






机器学习是人工智能的核心领域之一,它赋予计算机从数据中学习并改进自身性能的能力。随着大数据和计算能力的飞速发展,机器学习在图像识别、自然语言处理、医疗诊断、金融风控等多个领域展现出巨大潜力。
一、引言
在数据驱动的时代,机器学习已成为从海量数据中提取知识、预测未来趋势的关键技术。无论是自动驾驶汽车的决策系统,还是推荐系统背后的个性化算法,机器学习都扮演着不可或缺的角色。《机器学习》(西瓜书)第1章绪论介绍了机器学习的基本概念、方法论及发展历程。本文将系统梳理第1章的核心内容,结合代码示例,帮助读者建立扎实的基础,通过实践加深理解。
二、机器学习的定义与核心思想
2.1 机器学习的定义
机器学习是一门研究如何通过计算手段,利用经验(通常以数据形式存在)来改善系统自身性能的学科。其核心目标是让计算机从数据中学习规律,并对未知数据进行预测或决策。例如,给定一组西瓜的特征数据(如色泽、根蒂、敲声),通过机器学习方法训练模型,判断新西瓜是否成熟。
2.2 关键要素
机器学习的核心要素包括以下几个方面:
- 数据:学习的基础,通常表示为样本集合。
- 数据可以是结构化的(如表格数据)、非结构化的(如图像、文本)或半结构化的(如XML、JSON)
- 例如,西瓜数据集中的每个样本包含多个特征和一个标签。
- 模型:从数据中学习到的规律或模式。
- 模型可以是参数化的(如线性回归)、非参数化的(如K近邻)或基于规则的(如决策树)。
- 例如,线性回归模型可以表示为 y=wx+by=wx+b。
- 算法:用于从数据中提取模型的具体方法。
- 算法可以是基于优化的(如梯度下降)、基于统计的(如贝叶斯方法)或基于启发式的(如遗传算法)。
- 性能评估:衡量模型在未知数据上的表现。
- 可以是定量的(如准确率、均方误差)或定性的(如可视化分析)。
2.3 核心思想
2.3.1 扩展讨论:归纳与演绎的对比
在机器学习中,归纳学习是主要方法,但与传统的演绎推理(从一般到特殊)相比,归纳学习具有更高的不确定性。例如,演绎推理可以从“所有乌黑西瓜都成熟”推出“这个乌黑西瓜成熟”,而归纳学习则需要从有限样本中推测一般规律,可能面临样本不足或噪声干扰的风险。这种不确定性正是机器学习需要解决的核心挑战之一。
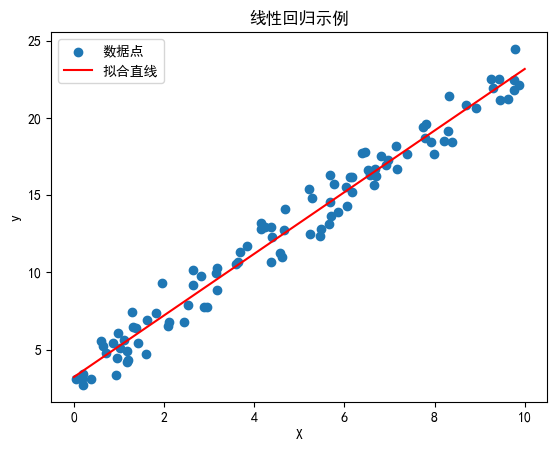
2.3.2 代码示例:线性回归学习规律
以下代码展示如何使用Python生成一个简单数据集,并通过线性回归学习其中的规律:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 生成随机数据
np.random.seed(0)
X = np.random.rand(100, 1) * 10 # 随机生成100个x值
y = 2 * X + 3 + np.random.randn(100, 1) # y = 2x + 3 + 噪声
# 训练线性回归模型
model = LinearRegression()
model.fit(X, y)
# 预测
X_new = np.array([[0], [10]])
y_pred = model.predict(X_new)
# 可视化
plt.scatter(X, y, label='数据点')
plt.plot(X_new, y_pred, color='red', label='拟合直线')
plt.title('线性回归示例')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.savefig('linear_regression.png')
三、基本术语与概念解析
3.1 数据集(Dataset)
数据集是机器学习的基础,由一组样本组成。每个样本包含以下要素:
- 特征(Feature):描述样本的属性,如西瓜的色泽(青绿、乌黑)、根蒂(蜷缩、稍蜷)。
- 标签(Label):样本的输出或目标值,如西瓜是否成熟(是/否)。
- 示例(Instance):一个具体样本,例如“色泽=青绿,根蒂=蜷缩,敲声=浊响,标签=是”。
- 示例空间(Instance Space):所有可能样本构成的集合,通常是一个多维特征空间。
3.2 监督学习 vs. 无监督学习
机器学习任务根据是否需要标签可分为监督学习、无监督学习、强化学习三类:
| 类型 | 标签需求 | 典型任务 | 示例 |
|---|---|---|---|
| 监督学习 | 需要标签 | 分类、回归 | 西瓜成熟度分类 |
| 无监督学习 | 无需标签 | 聚类、降维 | 顾客群体划分 |
| 半监督学习 | 部分标签 | 结合有标签与无标签数据 | 医学影像辅助诊断 |
| 强化学习 | 延迟反馈 | 通过环境交互学习策略 | 自动驾驶决策 |
强化学习与监督学习、无监督学习的主要区别在于其反馈机制。在自动驾驶中,强化学习通过试错(例如调整方向盘角度)从环境中获取奖励(如避免碰撞),而非直接依赖标注数据,这种方法特别适合动态决策场景。
代码示例:监督学习与无监督学习的对比
以下代码使用鸢尾花数据集(Iris)展示监督学习(分类)和无监督学习(聚类)的区别:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.cluster import KMeans
# 加载数据
iris = load_iris()
# 监督学习:分类
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print(f'分类准确率: {accuracy:.2f}')
# 无监督学习:聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(iris.data)
print(f'前10个样本的聚类标签: {kmeans.labels_[:10]}')
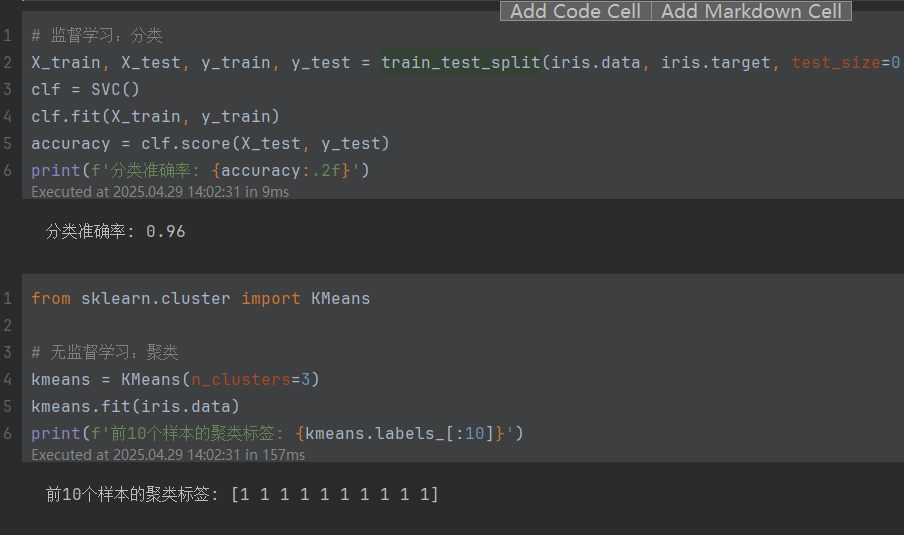
- 监督学习:使用支持向量机(SVM)对鸢尾花进行分类,输出准确率。
- 无监督学习:使用K均值算法对数据进行聚类,输出每个样本的簇标签。

















 3230
3230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









