







机器学习中数据集的划分
1.如何划分数据集
在机器学习算法中,我们通常将原始数据集划分为三个部分:
- 训练集:训练模型
- 验证集:选择模型
- 测试集:评估模型
我们首先将数据集划分为训练集和验证集,由于模型的构建过程中也需要检验模型的配置,以及训练程度是过拟合还是欠拟合,所以会将训练数据再划分为两个部分,一部分是用于训练的训练集,另一部分是进行检验的验证集。
训练集用于训练得到神经网络模型,然后用验证集验证模型的有效性,挑选获得最佳效果的模型。验证集可以重复使用,主要是用来辅助我们构建模型的。最后,当模型“通过”验证集之后,我们再使用测试集测试模型的最终效果,评估模型的准确率,以及误差等。
注意:我们不能用测试集数据进行训练,之所以不用测试集,是因为随着训练的进行,网络会慢慢过拟合测试集,导致最后的测试集没有参考意义。
总结一下:
- 训练集用来计算梯度更新权重,即训练模型;
- 验证集用来做模型选择,而且可以避免过拟合。在训练过程中,我们通常用它来确定一些超参数。(例:根据验证集的准确率来确定early stoping的epoch大小,根据验证集确定学习率等等)
- 测试集则给出一个准确率以判断网络性能的好坏。
下面给出一个图片加强理解
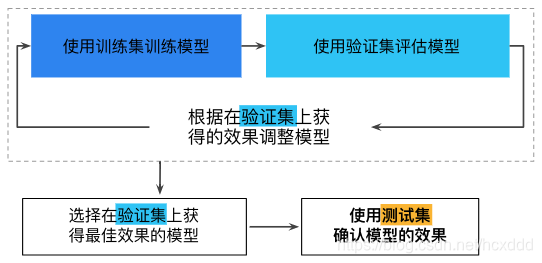
2.数据集的划分方法
数据集的划分一般有三种方法:
1.留出法(Hold-out)
为了保证数据分布的一致性,通常我们采用分层采样的方式来对数据进行采样。
1.如果数据比较少:
只划分训练集和测试集则为:70%验证集,30%测试集;
划分训练集、验证集和测试集则为:60%训练集,20%验证集,20%测试集。
2.数据比较多:
只需要取一小部分当做测试集和验证集,其他的都当做训练集。
然后使用训练集来生成模型,验证集来选择模型,最后用测试集来测试模型的正确率和误差,以验证模型的有效性。
这种方法常见于决策树、朴素贝叶斯分类器、线性回归和逻辑回归等任务中。
缺点:只进行了一次划分,数据结果具有偶然。
2.交叉验证法(Cross Validation)
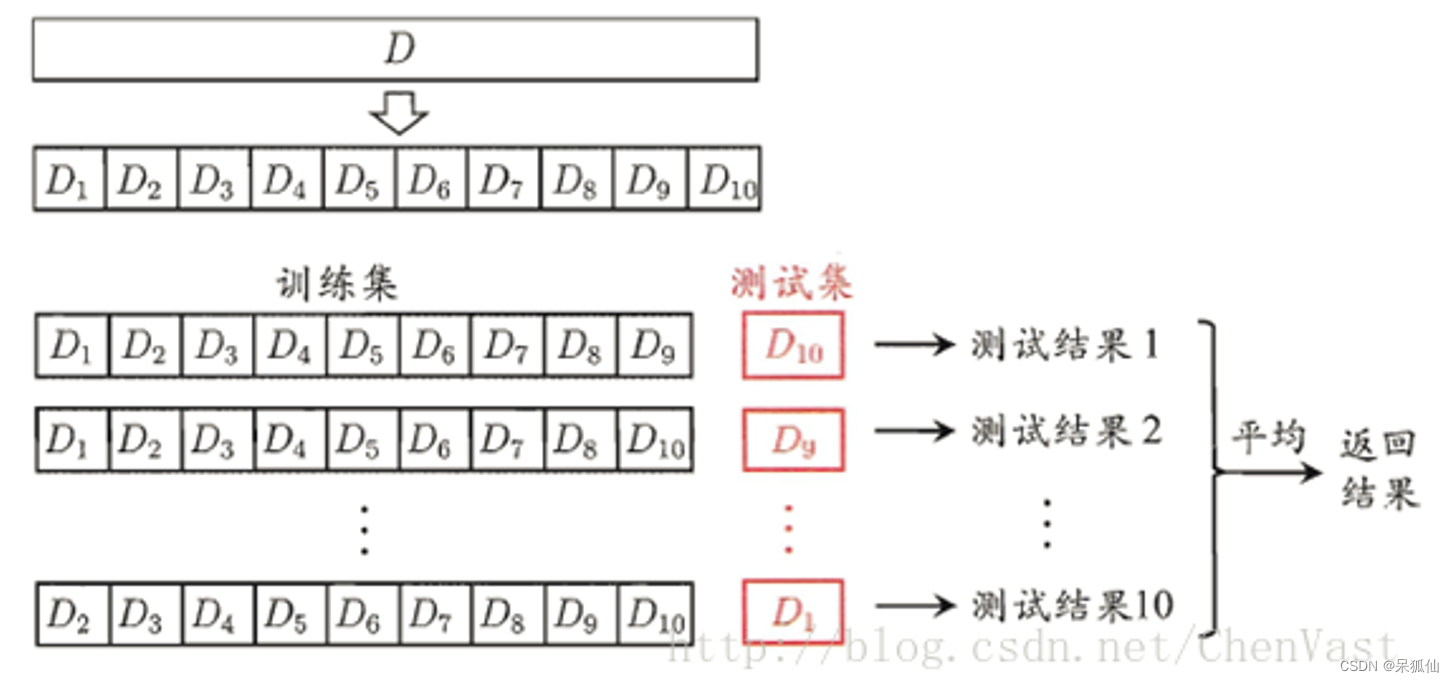
我们经常使用交叉验证方法来评估模型。有两种形式:K折交叉验证和留一法。
K折交叉验证的基本思想
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3194
3194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









