









在学习深度学习或者阅读各类论文中经常会遇到模型各种评估指标,对于这些指标假如不够熟悉,会增加论文阅读难度,本文主要介绍深度学习常用各类指标的详解,希望对你有用。
1.混淆矩阵
混淆矩阵是机器学习领域中一种重要的评估工具,它通过可视化方式展示了模型的预测结果与真实标签之间的关系。在监督学习中,混淆矩阵特别有用,而在无监督学习中,通常称为匹配矩阵。混淆矩阵的结构清晰
(1)每一列代表预测类别,
(2)每一行代表真实归属类别,
矩阵中的数值表示了预测为该类别或属于该类别的样本数量。通过混淆矩阵,可以直观地了解模型的分类精度,找出模型预测错误的类别,从而指导我们改进模型,提高分类精度。
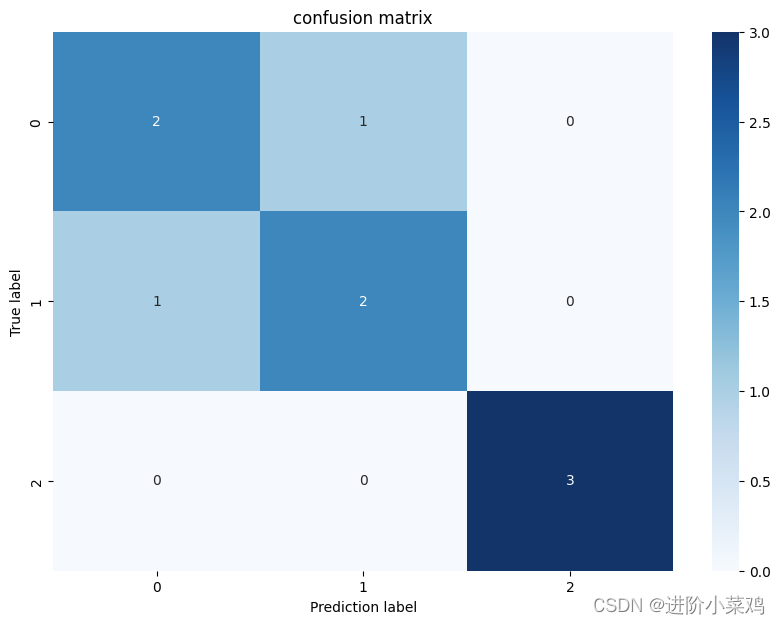
实现代码:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 假设我们有3个类别,分别是0、1和2
y_true = np.array([0, 1, 0, 2, 1, 2, 0, 1, 2])
y_pred = np.array([0, 1, 0, 2, 0, 2, 1, 1, 2])
# 将标签转换为类别
true_labels = np.unique(y_true)
pred_labels = np.unique(y_pred)
# 创建一个混淆矩阵
confusion_matrix = np.zeros((len(true_labels), len(pred_labels)))
for i in range(len(y_true)):
confusion_matrix[y_true[i], y_pred[i]] += 1
# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(confusion_matrix, annot=True, cmap='Blues')
plt.title('confusion matrix')
plt.xlabel('Prediction label')
plt.ylabel('True label')
plt.show()可以把混淆矩阵写成以下形式
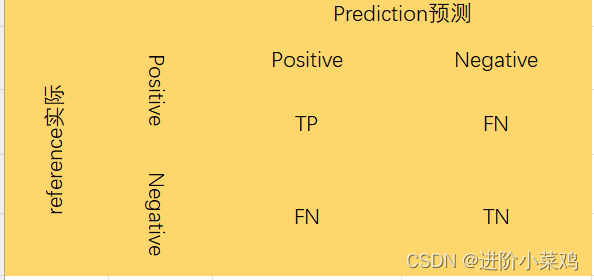
其中,
True Positive(TP,真正正类):样本的真实类别是正类,且模型正确识别为正类。
False Negative(FN,假负类):样本的真实类别是正类,但模型错误地将其识别为负类。
False Positive(FP,假正类):样本的真实类别是负类,但模型错误地将其识别为正类。
True Negative(TN,真负类):样本的真实类别是负类,且模型正确识别为负类。
精确度,召回率等指标都需要通过混淆举证进行计算
2.准确率(Accuracy)
准确率(Accuracy)是评估模型整体分类性能的指标,它表示模型预测正确的样本占所有样本的比例。准确率的计算公式为:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
其中,TP表示真正正类,即样本的真实类别是正类,且模型正确识别为正类;TN表示真负类,即样本的真实类别是负类,且模型正确识别为负类;FP表示假正类,即样本的真实类别是负类,但模型错误地将其识别为正类;FN表示假负类,即样本的真实类别是正类,但模型错误地将其识别为负类。
3.精确率(Precision)
精确度(Precision)是评估模型预测正类样本准确性的指标,它表示模型预测为正类的样本中,实际为正类的样本所占的比例。精确度的计算公式为:
Precision = TP / (TP + FP)
精确度越高,说明模型对于正类的预测能力越强,分类结果越准确。
需要注意的是,准确率和精确度之间并没有必然的联系。有时候,一个模型的准确率很高,但精确度不一定高;反之亦然。因此,在评估分类模型时,需要综合考虑准确率和精确度两个指标,以便更全面地了解模型的性能。
4.召回率(Recall)
召回率(Recall)是评估模型在识别正类样本方面的性能指标,它表示模型能够识别出的正类样本占所有实际正类样本的比例。召回率的计算公式为:
Recall = TP / (TP + FN)
其中,TP表示真正正类,即样本的真实类别是正类,且模型正确识别为正类;FN表示假负类,即样本的真实类别是正类,但模型错误地将其识别为负类。
召回率越高,说明模型能够识别出的正类样本越多,对于实际应用中的问题解决能力越强。
需要注意的是,召回率和精确度之间存在一定的关系。如果一个模型的召回率很高,但精确度很低,那么这个模型可能会将很多非正类的样本错误地识别为正类,导致误报率很高。因此,在评估分类模型时,也需要综合考虑召回率和精确度两个指标。
5.F1-score
F1-score是评估模型分类性能的综合指标,它综合考虑了准确率和精确度两个因素。F1-score的计算公式为:
F1-score = 2 * (准确率 * 精确度) / (准确率 + 精确度)
其中,准确率和精确度的计算方法如上所述。
F1-score越高,说明模型在分类过程中的综合性能越好,能够同时保证较高的准确率和精确度。
需要注意的是,F1-score的值会受到不同类别样本分布的影响。如果某个类别的样本数量很少,那么即使模型在该类别上的准确率和精确度都很高,F1-score也可能不是很高。因此,在评估分类模型时,需要综合考虑多个指标,以便更全面地了解模型的性能。
6.Fβ-score
Fβ-score是F1-score的一种扩展,它允许对查全率(Recall)和查准率(Precision)有不同的偏好。Fβ-score的计算公式为:
Fβ-score = (1 + β^2) * (精确度 * 召回率) / (β^2 * 精确度 + 召回率)
其中,β是一个参数,用于调节查全率和查准率的权重。当β=1时,Fβ-score退化为F1-score。
Fβ-score的值越高,说明模型的分类性能越好。通过调整β的值,可以改变对查全率和查准率的偏好,从而选择更适合特定应用场景的模型。
需要注意的是,Fβ-score的计算需要准确率和精确度两个指标,因此在使用Fβ-score进行模型评估时,需要同时考虑这两个指标。
7.ROC曲线
在介绍ROC之前必须介绍两个概念,TPR和FPR
- TPR(True Positive Rate):真正例率,也称为命中率、召回率。在二分类问题中,它是被模型正确分类为正例的比例。公式为:TPR = TP / (TP + FN),其中TP是真正例(True Positive),FN是假反例(False Negative)。
- FPR(False Positive Rate):假正例率,也称为误判率。在二分类问题中,它是被模型错误分类为正例的比例。公式为:FPR = FP / (FP + TN),其中FP是假正例(False Positive),TN是真正反例(True Negative)
坐标系中纵轴为 TPR(真阳率)最大值为 1,横轴为 FPR(假阳率/误判率)最大值为 1,虚线为基准线(最低标准),蓝色的曲线就是 ROC 曲线;其中 ROC 曲线距离基准线越远,则说明该模型的预测效果越好
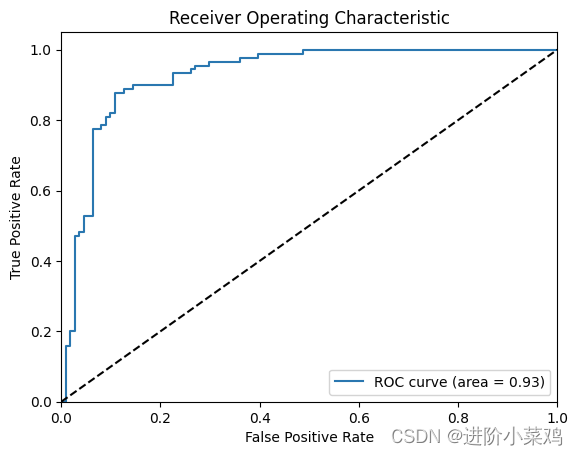
- ROC 曲线接近左上角:模型预测准确率很高
- ROC 曲线略高于基准线:模型预测准确率一般
- ROC 低于基准线:模型未达到最低标准,无法使用
AUC(Area Under Curve)是曲线下的面积,这个曲线即为ROC曲线。在深度学习中,AUC常用于分类模型的评价。
8.P-R曲线
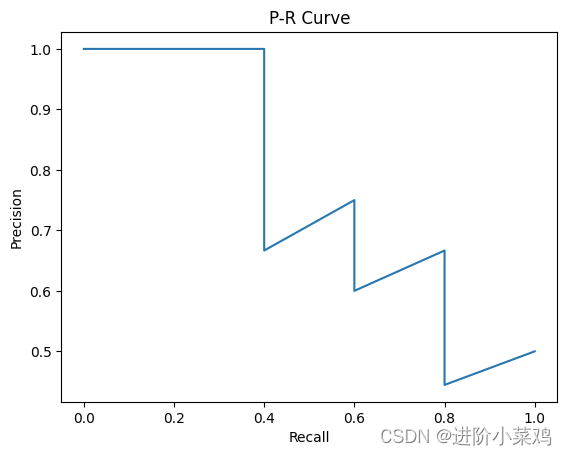
深度学习中的P-R曲线是一种用于评估分类算法性能的图形,其中横轴表示召回率(Recall),纵轴表示精确率(Precision)。
召回率是指分类器正确识别为正样本的真正例所占的比例,而精确率是指分类器正确识别为正样本的真正例与所有被分类器识别为正样本的样本的比例。 P-R曲线可以直观地显示分类算法在整体上的查准率和查全率。当对多个分类算法进行比较时,如果算法1的P-R曲线完全“外包围”算法2的P-R曲线,那么处于外侧的算法1有着更高的查准率和查全率(双高),这说明算法1比算法2有着更好的分类性能。 另外,PR曲线上存在一个平衡点(Break-Even Point,BEP),这个点是查准率和查全率相等的点。理想的情况是精确率和召回率都相当高的点,但由于两者是成反比的关系,一个升高就会导致另一个降低。
因此,比较稳妥的办法是比较P-R曲线下的面积大小(AUC大小),谁的面积大,从某种程度上就说谁的“双高”比例大,即性能更优。 总的来说,深度学习中的P-R曲线是一种用于评估分类算法性能的有效工具,可以帮助我们了解算法在不同阈值选择下的性能表现,从而选择最优的算法进行实际应用。
为什么ROC曲线和P-R曲线下面的面积都是AUC呢?有什么区别?
P-R曲线和ROC曲线都是用于评估分类模型性能的工具,但它们关注的评估指标不同,导致AUC的值也有所区别。
- ROC曲线和AUC:ROC曲线通过显示模型在不同阈值下的真假阳性率(TPR和FPR)来评估分类器的性能。AUC(Area Under the Curve)是ROC曲线下的面积,它衡量了模型的整体性能。AUC越大,表示模型的整体性能越好。
- P-R曲线和AUC:P-R曲线关注的是精确度和召回率(Precision和Recall)。AUC-PR(Area Under the Precision-Recall Curve)是P-R曲线下的面积,它衡量了模型在精确度和召回率之间的平衡。AUC-PR越大,表示模型在精确度和召回率之间的平衡越好。
因此,P-R曲线的AUC和ROC曲线的AUC的区别在于,前者关注的是精确度和召回率的平衡,后者关注的是整体性能。
希望对你有用,下一篇将继续更新关于模型评估指标,尽请期待!!!!


















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











