






HuggingFace
HuggingFace 是类似于 GitHub 的社区,它主要提供各种的模型的使用,和 github 不同的是,HuggingFace 同时提供了一套框架,进行模型推理,模型训练、和模型库文件的管理等等。本文将介绍,如何快速使用 HuggingFace框架,包括 Pipeline,AutoModel 等。
Pipeline
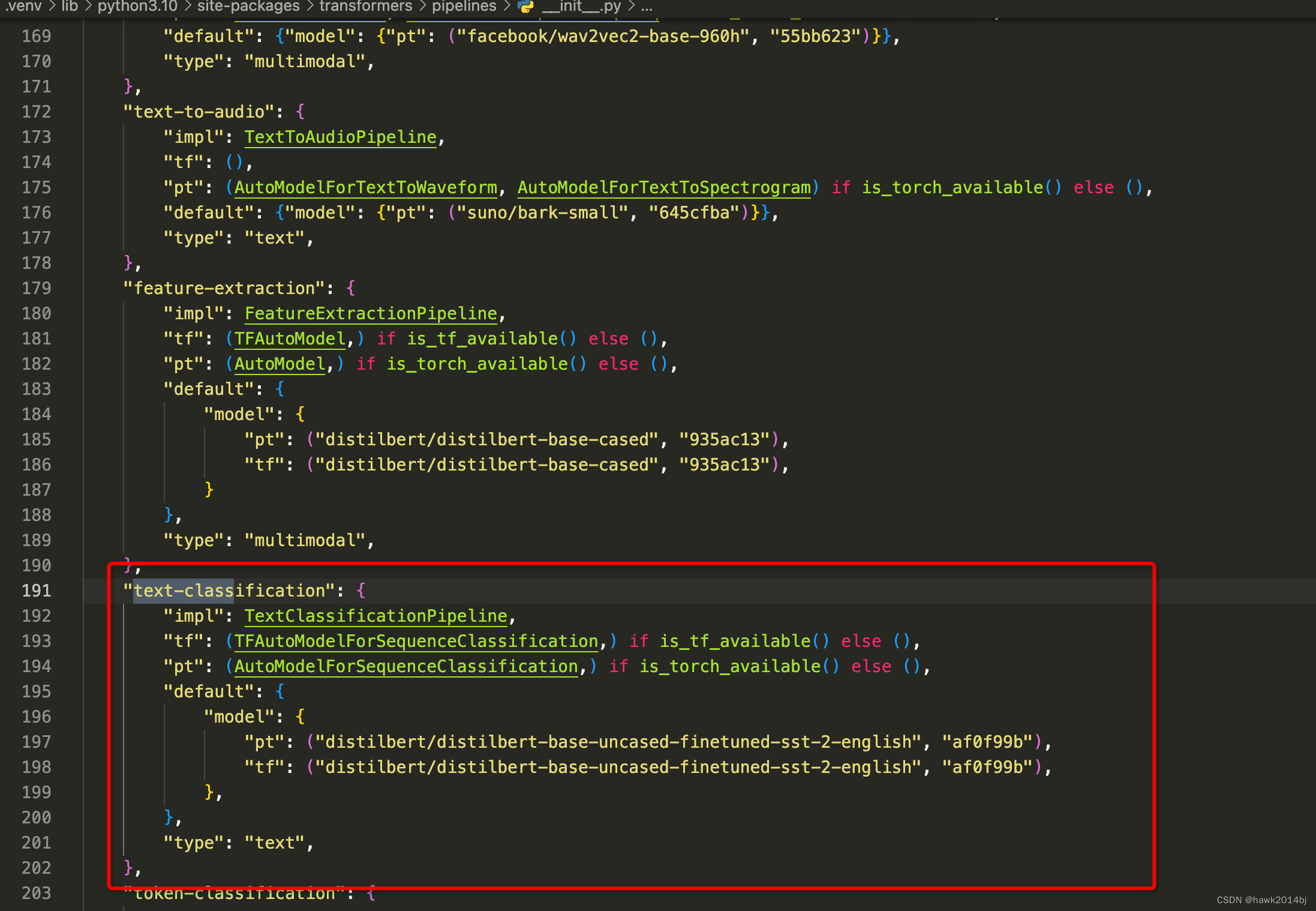
通过 Pipeline 进行模型推理,代码中可以看到pipeline 传入了一个参数,第一参数为 task,传入的是 Task, Task对应是那个模型呢?通过源代码我们看到默认分类模型使用的是 Bert模型:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("We are very happy to show you the 🤗 Transformers library.")
AutoClass
使用 AutoXXX 加载模型模型,或者根据不同的模型导入 Tokenizer或者 Processor,HuggingFace 框架做了一层抽象,对于某一类模型,例如文本模型,模型架构架构相似但是参数维度可能不一样,这种情况下,通过 AutoTokenizer 我们就可以获取到不同模型 Tokenizer,而不用为每个模型都定义一个处理类。以下是两个例子:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
from transformers import AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
所以当要模型处理器时,无论是文本模型还是视觉模型,先要找 HuggingFace 中 Auto 打头的类。
数据处理
HuggingFace 处理数据主要通过两个方法
load_dataset_builder
方式返回 dataset 元数据,描述数据集信息:
ds_builder = load_dataset_builder("rotten_tomatoes")
#描述信息
ds_builder.info.description
#数据集特征
ds_builder.info.features
{'label': ClassLabel(num_classes=2, names=['neg', 'pos'], id=None),
'text': Value(dtype='string', id=None)}
load_dataset
用于导入数据,这个 split 代表获取数据集中的训练、验证或者测试类型的数据
load_dataset("PolyAI/minds14", name="en-US", split="train")
总结
HuggingFace 框架使用起来很简单,通过 Pipeline 可以进行模型的推理,如果需要训练,通过 AutoClass 导入模型处理器例如 Tokenizer 或者 Processor,在导入训练数据集,同时也可以使用 PEFT 进行 Lora 微调。
常见错误
Http 401 错误
读取模型无权限错误,登录 HuggingFace,右上角点头像,进入 setting 获取 token,下载模型前先登录。
from huggingface_hub import login
login(token = 'xxxxxxxxxxxxxxxx',add_to_git_credential=True)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









