







有 a和b 两个特征,那么它的 2 次多项式的次数为 1, a, b,
, ab,
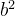
PolynomialFeatures 这个类有 3 个参数
degree:控制多项式的次数;
interaction_only:默认为 False,如果指定为 True,那么就不会有特征⾃⼰和⾃⼰结合的项,组合的特征中没有 a 和 b ;
include_bias:默认为 True 。如果为 True 的话,那么结果中就会有 0 次幂项,即全为 1 这⼀列。
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
from sympy import false
X = np.arange(6).reshape(3, 2)
print(X)
poly = PolynomialFeatures(degree=2)
res = poly.fit_transform(X)
print(res)结果
[[0 1]
[2 3]
[4 5]][[ 1. 0. 1. 0. 0. 1.]
[ 1. 2. 3. 4. 6. 9.]
[ 1. 4. 5. 16. 20. 25.]]
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
from sympy import false
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
data = np.array([[ -2.95507616, 10.94533252],
[ -0.44226119, 2.96705822],
[ -2.13294087, 6.57336839],
[ 1.84990823, 5.44244467],
[ 0.35139795, 2.83533936],
[ -1.77443098, 5.6800407 ],
[ -1.8657203 , 6.34470814],
[ 1.61526823, 4.77833358],
[ -2.38043687, 8.51887713],
[ -1.40513866, 4.18262786]])
X = data[:, 0].reshape(-1, 1) # 将array转换成矩阵 reshape(-1,1)转换成1列
y = data[:,1].reshape(-1, 1)
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
print(X_poly)
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
print(lin_reg.intercept_, lin_reg.coef_)
# [ 2.60996757] [[-0.12759678 0.9144504 ]]
X_plot = np.linspace(-3, 3, 1000).reshape(-1, 1)
X_plot_poly = poly_features.fit_transform(X_plot)
y_plot = lin_reg.predict(X_plot_poly)
plt.plot(X_plot, y_plot, 'red')
plt.plot(X, y, 'b.')
plt.show()
y_pre = lin_reg.predict(X_poly)
mean_squared_error(y, y_pre)

结果:[2.60996757] [[-0.12759678 0.9144504 ]]
方程为为h = −0.13x + 0.91
+ 2.61
引⼊⾼阶项,训练误差明显下降,那么训练误差是否还有进⼀步下降的空间呢?
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
from sympy import false
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
data = np.array([[ -2.95507616, 10.94533252],
[ -0.44226119, 2.96705822],
[ -2.13294087, 6.57336839],
[ 1.84990823, 5.44244467],
[ 0.35139795, 2.83533936],
[ -1.77443098, 5.6800407 ],
[ -1.8657203 , 6.34470814],
[ 1.61526823, 4.77833358],
[ -2.38043687, 8.51887713],
[ -1.40513866, 4.18262786]])
X = data[:, 0].reshape(-1, 1) # 将array转换成矩阵 reshape(-1,1)转换成1列
y = data[:,1].reshape(-1, 1)
def try_degree(degree, X, y):
poly_features_d = PolynomialFeatures(degree=degree, include_bias=False)
X_poly_d = poly_features_d.fit_transform(X)
lin_reg_d = LinearRegression()
lin_reg_d.fit(X_poly_d, y)
return {'X_poly': X_poly_d, 'intercept': lin_reg_d.intercept_, 'coef': lin_reg_d.coef_}
degree2loss_paras = []
for i in range(2, 20):
paras = try_degree(i, X, y)
# ⾃⼰实现预测值的求解
h = np.dot(paras['X_poly'], paras['coef'].T) + paras['intercept']
_loss = mean_squared_error(h, y)
degree2loss_paras.append({'d': i, 'loss': _loss, 'coef': paras['coef'], 'intercept': paras['intercept']})
min_index = np.argmin(np.array([i['loss'] for i in degree2loss_paras]))
min_loss_para = degree2loss_paras[min_index]
print(min_loss_para)
X_plot = np.linspace(-3, 1.9, 1000).reshape(-1, 1)
poly_features_d = PolynomialFeatures(degree=min_loss_para['d'], include_bias=False)
X_plot_poly = poly_features_d.fit_transform(X_plot)
y_plot = np.dot(X_plot_poly, min_loss_para['coef'].T) + min_loss_para['intercept']
plt.plot(X_plot, y_plot, 'red', label="degree12")
plt.plot(X, y, 'b.', label="X")
plt.legend(loc='best')
plt.show()

此时出现过拟合现象,鉴于该问题的普遍性和重要性,在满⾜要求的情况下,能选择简单模型时应该尽量选择简单的模型。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









