






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
多元线性回归模型 Multiple Linear Regression
一、多元线性回归
多元线性回归(Multiple Linear Regression)是一种统计方法,用于通过多个特征变量来预测一个目标变量。
简单线性回归:影响Y的因素唯一,只有一个。
多元线性回归:影响Y的因数不唯一,有多个。
与一元线性回归一样,多元线性回归自然是一个回归问题。
● 一元线性回归方程:Y=β0+β1X+ϵ。
● 多元线性回归方程:Y=β0+β1X1+β2X2+.......+βnXn+ϵ。
其中:
- X 是特征变量(自变量)
- Y 是目标变量(因变量)
- X1,X2,....,Xn是特征变量
- β0是截距(intercept),即X=0时Y的预测值
- β1,β2,....,βn是回归系数(regression coefficients),表示X每增加一个单位,Y的变化量
- ϵ是误差项(error term),表示预测值与实际值的差异
多元线性回归的目标是找到最佳的回归系数,使得预测值Y^与实际值Y之间的差异(误差)最小化。通常使用最小二乘法(Ordinary Least Squares, OLS)来估计回归系数
二、代码实现 (用其他三个变量来预测花瓣长度 Pental Length)
1. 导入数据集
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据集
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width', 'Class']
dataset = pd.read_csv(url, names=names)
dataset
3. 提取特征和目标变量
# 提取特征和目标变量
X = dataset.iloc[:, [0, 1, 3]].values # sepal length, sepal width, petal width
y = dataset.iloc[:, 2].values # petal length4. 划分为训练集和测试集
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)5. 创建线性多元回归模型并训练模型
# 创建线性回归模型
model = LinearRegression()
# 使用训练集训练模型
model.fit(X_train, y_train)6. 在测试集上预测结果
# 使用测试集进行预测
y_pred = model.predict(X_test)7. 结果可视化
# 绘制图像
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 绘制训练集结果
sns.scatterplot(x=model.predict(X_train), y=y_train, color='blue', label='Predicted vs Actual (Training)', ax=ax1)
ax1.set_title('Training set results')
ax1.set_xlabel('Predicted Petal Length')
ax1.set_ylabel('Actual Petal Length')
ax1.legend()
# 绘制测试集结果
sns.scatterplot(x=y_pred, y=y_test, color='red', label='Predicted vs Actual (Testing)', ax=ax2)
ax2.set_title('Test set results')
ax2.set_xlabel('Predicted Petal Length')
ax2.set_ylabel('Actual Petal Length')
ax2.legend()
plt.tight_layout()
plt.show()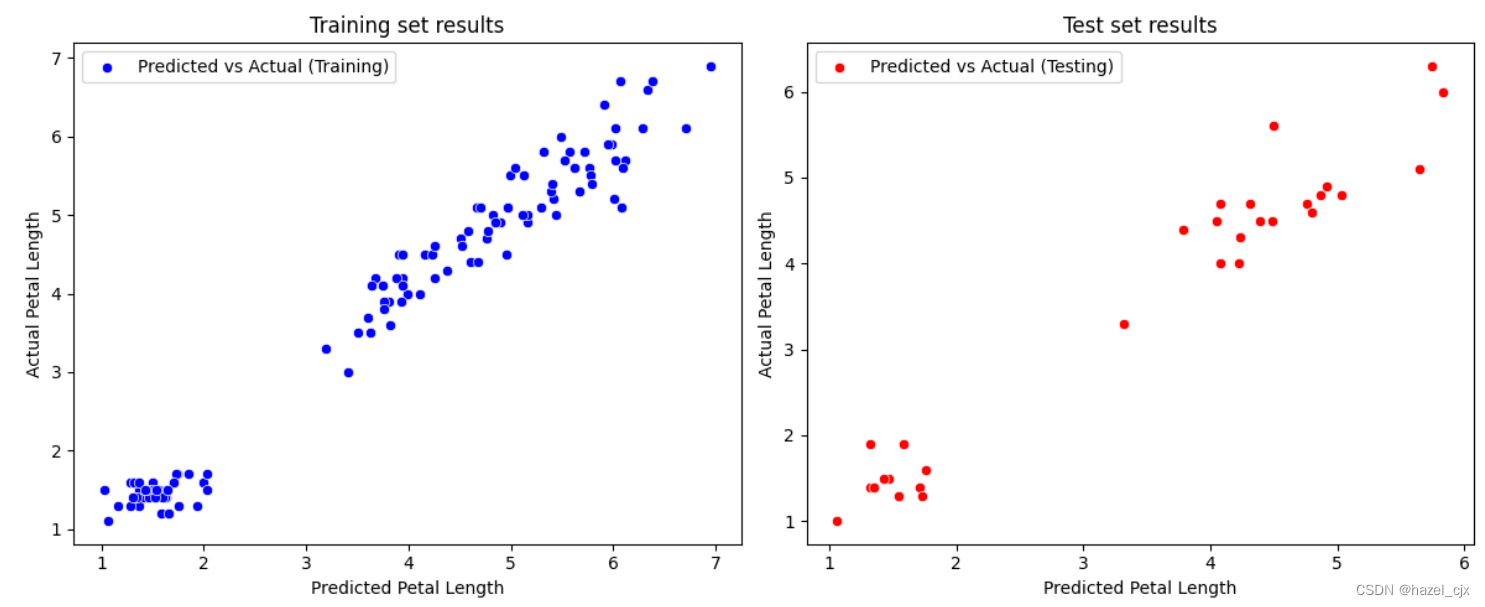
总结
通过多元线性回归,我们可以利用多个特征变量来进行预测,帮助我们更准确地理解和预测复杂现象。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









