






前言:
前段时间,博主对于YOLOV8的模型进行了升级,加入了注意力机制和BIFPN网络,但是对于这个网络整改过的效果没有测试过,所以博主基于此想到了之前做过的一个项目,基于YOLOV8的疲劳驾驶系统设计,将修改过的模型投入到这边试验一下,看看最终效果。
正文开始:
原版的YOLOV8下载
这里博主先将原版的YOLOv8模型给放出来, 原版链接 YOLOv8(You Only Look Once Version 8)是YOLO系列目标检测模型的最新版本,它在速度与精度方面做了显著优化,继续延续YOLO系列一贯的实时性与高效性特性。YOLOv8的设计通过许多技术创新,进一步提升了目标检测性能,特别是在处理复杂场景与多目标检测时,展现了出色的能力。
主要特点与优势:
高效的架构设计: YOLOv8在网络架构上进行了改进,采用了更加先进的卷积神经网络(CNN)结构。这个创新使得模型能以更高的检测精度进行目标识别,同时减少推理时间,从而满足实时性要求。
多目标检测能力: 相较于之前的版本,YOLOv8在多目标检测方面表现更为出色。无论是在复杂背景下,还是在动态变化的场景中,YOLOv8都能高效地识别多个目标并进行准确的定位和分类。
多尺度特征融合: 传统的目标检测方法在面对不同尺寸目标时,可能会受到局限。而YOLOv8通过创新的特征融合技术,增强了其在不同尺度上的检测能力,能够准确识别从微小物体到大物体的各种目标。
自动化超参数调整: YOLOv8引入了超参数调优技术,可以在训练过程中自动优化超参数。这使得模型在面对不同数据集和应用场景时,能够自动调整训练参数,以提升精度和效率,减少人工干预。
可迁移性与高效性: YOLOv8具有强大的平台迁移能力,能够在不同硬件平台上高效运行,同时具备很强的灵活性和可扩展性,使其适用于各种应用场景
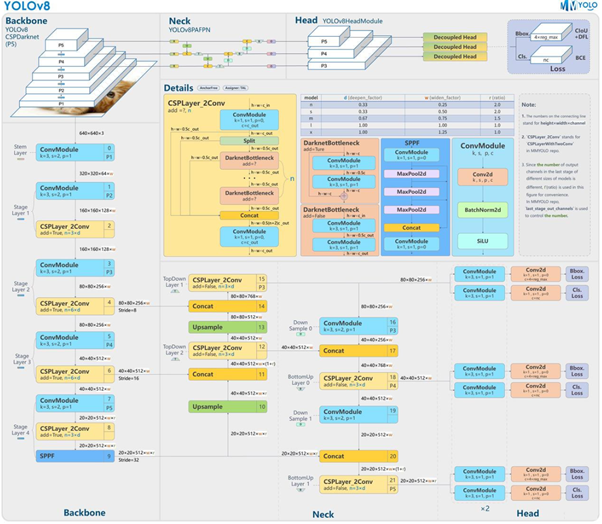
改进部分:
尽管YOLOv8具有较强的性能,但在处理复杂场景时,对于司机是否疲劳驾驶还是存在一些误差。所以博主针对现有YOLOv8模型进行升级,融合了注意力机制和BiFPN(Bidirectional Feature Pyramid Networks)网络,以提高模型在目标检测任务中的精度和效率。
GAM机制
AM(Global Attention Mechanism)是一种注意力机制,通过全局信息建模来提升模型性能,特别是在图像分类和目标检测任务中。与传统的局部注意力机制不同,GAM可以捕捉长距离的依赖关系,考虑全图的上下文信息,从而帮助模型在处理特定区域时更加准确地识别重要特征。
其主要优势在于通过动态调整特征的权重,能够加强对长距离依赖的建模,提升对复杂场景的识别能力,并增强模型的鲁棒性,特别是在噪声或遮挡的情况下表现更佳。
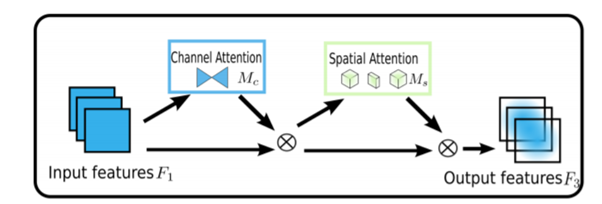
也许,泛泛的说GAM的原理会比较难懂,博主这里直接首先,要对yaml文件进行修改
nc: 10
scales:
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 3, GAMAttention, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
然后找到如下的目录'ultralytics/nn/modules',然后在这个目录下创建一个attention.py文件,将GAM的核心代码复制进去。
# gam核心代码
import torch
import torch.nn as nn
'''
https://arxiv.org/abs/2112.05561
'''
__all__ = (
"GAM",
)
class GAM(nn.Module):
def __init__(self, in_channels, rate=4):
super().__init__()
out_channels = in_channels
in_channels = int(in_channels)
out_channels = int(out_channels)
inchannel_rate = int(in_channels/rate)
self.linear1 = nn.Linear(in_channels, inchannel_rate)
self.relu = nn.ReLU(inplace=True)
self.linear2 = nn.Linear(inchannel_rate, in_channels)
self.conv1=nn.Conv2d(in_channels, inchannel_rate,kernel_size=7,padding=3,padding_mode='replicate')
self.conv2=nn.Conv2d(inchannel_rate, out_channels,kernel_size=7,padding=3,padding_mode='replicate')
self.norm1 = nn.BatchNorm2d(inchannel_rate)
self.norm2 = nn.BatchNorm2d(out_channels)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
b, c, h, w = x.shape
# B,C,H,W ==> B,H*W,C
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
# B,H*W,C ==> B,H,W,C
x_att_permute = self.linear2(self.relu(self.linear1(x_permute))).view(b, h, w, c)
# B,H,W,C ==> B,C,H,W
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.relu(self.norm1(self.conv1(x)))
x_spatial_att = self.sigmoid(self.norm2(self.conv2(x_spatial_att)))
out = x * x_spatial_att
return out
if __name__ == '__main__':
img = torch.rand(1,64,32,48)
b, c, h, w = img.shape
net = GAM(in_channels=c, out_channels=c)
output = net(img)
print(output.shape)
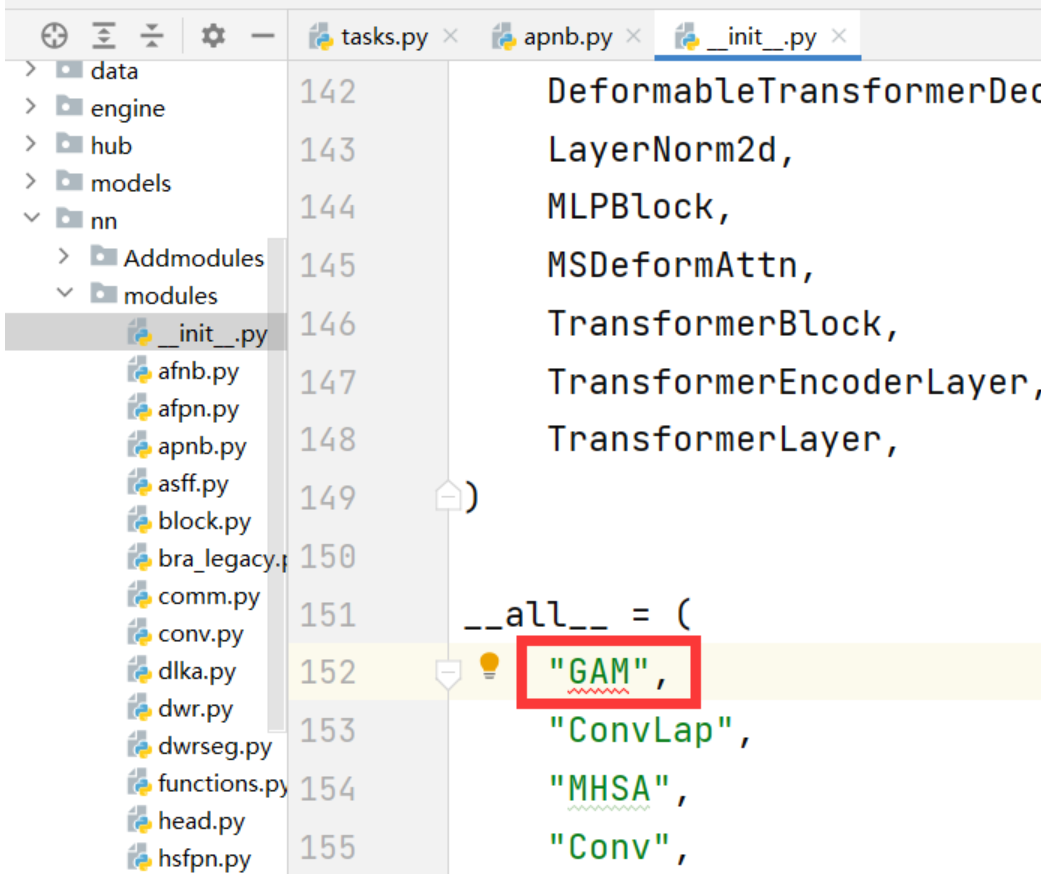
然后在ultralytics/nn/modules/init.py下增添如下代码,为的是激活GAM
from .attention import (
GAM,
)
同时在该文件的这个位置添加上GAM
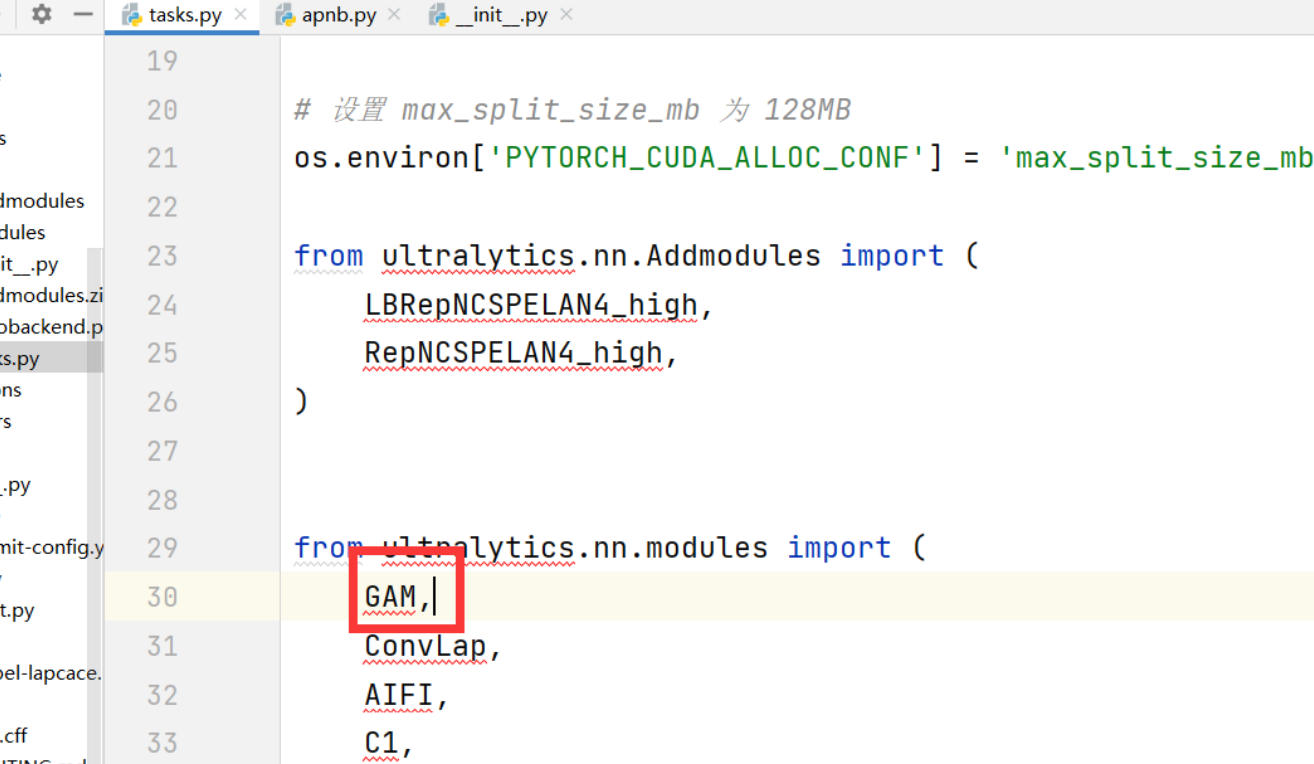
然后一定要注意,必须在在task.py中导入GAM,否则运行的时候会报错,博主第一次就没注意,然后找了好长时间
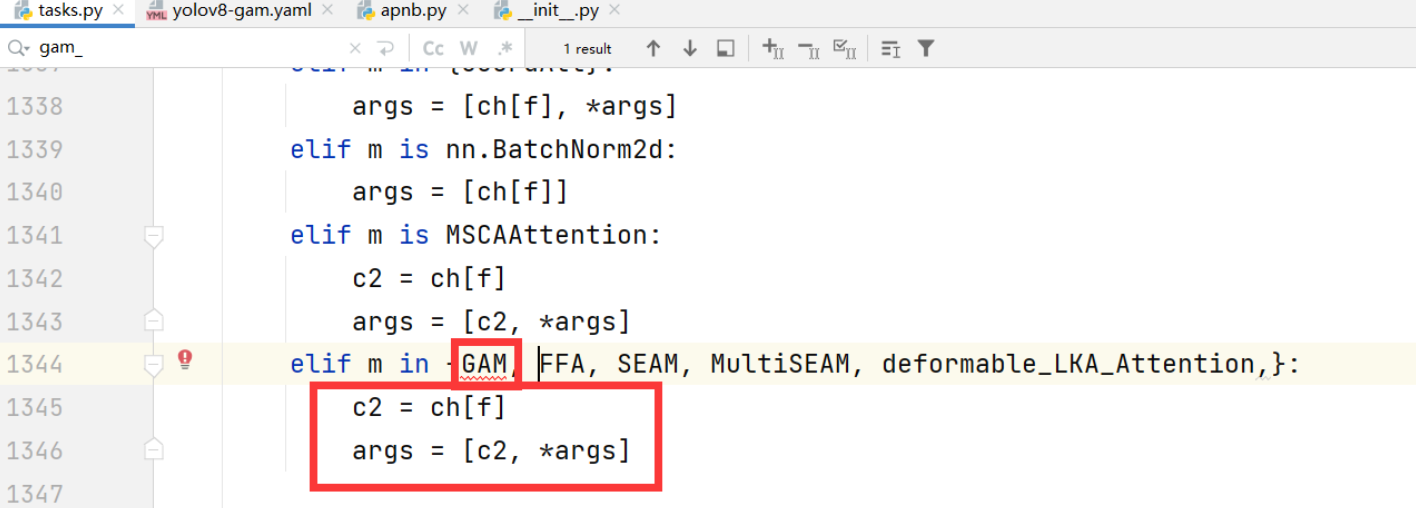
BiFPN(双向特征金字塔网络)
BiFPN(Bidirectional Feature Pyramid Network)是一种改进的特征金字塔网络(FPN),旨在提升多尺度物体检测任务中的特征融合效果。BiFPN通过更高效的跨层特征融合,能够更好地处理不同尺度的信息,增强模型对不同大小物体的识别能力。
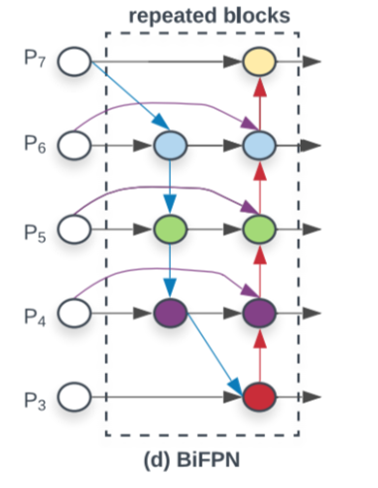
BiFPN采用了双向特征融合策略。传统的FPN通常仅通过从低到高的单向传递信息,而BiFPN则在高层和低层之间实现双向的信息流动。这种双向特性使得低层的细节特征和高层的语义特征能够更好地融合,提高了特征表示的丰富性和准确性。
在代码上的修改,在nn文件夹中新建bifpn.py文件,引入BiFPN网络结构
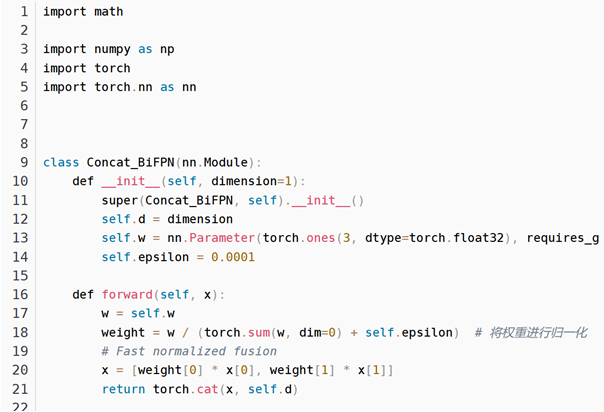
完整的代码如下
import math
import numpy as np
import torch
import torch.nn as nn
class Concat_BiFPN(nn.Module):
def __init__(self, dimension=1):
super(Concat_BiFPN, self).__init__()
self.d = dimension
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1]]
return torch.cat(x, self.d)
训练模型
上面对模型进行修改过后,就可以收集数据进行训练
上图是博主制作的一些数据集。
使用LabelImg标注一下数据集

然后开始训练即可。
UI界面的设计
点击基于YOLOV8的疲劳驾驶系统设计查看全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









