






sklearn.ensemble 模块包含了两种基于随机决策树的平均值算法:随机森林算法和Extra-Trees算法。两种算法都对树采用了打乱再组合(perturb-and-combine)技巧,意即在构建分类器的过程中,通过引入随机性来构建一个具有多样性的分类器集合。集成器的预测是由单个分类器取平均得到的。
跟其他分类器类似,森林分类器需要两个数组来拟合:一个稀疏或稠密的大小为[n_samples, n_features]的数组X,X对应训练样本,还包含一个大小为[n_samples]的数组Y,Y对应训练样本的目标值或称类别标签。
示例代码如下:
from sklearn.ensemble import RandomForestClassifier
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, Y)
跟决策树类似,森林也可以扩展到多输出问题,即数组Y的大小为[n_samples, n_outputs]。
随机森林
在随机森林中,集成器中的每棵树都是在训练集中通过有放回采样来构建的。因此,构建每棵树时,分割点对应的分割不再是所有特征中最好的分割。相反,所选分割是随机特征子集中对应的最好分割。由于这种随机性,森林的整体偏差相对单个非随机树而言通常会稍微增加,但是,由于后面会取平均,森林的方差也会减小的,而且方差的减小相对偏差的增加会更加合算,因此可以得到一个全局较好的模型。
跟原文有所不同 [B2001],scikit-learn执行中通过平均概率预测来组合这些分类器,而不是在每个分类器中对单个类进行投票。
在极致随机树中,随机分割更加随机了。跟随机树类似,只利用所有特征中的随机特征子集,不同的是,极致随机树不寻找最具判别性的阈值,而是对每个候选特征都随机产生一个阈值,然后从这些随机阈值中选择一个最好的阈值作为分割规则。这种做法通常可以更进一步地降低模型的方差,当然,也会使得偏差稍微有所增加。
具体示例代码如下:
from sklearn.cross_validation import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_blobs(n_samples=10000, n_features=10, centers=100,
... random_state=0)
clf = DecisionTreeClassifier(max_depth=None, min_samples_split=1,
... random_state=0)
scores = cross_val_score(clf, X, y)
scores.mean()
0.97...
clf = RandomForestClassifier(n_estimators=10, max_depth=None,
... min_samples_split=1, random_state=0)
scores = cross_val_score(clf, X, y)
scores.mean()
0.999...
clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,
... min_samples_split=1, random_state=0)
scores = cross_val_score(clf, X, y)
scores.mean() > 0.999
True
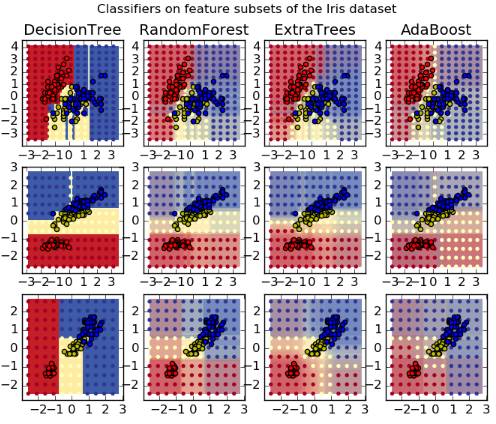
各种算法在数据集Iris上的实验结果如下图所示
主要参数
运用这些方法需要调节的主要参数是 n_estimators 和 max_features,前者是森林中树的棵树,越大越好,但是树越多,耗时也越久。另外,需要注意的是,当树的棵树达到某个值时,模型效果的提升就会变得没有那么明显。后面那个参数是分割节点时随机特征子集的大小,这个参数越小,方差减小得越多,但是偏差也会增加得越多。针对回归问题,这个参数的经验默认值等于特征数,而针对分类问题,这个参数的默认值是特征数的平方根。通常情况下,同时设置max_depth=None,并且设置min_samples_split=1,可以取得好的效果。虽然这些参数通常不是最优的,也可能消耗较多的RAM。最好的参数通常需要通过交叉验证法得到。另外,随机森林中,通常会采取采样方法,即令bootstrap=True,而在极致随机树中利用这个数据集,即令bootstrap= False。利用采样方法可以在剩余样本或out-of-bag的样本中估计泛化误差,这可以通过设置 oob_score=True 来达到目的。
接下来讨论下并行化实现。
这种方法通过设置参数 n_jobs 可以并行构建树,也可以并行计算预测值。如果令 n_jobs=k,则计算被分成 k 个任务,可以在机器的 k 个核上运行。如果令n_jobs=-1,则会用掉机器中所有的核。由于进程间需要通信,加速可能并不是线性的,即利用k个jobs不一定会加快k倍。构建多个树或者构建单棵树需要一定时间时,这种方法都可以加速很多。
接下来看看如何评估特征的重要性。
对于某个特征来讲,它在树中决策节点的相对排序即所处深度,可以用来衡量该特征关于所要预测的目标值的相对重要性。树顶端的特征可以用来对很多输入样本给出最终预测。这个特征所贡献的样本比例可以用来衡量特征的相对重要性。
通过对多个随机树取平均,就可以缩减这个估计的方差,并且可以用它来做特征选择。
下面的例子中,人脸识别任务中每个像素的相对重要性可以通过颜色编码来表示,其中所用模型是 ExtraTreesClassifier。

在实际应用中,这些估计存储成拟合模型的一个属性,即 feature_importances_。这是一个数组,它的格式是(n_features,),其中取值都是正的,并且和为1。元素的值越大,对预测函数的贡献越大,特征的重要性越大。
最后来看看完全随机树嵌入。
RandomTreesEmbedding可以对数据进行无监督的转换。利用完全随机树构成的森林,可以通过数据点结束时对应的叶子节点的指数对数据进行编码。这个指标编码风格是one-of-K,因此可以得到高维度,稀疏的二值编码。这种编码计算高效,并且可以用作其他学习任务的基础。编码的大小和稀疏度受树的棵数影响,也受每棵树的最大深度的影响。对于集成器中的每棵树,编码包含了一个记录。编码的规模至多是n_estimators * 2 ** max_depth,即森林中叶子节点对的最大数目。
由于邻居样本点更有可能位于一棵树中的同一片叶子上,因此,这个转换是一个具有隐含性的非参数密度估计问题。
参考资料
http://scikit-learn.org/stable/modules/ensemble.html#forests-of-randomized-trees
[B2001] Breiman, “Random Forests”, Machine Learning, 45(1), 5-32, 2001.
[B1998] Breiman, “Arcing Classifiers”, Annals of Statistics 1998.
[GEW2006] P. Geurts, D. Ernst., and L. Wehenkel, “Extremely randomized trees”, Machine Learning, 63(1), 3-42, 2006.















 2743
2743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









