在训练(70%)和测试(30%)中对数据集进行随机分割。然后,为了丰富模型学习过程中可用的统计信息,启用了标准的数据增强技术,包括水平翻转、调整大小、裁剪和亮度、对比度、饱和度和色调的随机失真。然而,由于缺乏数据而导致的过度拟合问题往往无法通过数据扩充方法得到有效解决,尤其是对于少数类。
因此,采用了所谓的“迁移学习”技术,以便利用可在公开数据库上获得的知识。这对准确性尤其有利:提取初步特征的基础任务与感兴趣的目标任务越相似,可达到的准确性就越高。具体如下图:
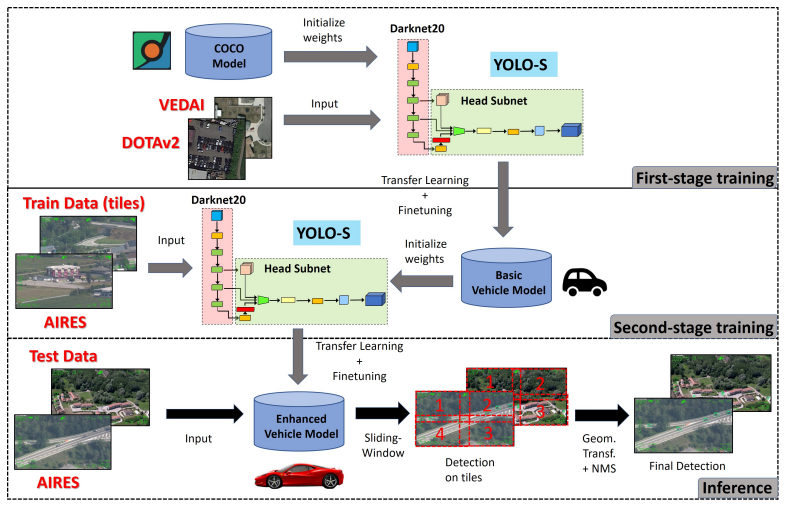
Comparative results of experiments 1 and 2 on AIRES dataset

(a) YOLOv3; (b) Tiny-YOLOv3; (c) [ A Simple and Efficient Network for Small Target Detection], (d) YOLO-L; (e) YOLO-S
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
🔗
Sparse R-CNN:稀疏框架,端到端的目标检测(附源码)















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











