






 本文推荐了多个初学者入门视频生成领域的论文,包括VideoGAN、TGAN、RNN-GAN、MDGAN和MocoGAN系列,涵盖了从随机噪声生成连续视频帧到利用RNN进行运动预测的多种方法。这些工作展示了视频生成和预测领域的最新进展,为后续研究提供了基础。此外,还提及了相关课程和学习资源,帮助读者深入理解这一前沿技术。
本文推荐了多个初学者入门视频生成领域的论文,包括VideoGAN、TGAN、RNN-GAN、MDGAN和MocoGAN系列,涵盖了从随机噪声生成连续视频帧到利用RNN进行运动预测的多种方法。这些工作展示了视频生成和预测领域的最新进展,为后续研究提供了基础。此外,还提及了相关课程和学习资源,帮助读者深入理解这一前沿技术。
欢迎来到《每周CV论文推荐》。在这个专栏里,还是本着有三AI一贯的原则,专注于让大家能够系统性完成学习,所以我们推荐的文章也必定是同一主题的。
当前图像生成领域的发展已经非常成熟,与之相关的视频生成领域也一直被研究,不过这是一个更难的问题,还没有那么成熟,本次我们来给大家介绍初学基于GAN的视频生成领域值得阅读的论文。
作者&编辑 | 言有三
1 VideoGAN和TGAN
VideoGAN是DCGAN的视频版,从随机噪声中生成连续的视频帧,它是一个双流模型,是最早将GAN用于视频生成的框架。同期类似的还有TGAN,后者先从噪声向量中生成一组潜在向量,再分别生成图片并组合成视频。
文章引用量:1500+
推荐指数:✦✦✦✦✦
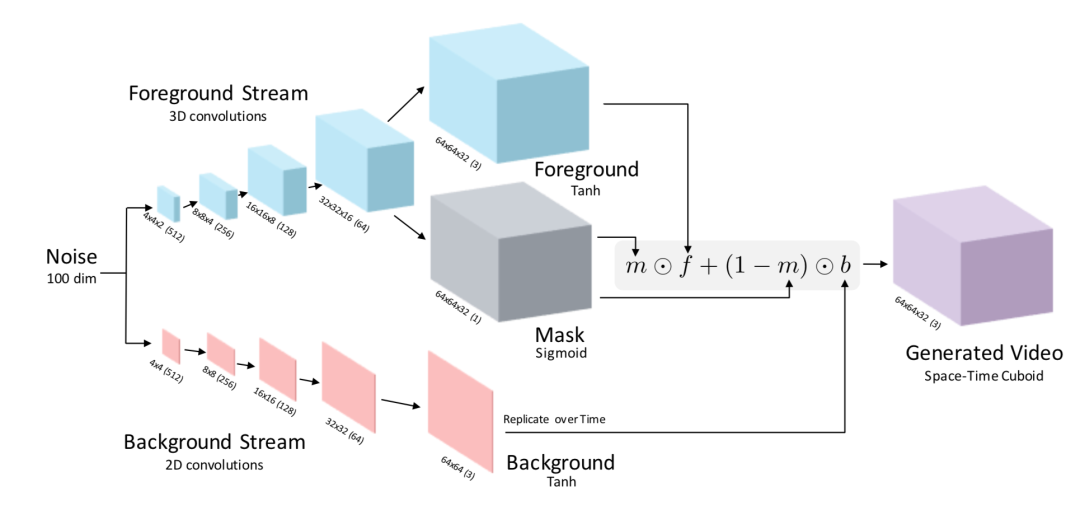
[1] Vondrick C, Pirsiavash H, Torralba A. Generating videos with scene dynamics[C]//Advances in neural information processing systems. 2016: 613-621.
[2] Saito M, Matsumoto E, Saito S. Temporal generative adversarial nets with singular value clipping[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2830-2839.
2 RNN-GAN
VideoGAN是一个从零生成视频的GAN框架,而RNN-GAN则基于RNN的时序建模能力,从一帧图像开始进行视频预测,相比于VideoGAN有更强大的运动预测能力。
文章引用量:100+
推荐指数:✦✦✦✦✦
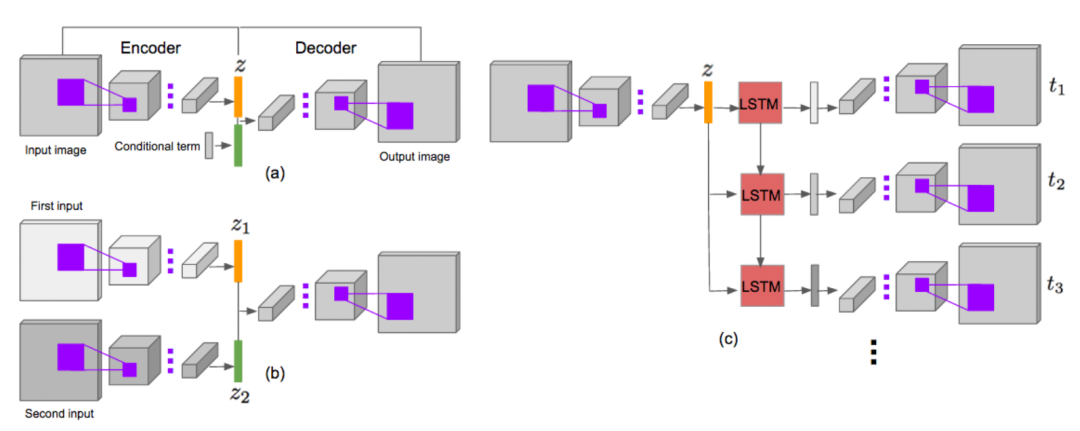
[3] Zhou Y, Berg T L. Learning temporal transformations from time-lapse videos[C]//European conference on computer vision. Springer, Cham, 2016: 262-277.
3 MDGAN
MDGAN是一个多阶段的视频预测框架,在第一阶段(Base-Net)生成每一帧的内容,它要注重每一帧内容的真实性。在第二阶段(Refine-Net)则重点优化帧与帧之间物体的运动,使得生成结果更加平滑,其结果比VideoGAN和RNN-GAN更优。
文章引用量:100+
推荐指数:✦✦✦✦✦
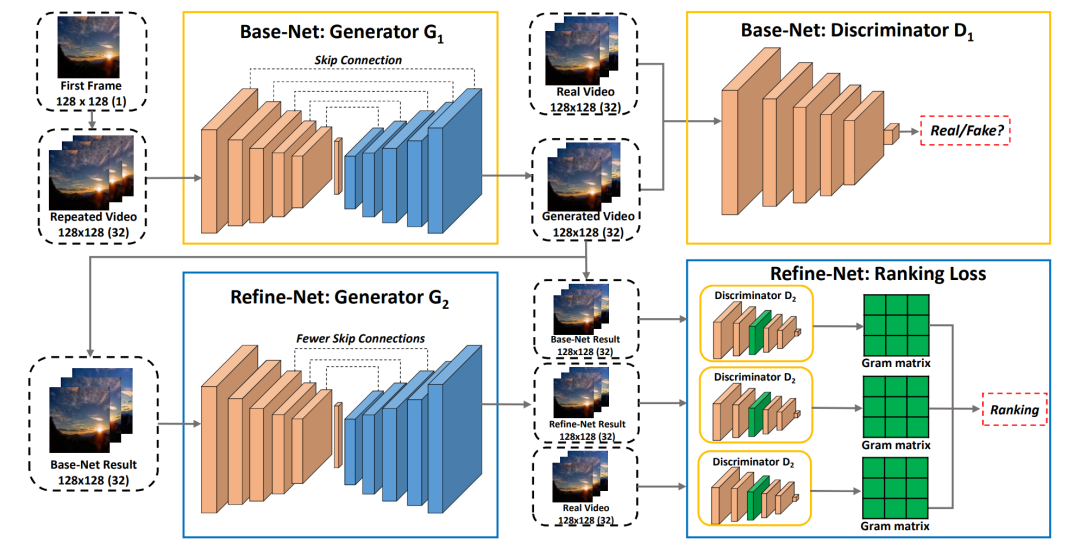
[4] Xiong W, Luo W, Ma L, et al. Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2364-2373.
4 MocoGAN系列
MocoGAN将视频生成分解成了内容生成和动作生成两部分,内容空间只建模与运动无关的内容变化,运动空间则只建模与内容无关的运动变化,从而在两个子空间中实现更自由的结果控制。比如一个微笑的人脸,可以使用内容空间建模身份信息,使用运动空间建模面部肌肉运动。
文章引用量:800+
推荐指数:✦✦✦✦✦
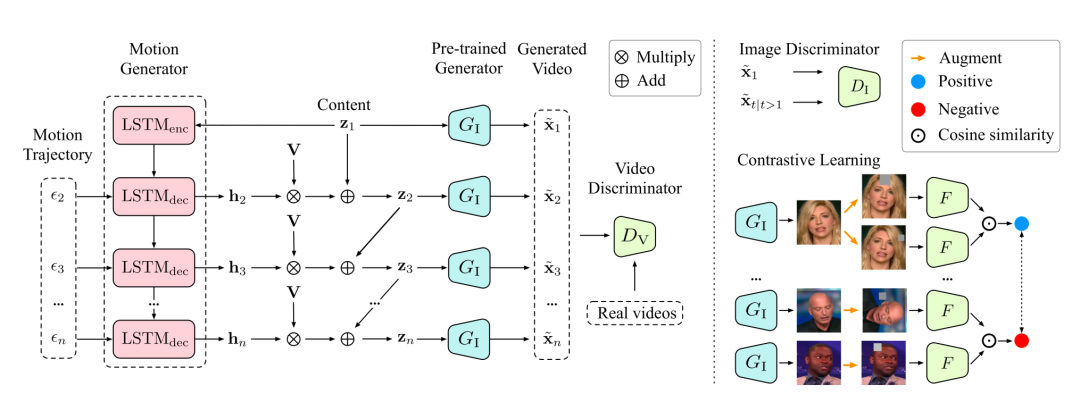
[5] Tulyakov S, Liu M Y, Yang X, et al. Mocogan: Decomposing motion and content for video generation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 1526-1535.
[6] Tian Y , Ren J , Chai M , et al. A Good Image Generator Is What You Need for High-Resolution Video Synthesis[J]. 2021.
5 如何进行实战
为了帮助大家掌握基于GAN的图像与视频生成理论与实战!我们推出了相关的专栏课程《深度学习之图像生成GAN:理论与实践》,感兴趣可以进一步阅读:
【视频课】CV必学,超6小时,2大模块,循序渐进地搞懂GAN图像生成!

总结
本次我们介绍了初学基于GAN的视频生成和预测必须掌握的一些方法,视频生成和预测是一个非常前沿的研究领域,还有较大的发展空间,也有非常好的落地场景,对该方向感兴趣的朋友可以通过阅读这些文章进行初步了解。
有三AI秋季划-GAN组

如果想要永久系统性地跟随我们社区学习GAN的相关内容,请关注有三AI-CV秋季划GAN组,阅读了解下文:
【CV秋季划】生成对抗网络GAN有哪些研究和应用,如何循序渐进地学习好(2022年言有三一对一辅导)?
转载文章请后台联系
侵权必究



往期相关精选


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











