






 文章探讨了Feed流推荐中的上下文依赖问题,介绍了PIER框架,它通过FPSM和OCPM模块处理复杂度和捕捉上下文,实现在排序阶段同时考虑上下文并提高推荐效果。实验结果证明PIER在公开和工业数据集上的优势,已在美团外卖广告场景中取得成功。
文章探讨了Feed流推荐中的上下文依赖问题,介绍了PIER框架,它通过FPSM和OCPM模块处理复杂度和捕捉上下文,实现在排序阶段同时考虑上下文并提高推荐效果。实验结果证明PIER在公开和工业数据集上的优势,已在美团外卖广告场景中取得成功。
Feed流推荐作为目前最主流的推荐载体,其推荐质量直接影响用户体验/商家效益/平台收入等多个核心指标。Feed推荐特点是为每个用户的请求生成并展示多个items,用户的点击行为会同时受到上文和下文影响。由于传统point-CTR预测是在展现items产生之前进行的,导致无法利用上下文信息,推荐质量受损。目前工业届更多考虑重排方案,然而由于排列的多样性,穷举会导致排列个数过多,实际很难落地。目前业界通常存在两种近似方案:
- 只考虑位置偏置和上文信息,但忽略下文影响效果;
- 同时考虑上下文,Listwise预估后重新排序,该方案存在Evaluation Before Reranking的问题。
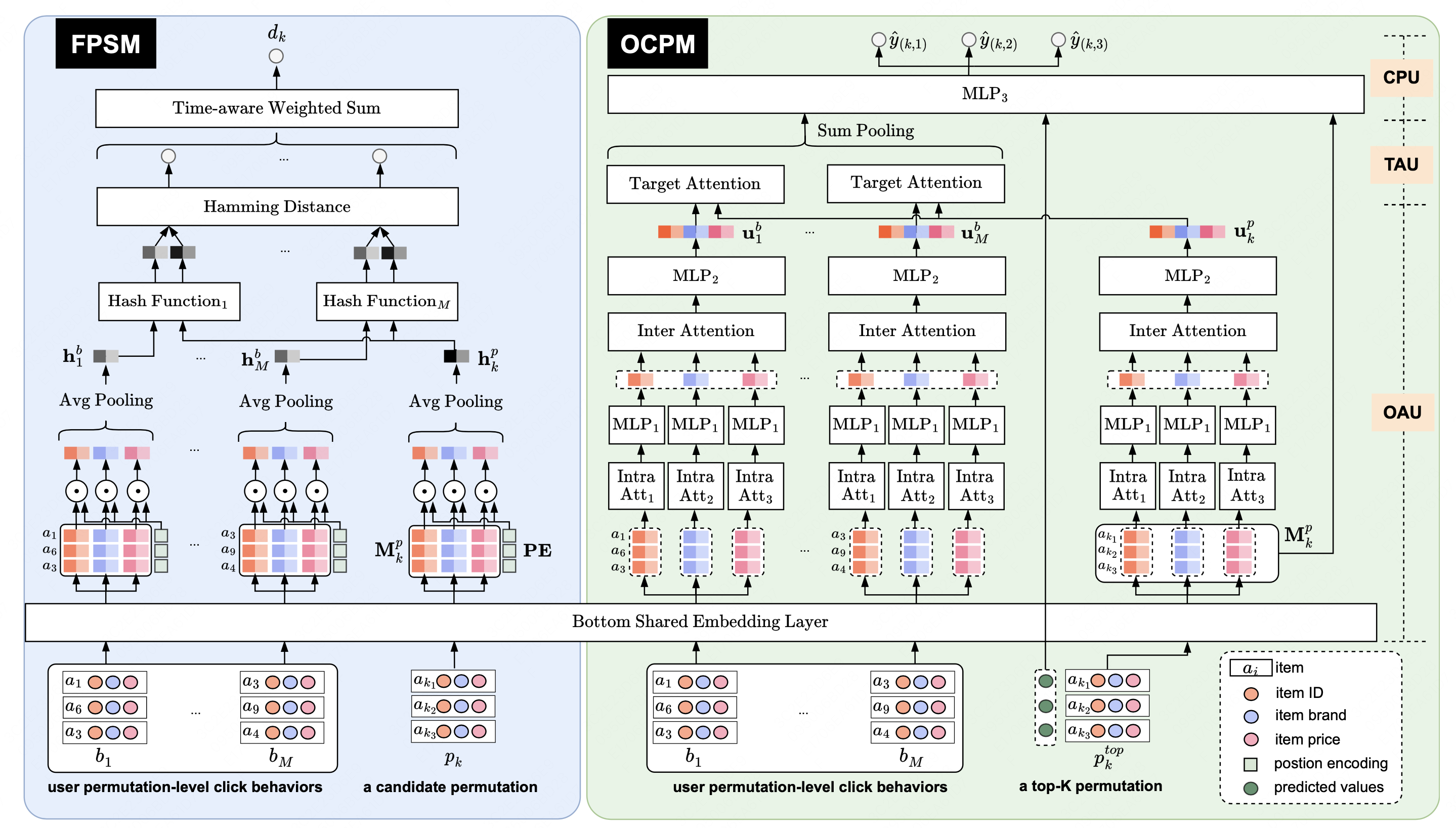
以上两个方案在效果上均有损,因此如何在重排阶段同时考虑上下文,并且降低复杂度兼顾可落地性,是一个非常重要的问题。针对以上问题,论文提出了一个名为PIER的端到端重新排序框架,该框架遵循两阶段范式并包含两个主要模块,分别称为FPSM 和OCPM。基于用户页面兴趣偏好,在FPSM中应用SimHash从全排列中快速的生成候选列表集合,降低了落地复杂度;然后在OCPM中设计了一种新颖的全向注意力建模机制,以更好地捕获列表中的上下文信息;最后,通过引入对比学习损失以端到端的方式联合训练这两个模块,使用OCPM的预测值来指导FPSM生成更好的列表。离线实验结果表明,PIER在公开和工业数据集上均优于基线模型,目前已经部署到美团外卖广告场景,取得了较为显著的成果。
论文看的部分后面再更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









