







 本文介绍了美团"猜你喜欢"展位如何应用强化学习进行优化,特别是基于多轮交互的MDP建模和改进的DDPG模型。MDP建模中,状态包括用户意图和场景,动作是对推荐列表的调整,奖励依据用户反馈。在DDPG模型的改进中,采用Advantage函数、State权值共享、On-policy策略和多组并行策略,实现了训练效率和性能的提升,带来了点击率和用户停留时长的积极变化。
本文介绍了美团"猜你喜欢"展位如何应用强化学习进行优化,特别是基于多轮交互的MDP建模和改进的DDPG模型。MDP建模中,状态包括用户意图和场景,动作是对推荐列表的调整,奖励依据用户反馈。在DDPG模型的改进中,采用Advantage函数、State权值共享、On-policy策略和多组并行策略,实现了训练效率和性能的提升,带来了点击率和用户停留时长的积极变化。
1 概述
“猜你喜欢”是美团流量最大的推荐展位,位于首页最下方,产品形态为信息流,承担了帮助用户完成意图转化、发现兴趣、并向美团点评各个业务方导流的责任。经过多年迭代,目前“猜你喜欢”基线策略的排序模型是业界领先的流式更新的Wide&Deep模型[1]。考虑Point-Wise模型缺少对候选集Item之间的相关性刻画,产品体验中也存在对用户意图捕捉不充分的问题,从模型、特征入手,更深入地理解时间,仍有推荐体验和效果的提升空间。近年来,强化学习在游戏、控制等领域取得了令人瞩目的成果,我们尝试利用强化学习针对以上问题进行优化,优化目标是在推荐系统与用户的多轮交互过程中的长期收益。
在过去的工作中,我们从基本的Q-Learning着手,沿着状态从低维到高维,动作从离散到连续,更新方式从离线到实时的路径进行了一些技术尝试。本文将介绍美团“猜你喜欢”展位应用强化学习的算法和工程经验。第2节介绍基于多轮交互的MDP建模,这部分和业务场景强相关,我们在用户意图建模的部分做了较多工作,初步奠定了强化学习取得正向收益的基础。第3节介绍网络结构上的优化,针对强化学习训练不稳定、难以收敛、学习效率低、要求海量训练数据的问题,我们结合线上A/B Test的线上场景改进了DDPG模型,取得了稳定的正向收益。第4节介绍轻量级实时DRL框架的工作,其中针对TensorFlow对Online Learning支持不够好和TF serving更新模型时平响骤升的问题做了一些优化。
2 MDP建模
在“猜你喜欢“展位中,用户可以通过翻页来实现与推荐系统的多轮交互,此过程中推荐系统能够感知用户的实时行为,从而更加理解用户,在接下来的交互中提供更好的体验。“猜你喜欢”用户-翻页次数的分布是一个长尾的分布,在图2中我们把用户数取了对数。可知多轮交互确实天然存在于推荐场景中。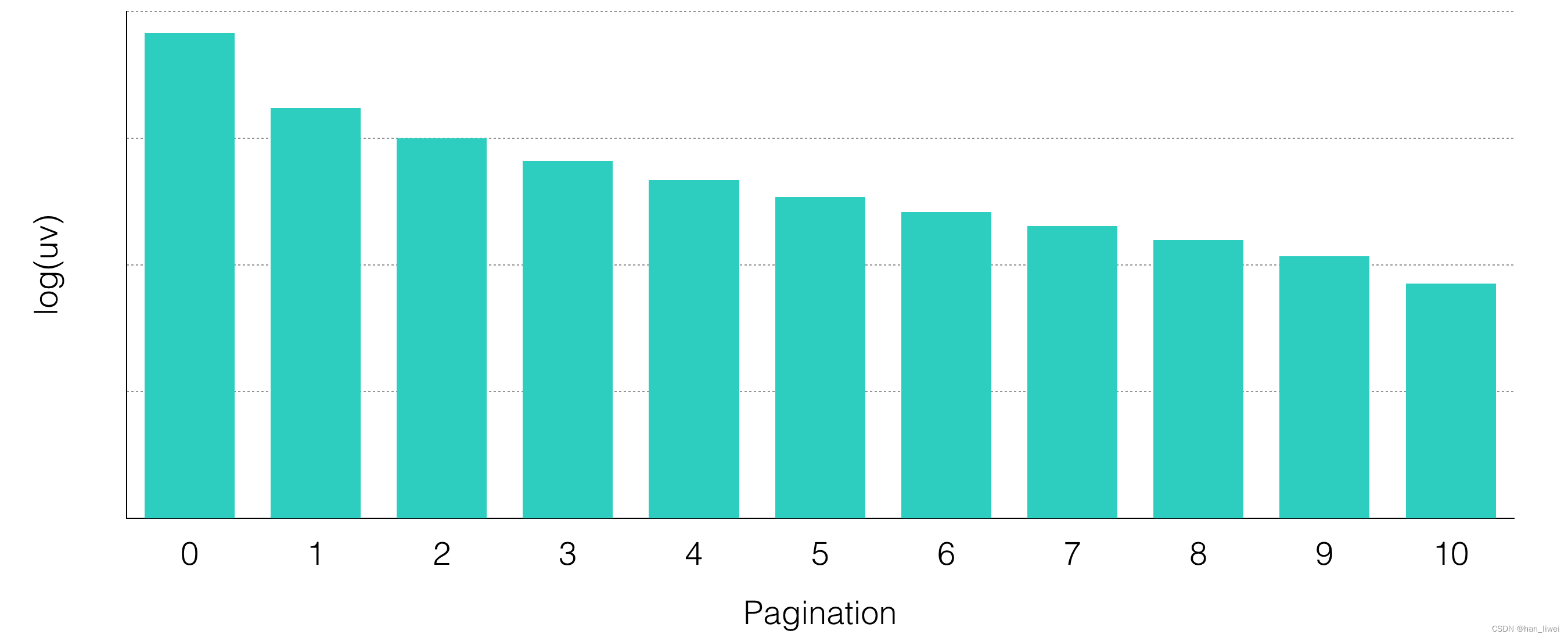
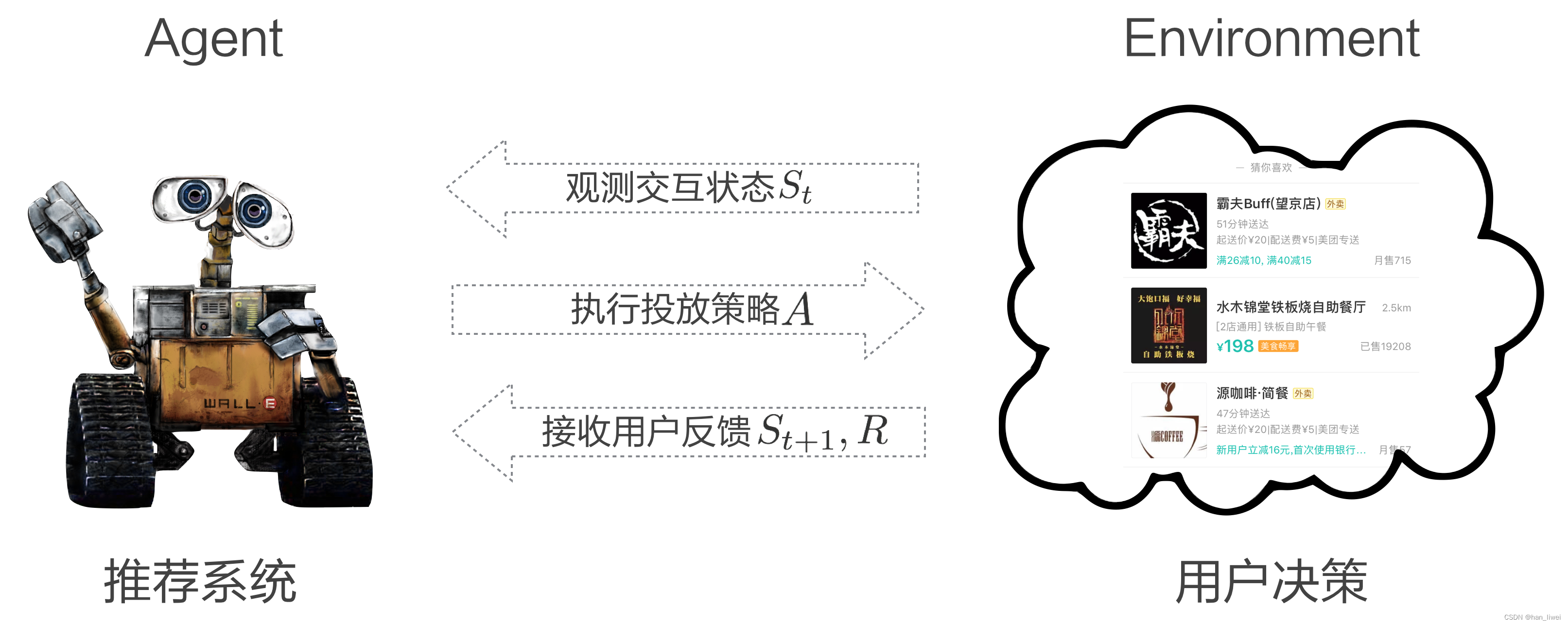
在这样的多轮交互中,我们把推荐系统看作智能体(Agent),用户看作环境(Environment),推荐系统与用户的多轮交互过程可以建模为MDP:
- State:Agent对Environment的观测,即用户的意图和所处场景。
- Action:以List-Wise粒度对推荐列表做调整,考虑长期收益对当前决策的影响。
- Reward:根据用户反馈给予Agent相应的奖励,为业务目标直接负责。
- P(s,a):Agent在当前State s下采取Action a的状态转移概率。
我们的优化目标是使Agent在多轮交互中获得的收益最大化:
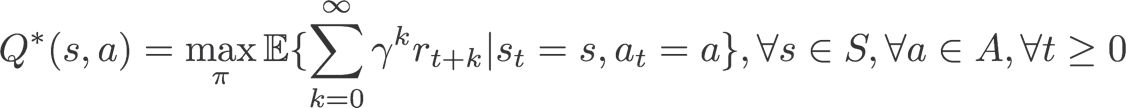
2.1 状态建模
状态来自于Agent对Environment的观察,在推荐场景下即用户的意图和所处场景
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1719
1719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









