







 本文介绍了强化学习的基本概念,强调了策略网络(Policy Network)在自动化控制中的作用。通过AlphaGo的例子展示了深度强化学习如何在围棋等复杂环境中学习最佳策略。Policy Network直接预测环境状态下的行动,结合Discounted Future Reward进行训练,以实现长期利益的最大化。文章还提及了使用TensorFlow实现策略网络解决CartPole问题的案例。
本文介绍了强化学习的基本概念,强调了策略网络(Policy Network)在自动化控制中的作用。通过AlphaGo的例子展示了深度强化学习如何在围棋等复杂环境中学习最佳策略。Policy Network直接预测环境状态下的行动,结合Discounted Future Reward进行训练,以实现长期利益的最大化。文章还提及了使用TensorFlow实现策略网络解决CartPole问题的案例。
浅析强化学习
强化学习(Reinforcement Learning)是机器学习的一个重要分支,主要用来解决连续决策的问题。强化学习可以在复杂、不确定的环境中学习如何实现我们设定的目标。强化学习的应用场景非常广,几乎包括了所有需要做一系列决策的问题,比如控制机器人的电机让它执行特定任务,给商品定价或者库存管理,玩视频或棋牌游戏等。强化学习也可以应用到有序列输出的问题中,因为它可以针对一系列变化的环境状态,输出一系列对应的行动。举个简单的例子,围棋(乃至全部棋牌类游戏)可以归结为一个强化学习问题,我们需要学习在各种局势下如何走出最好的招法。
一个强化学习问题包含三个主要概念,即环境状态(Environment State)、行动(Action)和奖励(Reward),而强化学习的目标是获得最多的累计奖励。在围棋中,环境状态就是已经下出来的某个局势,行动是在某个位置落子,奖励则是当前这步棋获得的目数(围棋中存在不确定性,在结束对弈后计算的目数是准确的,棋局中获得的目数是估计的),而最终目标就是在结束对弈时总目数超过对手,赢得胜利。我们要让强化学习模型根据环境状态、行动和奖励,学习出最佳策略,并以最终结果为目标,不能只看某个行动当下带来的利益(比如围棋中通过某一手棋获得的实地),还要看到这个行动未来能带来的价值(比如围棋中外势可以带来的潜在价值)。我们回顾一下,AutoEncoder属于无监督学习,而MLP、CNN和RNN都属于监督学习,但强化学习跟这两种都不同。它不像无监督学习那样完全没有学习目标,也不像监督学习那样有非常明确的目标(即label),强化学习的目标一般是变化的、不明确的,甚至可能不存在绝对正确的标签。
强化学习已经有几十年的历史,但是直到最近几年深度学习技术的突破,强化学习才有了比较大的进展。Google DeepMind结合强化学习与深度学习,提出DQN(Deep Q-Network,深度Q网络),它可以自动玩Atari 2600系列的游戏,并取得了超过人类的水平。而DeepMind的AlphaGo结合了策略网络(Policy Network)、估值网络(Value Network,也即DQN)与蒙特卡洛搜索树(Monte Carlo Tree Search),实现了具有超高水平的围棋对战程序,并战胜了世界冠军李世石。
DeepMind使用的这些深度强化学习模型(Deep Reinforcement Learning,DRL)本质上也是神经网络,主要分为策略网络和估值网络两种。深度强化学习模型对环境没有特别强的限制,可以很好地推广到其他环境,因此对强化学习的研究和发展具有非常重大的意义。下面我们来看看深度强化学习的一些实际应用例子。
我们也可以使用深度强化学习自动玩游戏,如图1所示,用DQN可学习自动玩Flappy Bird。DQN前几层通常也是卷积层,因此具有了对游戏图像像素(raw pixels)直接进行学习的能力。前几层卷积可理解和识别游戏图像中的物体,后层的神经网络则对Action的期望价值进行学习,结合这两个部分,可以得到能根据游戏像素自动玩Flappy Bird的强化学习策略。而且,不仅是这类简单的游戏,连非常复杂的包含大量战术策略的《星际争霸2》也可以被深度强化学习模型掌握。目前,DeepMind就在探索如何通过深度强化学习训练一个可以战胜《星际争霸2》世界冠军的人工智能,这之后的进展让我们拭目以待。

深度强化学习最具有代表性的一个里程碑自然是AlphaGo。在2016年,Google DeepMind的AlphaGo以4:1的比分战胜了人类的世界冠军李世石,如图2所示。围棋可以说是棋类游戏中最为复杂的,19×19的棋盘给它带来了3361种状态,除去其中非法的违反游戏规则的状态,计算机也是无法通过像深蓝那样的暴力搜索来战胜人类的,要在围棋这个项目上战胜人类,就必须给计算机抽象思维的能力,而AlphaGo做到了这一点。

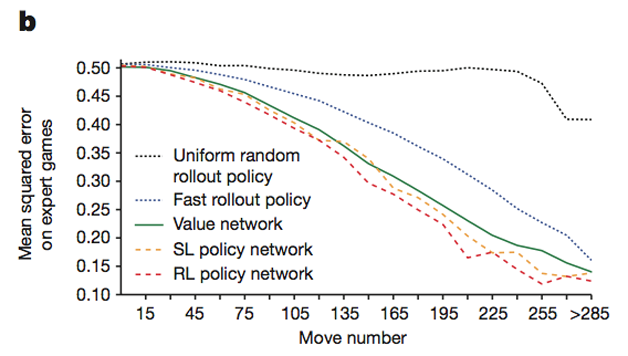
在AlphaGo中使用了快速走子(Fast Rollout)、策略网络、估值网络和蒙特卡洛搜索树等技术。图3所示为AlphaGo的几种技术单独使用时的表现,横坐标为步数,纵坐标为预测的误差(可以理解为误差越低模型效果越好),其中简单的快速走子策略虽然效果比较一般,但是已经远胜随机策略。估值网络和策略网络的效果都非常好,相对来说,策略网络的性能更胜一筹。AlphaGo融合了所有这些策略,取得了比单一策略更好的性能,在实战中表现出了惊人的水平。
Policy-Based(或者Policy Gradients)和Value-Based(或者Q-Learning)是强化学习中最重要的两类方法,其主要区别在于Policy-Based的方法直接预测在某个环境状态下应该采取的Action,而Value Based的方法则预测某个环境状态下所有Action的期望价值(Q值),之后可以通过选择Q值最高的Action执行策略。这两种方法的出发点和训练方式都有不同,一般来说,Value Based方法适合仅有少量离散取值的Action的环境,而Policy-Based方法则更通用,适合Action种类非常多或者有连续取值的Action的环境。而结合深度学习后,Policy-Based的方法就成了Policy Network,而Value-Based的方法则成了Value Network。
图4所示为AlphaGo中的策略网络预测出的当前局势下应该采取的Action,图中标注的数值为策略网络输出的应该执行某个Action的概率,即我们应该在某个位置落子的概率。

图5所示为AlphaGo中估值网络预测出的当前局势下每个Action的期望价值。估值网络不直接输出策略,而是输出Action对应的Q值,即在某个位置落子可以获得的期望价值。随后,我们可以直接选择期望价值最大的位置落子,或者选择其他位置进行探索。

在强化学习中,我们也可以建立额外的model对环境状态的变化进行预测。普通的强化学习直接根据环境状态预测出行动策略,或行动的期望价值。如果根据环境状态和采取的行动预测接下来的环境状态,并利用这个信息训练强化学习模型,那就是model-based RL。对于复杂的环境状态,比如视频游戏的图像像素,要预测这么大量且复杂的环境信息是非常困难的。如果环境状态是数量不大的一些离散值(m),并且可采取的行动也是数量较小的一些离散值(n),那么环境model只是一个简单的m×n的转换矩阵。对于一个普通的视频游戏环境,假设图像像素为64×64×3,可选行动有18种,那么我们光存储这个转换矩阵就需要大的难以想象的内存空间(25664×64×3×18)。对于更复杂的环境,我们就更难使用model预测接下来的环境状态。而model-free类型的强化学习则不需要对环境状态进行任何预测,也不考虑行动将如何影响环境。model-free RL直接对策略或者Action的期望价值进行预测,因此计算效率非常高。当然,如果有一个良好的model可以高效、准确地对环境进行预测,会对训练RL带来益处;但是一个不那么精准的model反而会严重干扰RL的训练。因此,对大多数复杂环境,我们主要使用model-free RL,同时供给更多的样本给RL训练,用来弥补没有model预测环境状态的问题。
使用策略网络(Policy Network)实现自动化控制
前面提到了强化学习中非常重要的3个要素是Environment State、Action和Reward。在环境中,强化学习模型的载体是Agent,它负责执行模型给出的行动。环境是Agent无法控制的,但是可以进行观察;根据观察的结果,模型给出行动,交由Agent来执行;而Reward是在某个环境状态下执行了某个Action而获得的,是模型要争取的目标。在很多任务中,Reward是延迟获取的(Delayed),即某个Action除了可以即时获得Reward,也可能跟未来获得的Reward有很大关系。
所谓策略网络,即建立一个神经网络模型,它可以通过观察环境状态,直接预测出目前最应该执行的策略(Policy),执行这个策略可以获得最大的期望收益(包括现在的和未来的Reward)。与普通的监督学习不同,在强化学习中,可能没有绝对正确的学习目标,样本的feature不再和label一一对应。对某一个特定的环境状态,我们并不知道它对应的最好的Action是什么,只知道当前Action获得的Reward还有试验后获得的未来的Reward。我们需要让强化学习模型通过试验样本自己学习什么才是某个环境
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









