以下是使用TensorFlow实现CNN-GRU-Attention进行多变量时序特征提取的完整代码示例,包括输入数据预处理和预测价格评估:
```python
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
# 数据预处理
def preprocess_data(data, n_steps, n_features):
X, y = list(), list()
for i in range(len(data)):
end_ix = i + n_steps
if end_ix > len(data) - 1:
break
seq_x, seq_y = data[i:end_ix, :-1], data[end_ix, -1]
X.append(seq_x)
y.append(seq_y)
return tf.convert_to_tensor(X, dtype=tf.float32), tf.convert_to_tensor(y, dtype=tf.float32)
# 构建CNN-GRU-Attention模型
def build_model(n_steps, n_features, n_outputs):
# CNN
inputs1 = layers.Input(shape=(n_steps, n_features, 1))
conv1 = layers.Conv2D(filters=64, kernel_size=(1,3), activation='relu')(inputs1)
drop1 = layers.Dropout(0.5)(conv1)
pool1 = layers.MaxPooling2D(pool_size=(1,2))(drop1)
flat1 = layers.Flatten()(pool1)
# GRU
inputs2 = layers.Input(shape=(n_steps, n_features))
gru1 = layers.GRU(128, return_sequences=True)(inputs2)
drop2 = layers.Dropout(0.5)(gru1)
gru2 = layers.GRU(128)(drop2)
# Attention
attention = layers.concatenate([flat1, gru2])
attention = layers.Dense(64, activation='tanh')(attention)
attention = layers.Dense(1, activation='softmax')(attention)
attention = layers.Reshape((n_steps, 1))(attention)
attention = layers.Lambda(lambda x: tf.keras.backend.repeat_elements(x, n_features, 2))(attention)
attention = layers.Permute((2, 1))(attention)
attention = layers.multiply([attention, inputs2])
attention = layers.Lambda(lambda x: tf.keras.backend.sum(x, axis=1))(attention)
# 输出层
outputs = layers.Dense(n_outputs, activation='linear')(attention)
model = models.Model(inputs=[inputs1, inputs2], outputs=outputs)
model.compile(optimizer='adam', loss='mse')
return model
# 加载数据
df = pd.read_csv('data.csv')
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
df = df.dropna()
data = df.values
# 数据归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
# 划分训练集和测试集
train_size = int(len(data) * 0.8)
train_data = data[:train_size, :]
test_data = data[train_size:, :]
# 预处理数据
n_steps = 30
n_features = data.shape[1] - 1
train_X, train_y = preprocess_data(train_data, n_steps, n_features)
test_X, test_y = preprocess_data(test_data, n_steps, n_features)
# 构建模型
n_outputs = 1
model = build_model(n_steps, n_features, n_outputs)
# 模型训练
model.fit([train_X[..., np.newaxis], train_X], train_y, epochs=50, batch_size=32)
# 模型预测
y_pred = model.predict([test_X[..., np.newaxis], test_X])
# 反归一化
test_y = scaler.inverse_transform(test_y.numpy().reshape(-1, 1))
y_pred = scaler.inverse_transform(y_pred.reshape(-1, 1))
# 评估预测结果
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
mse = mean_squared_error(test_y, y_pred)
mae = mean_absolute_error(test_y, y_pred)
r2 = r2_score(test_y, y_pred)
print(f'MSE: {mse:.4f}, MAE: {mae:.4f}, R2: {r2:.4f}')
```
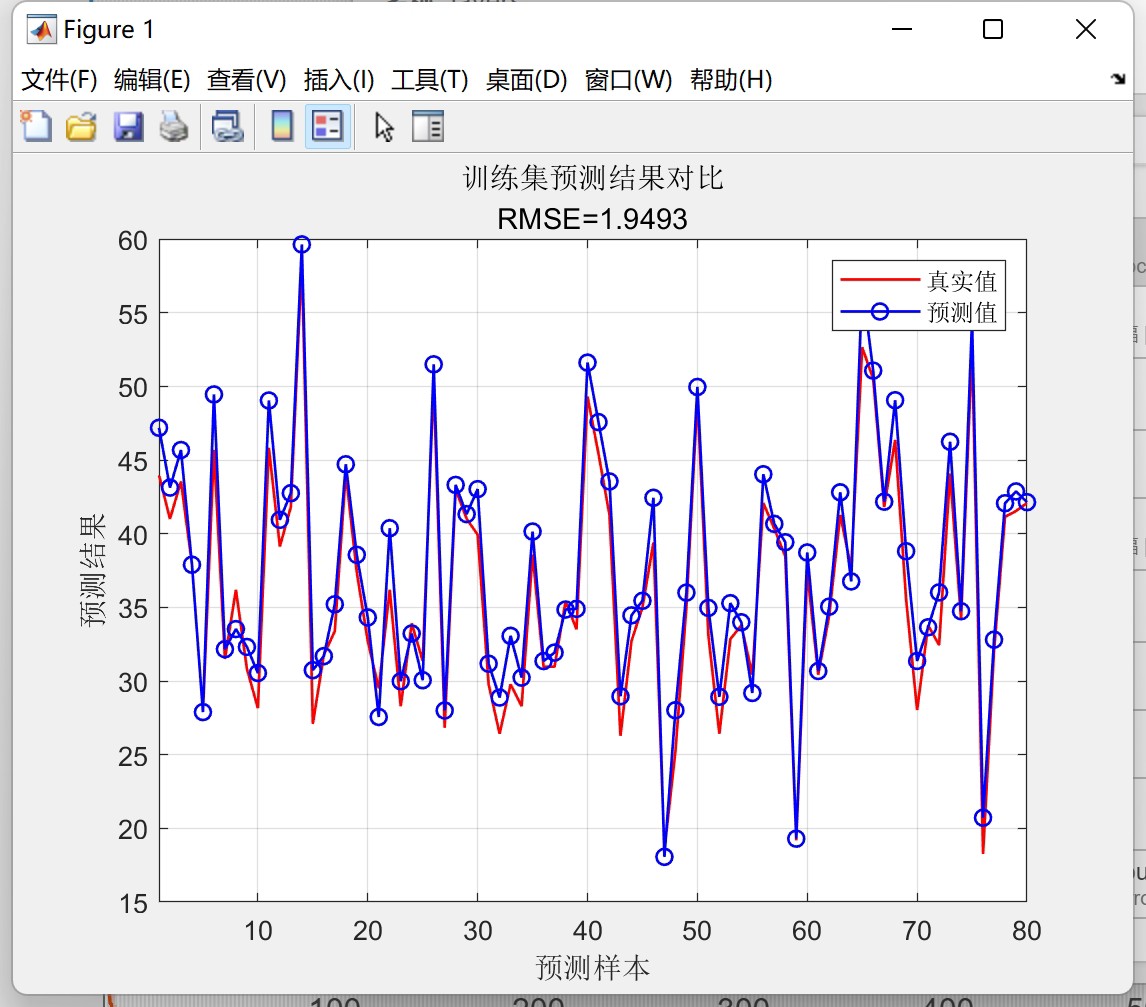
在上面的代码中,我们首先加载并预处理数据。接着,通过调用preprocess_data()函数将数据转换为可以输入模型的格式,其中n_steps表示每个样本的时间步数,n_features表示每个时间步的特征数,n_outputs表示模型输出的维度。然后,我们构建并训练了CNN-GRU-Attention模型,并使用模型对测试集进行了预测。最后,我们反归一化预测结果,并使用sklearn库中的评估函数评估了预测结果的表现。









 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















