







文章目录
一、常用的大模型评价指标
常用的大模型评测指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1 Score)、ROUGE、Perplexity, BLEU等等,我们一一来解释这些指标是什么,适用于什么任务,以及这些指标是如何应用在评估任务中的。
F1 score
F1 score. 这个指标为基于深度学习的方法常用的评价指标,也可被用于大模型的实际效果评估,

其中, Precision 为精确率,Recall为召回率,其计算分别为:

其中,TP(True positive)为真正例,TN(True nagative)为真负例,FP(False positive)为假正例,FN(False nagative)为假负例。简单来说就是预测正确的样本数量,除以全部的样本数量。即精确率可被解释为:在被识别为正类别的样本中,识别正确的比例。召回率可被解释为:在所有正类别样本中,被正确识别为正类别的比例。
对于一般的模型,精确率和召回率往往是此消彼长。也就是说,提高精确率通常会降低召回率,反之亦然。
而F1 score则为比较综合性的指标,其脱胎于F值,其计算公式为:

其中,权重因子
a
a
a 的值取1时,即变为F1 score。
EM (Exact Match)
EM (Exact Match) 指标可被译为确切匹配或绝对匹配,是根据大模型给出的结果与标准值之间的匹配度来计算的。
取值范围:0~1,完全匹配时(生成的答案与参考答案完全相同,字符级匹配),EM值为1,不完全匹配时,EM值为0。
EM是一种比较严格的匹配,其衡量预测答案是否与标准答案完全一致。匹配的衡量方式比较呆板,可以设定一个阈值,来衡量完全匹配这个概念,比如:

其中, δ \delta δ 为大模型给出的结果与标准值之间的匹配比例, h h h 为匹配度阈值,大于等于该阈值时,即 δ ≥ h \delta \geq h δ≥h,判定为确切匹配,有 E M h = 1 EM_{h} = 1 EMh=1;小于该阈值时,即 δ < h \delta < h δ<h,不判定为确切匹配,有 E M h = 0 EM_h = 0 EMh=0。
BLEU:基于准确率,得分越高越好
BLEU(Bilingual Evaluation Understudy)指标是机器翻译质量评估中最广泛使用的自动化评测指标之一。BLEU通过比较机器翻译的结果与一个或多个参考译文之间的相似度来衡量翻译质量。
BLEU 主要是基于精确率(Precision)的。
主要思想:比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。通常取N=1~4,再加权平均。
取值范围:0~1,分数越接近1,说明翻译的质量越高。

- BLEU 需要计算译文 1-gram,2-gram,…,N-gram 的精确率,一般 N 设置为 4 即可,公式中的 Pn 指 n-gram 的精确率。
- Wn 指 n-gram 的权重,一般设为均匀权重,即对于任意 n 都有 Wn = 1/N。
- BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1。
- BLEU 的 1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。
N-gram
使用机器学习的方法生成文本的翻译之后,需要评价模型翻译的性能,一般用C表示机器翻译的译文,另外还需要提供 m 个参考的翻译S1,S2, …,Sm。评价指标就可以衡量机器翻译的C和参考翻译S1,S2, …,Sm的匹配程度。
假设机器翻译的译文C和一个参考翻译S1如下:
C: a cat is on the table
S1: there is a cat on the table
则可以计算出 1-gram,2-gram,… 的精确率:
1-gram匹配:计算 a cat is on the table 分别都在参考翻译S1中,所以p1 = 12-gram匹配:p2 (a, cat)在, (cat is) 没在, (is on) 没在, (on the) 在, (the table)在,所以p2 = 3/53-gram匹配: (a cat is)不在, (cat is on)不在, (is on the)不在, (on the table)在,所以p3 = 1/4

上面的在或者不在, 说的都是当前词组有没有在参考翻译中,直接这样子计算 Precision 会存在一些问题,例如:
C: there there there there there
S1: there is a cat on the table
这时候机器翻译的结果明显是不正确的,但是其 1-gram 的 Precision 为1,因此 BLEU 一般会使用修正的方法。给定参考译文 S 1 , S 2 , … , S m S_1, S_2 , … ,S_m S1,S2,…,Sm ,可以计算C里面 n 元组的 Precision,计算公式如下:

针对上面的例子,经过修正后 p1 = 1/5 。
惩罚因子
上面介绍了 BLEU 计算 n-gram 精确率的方法, 但是仍然存在一些问题,当机器翻译的长度比较短时,BLEU 得分也会比较高,但是这个翻译是会损失很多信息的,例如:
C: a cat
S1: there is a cat on the table
因此需要在 BLEU 分数乘上惩罚因子:

优缺点
-
优点
- 它的易于计算且速度快,特别是与人工翻译模型的输出对比;
- 它应用范围广泛,这可以让你很轻松将模型与相同任务的基准作对比。
-
缺点
- 它不考虑语义,句子结构
- 不能很好地处理形态丰富的语句(BLEU原文建议大家配备4条翻译参考译文)
- BLEU 指标偏向于较短的翻译结果(brevity penalty 没有想象中那么强)
ROUGE:基于召回率,得分越高越好
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)专注于召回率(关注有多少个参考译句中的 n- gram出现在了输出之中)而非精度(候选译文中的n-gram有没有在参考译文中出现过)。
ROUGE-N: 在 N-gram 上计算召回率ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列ROUGE-S: 允许n-gram出现跳词(skip)
取值范围:0~1,分数越接近1,说明生成文本与参考文本匹配度越高。
在真实场景中,ROUGE得分通常分布在以下区间(具体取决于任务难度和文本长度):
- 低质量生成:0 ~ 0.3
- 中等质量生成:0.3 ~ 0.6
- 高质量生成:0.6 ~ 0.9
- 接近人类水平:> 0.9(罕见,除非生成文本与参考文本高度相似)
ROUGE 用作机器翻译评价指标的初衷是这样的:在 SMT(统计机器翻译)时代,机器翻译效果稀烂,需要同时评价翻译的准确度和流畅度;等到 NMT (神经网络机器翻译)出来以后,神经网络脑补能力极强,翻译出的结果都是通顺的,但是有时候容易瞎翻译。
ROUGE的出现很大程度上是为了解决NMT的漏翻问题(低召回率)。所以 ROUGE 只适合评价 NMT,而不适用于 SMT,因为它不管候选译文流不流畅
ROUGE-N
ROUGE-N 主要统计 N-gram 上的召回率,对于 N-gram,可以计算得到 ROUGE-N 分数,计算公式如下:

公式的分母是统计在参考译文中 N-gram 的个数,而分子是统计参考译文与机器译文共有的 N-gram 个数。
C: a cat is on the table
S1: there is a cat on the table
上面例子的 ROUGE-1 和 ROUGE-2 分数如下:
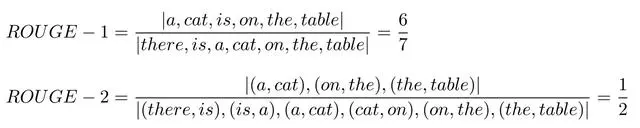
如果给定多个参考译文 S i S_i Si ,Chin-Yew Lin 也给出了一种计算方法,假设有 M 个译文 S 1 , . . . , S M S_1, ..., S_M S1,...,SM,ROUGE-N 会分别计算机器译文和这些参考译文的 ROUGE-N 分数,并取其最大值,公式如下。这个方法也可以用于 ROUGE-L,ROUGE-W 和 ROUGE-S。

ROUGE-L
ROUGE-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文C和参考译文S的最长公共子序列,计算公式如下:

公式中的 RLCS 表示召回率,而 PLCS 表示精确率,FLCS 就是 ROUGE-L。一般 beta 会设置为很大的数,因此 FLCS 几乎只考虑了 RLCS (即召回率)。注意这里 beta 大,则 F 会更加关注 R,而不是 P,可以看下面的公式。如果 beta 很大,则 PLCS 那一项可以忽略不计。

ROUGE-W
ROUGE-W 是 ROUGE-L 的改进版,考虑下面的例子,X表示参考译文,而 Y 1 , Y 2 Y_1,Y_2 Y1,Y2 表示两种机器译文。

在这个例子中,明显
Y
1
Y_1
Y1的翻译质量更高,因为
Y
1
Y_1
Y1 有更多连续匹配的翻译。但是采用 ROUGE-L 计算得到的分数确实一样的,即
R
O
U
G
E
−
L
(
X
,
Y
1
)
=
R
O
U
G
E
−
L
(
X
,
Y
2
)
ROUGE-L(X, Y_1)=ROUGE-L(X, Y_2)
ROUGE−L(X,Y1)=ROUGE−L(X,Y2)。因此作者提出了一种加权最长公共子序列方法 (WLCS),给连续翻译正确的更高的分数,具体做法可以阅读原论文《ROUGE: A Package for Automatic Evaluation of Summaries》。
ROUGE-S
ROUGE-S 也是对 N-gram 进行统计,但是其采用的 N-gram 允许"跳词 (Skip)",即单词不需要连续出现。例如句子 “I have a cat” 的 Skip 2-gram 包括 (I, have),(I, a),(I, cat),(have, a),(have, cat),(a, cat)。
PPL (Perplexity)
参考博客:语言模型的困惑度PPL
(1)PPL定义
PPL的全称为Perplexity,中文名为困惑度,是衡量语言模型好坏的一个常用指标。
语言模型(language model)是用来预测句子中的next word的概率分布(probability distribution),并计算一个句子的概率。一个好的语言模型,应该给well-written 的句子更高的生成概率,阅读这些句子不应该让人感到困惑。
基本定义:PPL是语言模型对测试文本中每个token预测概率的几何平均数的倒数。
取值范围: [ 1 , + ∞ ) [1, +\infty) [1,+∞),PPL越小(困惑度越低),则模型的性能越好。反之,PPL的值越大(困惑度越高),模型的性能越差。

其中:
- N N N是测试样本中的总token数。
- P ( w i ) P(w_i) P(wi)是模型对测试样本中第 i i i 个token的预测概率。
也可以等价地写为下面的形式:

(2) PPL性质
- 对于高质量数据集,如果模型预测的PPL越小(困惑度越低),则模型的性能越好。对于低质量数据集,则未必。
- 如果模型能够完美预测每个token,则PPL为1。
- 如果模型预测样本中每个token的概率无限接近于0,则PPL为无穷大。
- 如果模型预测的为均匀分布,则PPL等于词表的大小。
- 同一模型和参数配置下,文本长度对PPL的影响。在理论上,PPL是归一化的指标,通常以每个token为单位计算,因此文本长度本身不应直接影响PPL的大小。然而,在实践中,文本长度可能间接影响PPL,原因包括:
- 文本内容的多样性:较长的文本可能包含更多复杂的句式和稀有词汇,增加模型预测的难度,从而提高PPL。
- 上下文信息的利用:对于一些模型,较长的上下文可以提供更多信息,有助于模型更准确地预测下一个词,可能降低PPL。
- 总体而言,在相同模型和参数配置下,文本长度对PPL的影响通常较小,但具体影响还取决于文本的内容和结构。
- 受词汇表大小和分词方式影响:不同的分词方法和词汇表规模会影响PPL的计算。较大的词汇表可能增加模型的PPL,因为稀有词的预测更具挑战性。
二、不同应用场景下的评估指标
参考:大模型评估指标
不同的行业对LLM的要求不相一致,因此对LLM的评价指标也会有所差别。在大模型行业落地过程中,根据应用场景定制评价指标体系对最终应用效果至关重要。例如:在医疗领域,关乎人命,大模型应用在疾病、用药、诊断等方面准确性的要求会更高;在金融方面,大模型在逻辑推理、计算等方面的能力就很重要;而在“闲聊”应用场景,就相对的专业性、严谨性没有那么严格。
机器翻译评估指标
- EM:确切匹配,根据大模型给出的结果与标准值之间的匹配度来计算的。完全匹配时,EM值为1,不完全匹配时,EM值为0
- BLEU:BLEU评分是一种基于精度的衡量标准,范围从0到1。值越接近1,预测越好。
- ROUGE:ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一套用于评估自然语言处理中自动摘要和机器翻译软件的度量标准和附带的软件包。
文档摘要评估指标
(1)基于重叠的度量
-
BLEU:BLEU评分是一种基于精度的衡量标准,范围从0到1。值越接近1,预测越好。
-
ROUGE:ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一套用于评估自然语言处理中自动摘要和机器翻译软件的度量标准和附带的软件包。
-
ROUGE-N:测量候选文本和参考文本之间的n-gram(n个单词的连续序列)的重叠。它根据n-gram重叠计算精度,召回率和F1分数。
-
ROUGE-L:测量候选文本和参考文本之间的最长公共子序列(LCS)。它根据LCS的长度计算精确率、召回率和F1分数。
-
METEOR:一种机器翻译评估的自动度量,其基于机器生成的翻译和人类生成的参考翻译之间的单字匹配的广义概念。
(2)基于语义相似性的度量
- BERTScore:利用BERT中预先训练的上下文嵌入,并通过“余弦相似度”匹配候选句子和参考句子中的单词。
- MoverScore:基于上下文向量和距离的文本生成评估。
问答样本评估指标
QA评估指标主要用于衡量基于LLM的应用系统在解决用户问答方面的有效性。
- QAEval:基于问答的度量,用于估计摘要的内容质量。
- QAFactEval:基于QA的事实一致性评价。
- QuestEval:一种NLG指标,用于评估两个不同的输入是否包含相同的信息。它可以处理多模式和多语言输入。
实体识别指标
实体识别(NER)是对文本中特定实体进行识别和分类的一种任务。评估NER,对于确保信息的准确提取,对需要精确实体识别的应用系统非常重要。
-
分类度量指标:实体级别或模型级别的分类指标(精度、召回率、准确性、F1分数等)。
-
解释评估指标:主要思想是根据实体长度、标签一致性、实体密度、文本的长度等属性将数据划分为实体的桶,然后在每个桶上分别评估模型。
文本转SQL
通过大模型实现文本转SQL,在一些对话式的数据分析、可视化、智能报表、智能仪表盘等场景中经常被用到,文本转SQL是否有效性取决于LLM能否熟练地概括各种自然语言问题,并灵活地构建新的SQL查询语句。想要确保系统不仅在熟悉的场景中表现良好,并且在面对不同的语言表达风格的输入、不熟悉的数据库结构和创新的查询格式时还依然表现出准确性。需要全面评估文本到SQL系统方面能否发挥作用。
-
Exact-set-match accuracy (EM):EM根据其相应的基本事实SQL查询来评估预测中的每个子句。然而,一个限制是,存在许多不同的方式来表达SQL查询,以达到相同的目的。
-
Execution Accuracy (EX):EX根据执行结果评估生成的答案的正确性。
-
VES (Valid Efficiency Score):VES是一个用于测量效率以及所提供SQL查询的通常执行正确性的度量标准。
RAG系统
RAG(Retrieval-Augmented Generation)是一种自然语言处理(NLP)模型架构,它结合了检索和生成方法的元素。通过将信息检索技术与文本生成功能相结合来增强大语言模型的性能。评估RAG检索相关信息、结合上下文、确保流畅性、避免偏见对提高满足用户满意度至关重要。有助于识别系统问题,指导改进检索和生成模块。
-
Faithfulness:事实一致性,根据给定的上下文测量生成的答案与事实的一致性。
-
Answer relevance:答案相关性,重点评估生成的答案与给定提示的相关性。
-
Context precision:上下文精确度,评估上下文中存在的所有与实况相关的项目是否排名更高。
-
Context relevancy:语境关联,测量检索到的上下文的相关性,根据问题和上下文计算。
-
Context Recall:上下文召回率,测量检索到的上下文与样本答案(被视为基本事实)的一致程度。
-
Answer semantic similarity:答案语义相似度,评估生成的答案和基础事实之间的语义相似性。
-
Answer correctness:答案正确性,衡量生成的答案与地面实况相比的准确性。

















 3685
3685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









