







引言
Apriori算法是一种常用的关联规则算法,也是最经典的挖掘频繁项集的算法,其核心是通过连接产生候选项以其支持度然后通过剪枝生成频繁项集。之外还有FP-Tree、Eclat、灰色关联法等其他算法。
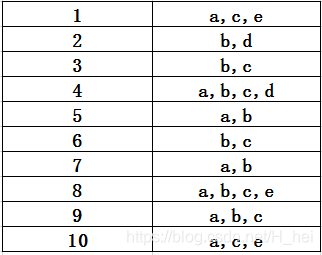
在这里通过具体的例子详细的介绍下Apriori算法原理,以下面数据为例:第一列表示数据的条目、第二列为每个条目里面的数据,我们可以把下表作为超市商品订单号和订单内容。我们主要是通过算法去挖掘频繁项集也就是隐藏在订单中的信息,另外我们把每一条数据称为事务。
基本概念
-
项:基本数据单元(e.g. 以上数据中的 a、b、c、d、e …).
-
项集:项集是项的集合。(e.g. A {a,b} 、B {c}、 … 含有k项被称为k项集,A为2项集).
-
支持度:项集A、B同时发生的概率(也称为相对支持度).
S u p p o r t ( A ⇒ B ) = P ( A ⋃ B ) = A 、 B 同 时 发 生 的 事 务 个 数 所 有 事 务 个 数 Support(A\Rightarrow B)=P(A\bigcup B)=\frac{A、B同时发生的事务个数}{所有事务个数} Support(A⇒B)=P(A⋃B)=所有事务个数A、B同时发生的事务个数
e.g. 若A {a,b} 、B {c},则在10个事务中有3个事务包含 a,b,c 即 P ( A ⋃ B ) = P ( { a , b , c } ) = 3 10 = 0.3 P(A\bigcup B)=P(\{a,b,c\})=\frac{3}{10}=0.3 P(A⋃B)=P({a,b,c})=103=0.3. -
置信度:项集A发生,则项集B发生的概率.
C o n f i d e n c e ( A ⇒ B ) = P ( B ∣ A ) = S u p p o r t ( A ⇒ B ) S u p p o r t ( A ) = A 、 B 同 时 发 生 的 事 务 个 数 A 发 生 的 事 务 个 数 Confidence(A\Rightarrow B)=P(B|A)=\frac{Support(A\Rightarrow B)}{Support(A)}=\frac{A、B同时发生的事务个数}{A发生的事务个数} Confidence(A⇒B)=P(B∣A)=Support(A)Support(A⇒B)=A发生的事务个数A、B同时发生的事务个数
e.g. 若A {a,b} 、B {c},则 S u p p o r t ( A ⇒ B ) = 0.3 , S u p p o r t ( A ) = 0.5 , P ( B ∣ A ) = 0.6 Support(A\Rightarrow B)=0.3,Support(A)=0.5, P(B|A)=0.6 Support(A⇒B)=0.3,Support(A)=0.5,P(B∣A)=0.6 . -
最小支持度和最小置信度:它们都是由专家定义的一个阈值,表示项目集在统计意义上的重要性和可靠性。同时满足最小支持阈值和最小置信阈值的规则称为强规则。
-
频繁项集:如果项集 I I I的相对支持度满足预定义的最小支持度阈值,则 I I I是频繁项集。(性质:频繁项集的所有非空子集也必须是频繁项集)
Apriori算法
Apriori算法两个基本过程
- 连接步: 连接步目的是找到K项集。对给定的最小支持阈值,分别对1项候选集 C 1 C_1 C1,剔除小于该阈值的项集得到1项频繁集 L 1 L_1 L1;下一步由 L 1 L_1 L1与自身连接产生2项候选集 C 2 C_2 C2,保留 C 2 C_2 C2中满足约束条件的项集得到2项频繁集,记为 L 2 L_2 L2;下一步由 L 2 L_2 L2与 L 1 L_1 L1连接得到3项候选集 C 3 C_3 C3,保留 C 3 C_3 C3中满足约束条件的项集得到3项频繁集,记为 L 3 L_3 L3;…这样循环下去,得到最大项集。(两个集合求笛卡尔积).
- 剪枝步: 根据频繁项集的性质,在产生频繁项集 C k C_k Ck的过程中起到减小搜索空间的目的。主要是生成候选集后先根据性质剔除一部分,之后再扫描所有事务,减小搜索空间,提高算法效率。
算法过程
上图表格为数据,最小支持度:0.2 则有以下:

- 算法简单扫描所有的事务,事务中的每一项都是候选1项集的集合 C 1 C_1 C1的成员,计算每一项的支持度。e.g. P ( { a } ) = 项 集 { a } 的 事 务 计 数 所 有 事 务 个 数 = 7 10 = 0.7 P(\{a\})=\frac{项集\{a\}的事务计数}{所有事务个数}=\frac{7}{10}=0.7 P({a})=所有事务个数项集{a}的事务计数=107=0.7。
- 对 C 1 C_1 C1中的各项集的支持度与预先设定的最小支持度阈值进行比较,保留大于或等于该阈值的项,得到1项频繁集 L 1 L_1 L1。
- L 1 L_1 L1与 L 1 L_1 L1连接得到候选2项集 C 2 C_2 C2,扫描所有事务,计算每一项的支持度。e.g. P ( { a , b } ) = 项 集 { a , b } 的 事 务 计 数 所 有 事 务 个 数 = 5 10 = 0.5 P(\{a,b\})=\frac{项集\{a,b\}的事务计数}{所有事务个数}=\frac{5}{10}=0.5 P({a,b})=所有事务个数项集{a,b}的事务计数=105=0.5。由于 L 1 L_1 L1中都为频繁项集,没有从项集中剔除。
- 对 C 2 C_2 C2中的各项集的支持度与预先设定的最小支持度阈值进行比较,保留大于或等于该阈值的项,得到2项频繁集 L 2 L_2 L2。
- L 2 L_2 L2与 L 1 L_1 L1连接得到候选2项集 C 3 C_3 C3,扫描所有事务,计算每一项的支持度。e.g. P ( { a , b , c } ) = 项 集 { a , b , c } 的 事 务 计 数 所 有 事 务 个 数 = 3 10 = 0.3 P(\{a,b,c\})=\frac{项集\{a,b,c\}的事务计数}{所有事务个数}=\frac{3}{10}=0.3 P({a,b,c})=所有事务个数项集{a,b,c}的事务计数=103=0.3。剪枝: L 2 L_2 L2与 L 1 L_1 L1连接后会产生S { b , c , e } \{b,c,e\} {b,c,e}等子集,但是S子集 { b , e } \{b,e\} {b,e}不是频繁项集,故剔除。
- 对 C 3 C_3 C3中的各项集的支持度与预先设定的最小支持度阈值进行比较,保留大于或等于该阈值的项,得到3项频繁集 L 3 L_3 L3。
- L 3 L_3 L3与 L 1 L_1 L1连接后得候选4项集 C 4 C_4 C4,易得剪枝后为空集,最后得频繁项集 { a , b , c } \{a,b,c\} {a,b,c}, { a , c , e } \{a,c,e\} {a,c,e}。
结果

若以上为餐饮数据,以
a
→
b
a\rightarrow b
a→b为例,则支持度可以理解为同时餐品a,b同时点的概率,置信度为点a后再点b的概率。我们根据Apriori算法的到以上数据,就可以对这些内容,商品等进行智能推荐。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









