







转自:http://blog.csdn.net/chshplp_liaoping/article/details/12752749
在移动平台上进行一些复杂算法的开发,一般需要用到指令集来进行加速。目前在移动上使用最多的是ARM芯片。
ARM是微处理器行业的一家知名企业,其芯片结构有:armv5、armv6、armv7和armv8系列。芯片类型有:arm7、arm9、arm11、cortex系列。指令集有:armv5、armv6和neon指令。关于ARM到知识参考:http://baike.baidu.com/view/11200.htm
最初的ARM指令集为通用计算型指令集,指令集都是针对单个数据进行计算,没有并行计算到功能。随着版本的更新,后面逐渐加入了一些复杂到指令以及并行计算到指令。而NEON指令是专门针对大规模到并行运算而设计的。
NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成),其性能至少为ARMv5 性能的3倍,为 ARMv6 SIMD性能的2倍。
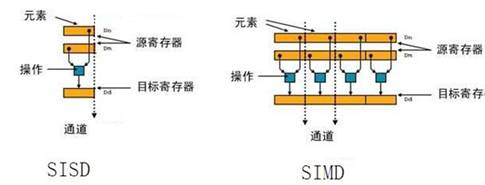
关于SIMD和SISD:Single Instruction Multiple Data,单指令多数据流。反之SISD是单指令单数据。以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。如下图所示:
如何才能快速到写出高效的指令代码?这就需要对各个指令比较熟悉,知道各个指令的使用规范和使用场合。
ARM指令有16个32位通用寄存器,为r0-r15,其中r13为堆栈指针寄存器,r15为指令计算寄存器。实际可以使用的寄存器只有14个。r0-r3一般作为函数参数使用,函数返回值放在r0中。若函数参数超过4个,超过到参数压入堆栈。
有效立即数的概念:每个立即数采用一个8位的常数(bit[7:0])循环右移偶数位而间接得到,其中循环右移的位数由一个4位二进制(bit[11:8] )的两倍表示。如果立即数记作<immediate> , 8位常数记作immed_8 , 4位的循环右移值记作rotate_imm ,有效的立即数是由一个8位的立即数循环右移偶数位得到,可以表示成:
<immediate>=immed_8循环右移( 2×rotate_imm)
如:mov r4 , #0x8000 000A #0x8000 000A 由0xA8循环右移0x2位得到。
下面介绍一些比较常用到一些指令。















 2825
2825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









