







论文标题:PointPainting: Sequential Fusion for 3D Object Detection
nuTommy出品,mit的自动驾驶公司。
发表在cvpr2020
本文是个fusion的目标检测,然而他实际上只是利用了来自camera的label或者score信息。
如题目所言他是一个sequential 的网络。网络主要分为两个part。
老规矩,上图!

思路很简单,不过效果不错,而且是一个可以通用的模块。
文章分为两个部分,首先是semantic segmentation。
这里作者说用的网络是deeplab++,主要是对于camera捕捉到的image进行语义分割。输出的是每个pixel的label或者score,作者后面对于label或者score都进行了实验,发现采用label能达到更好的3d目标检测效果。
随后作者进行point 投影,主要是将点云投影到pixel上。这里便涉及点云到camera的矩阵变换,作者在本文中做了两个数据集的实验。kitti上可以直接进行矩阵变换,而Nusence还需要时间戳的对齐。
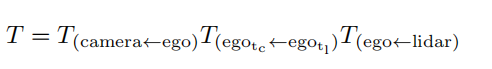

对于得到的label进行point的concat拼接。得到新编码的point。
随后便把他们送进lidar detector里面。

我的思考:
本文思路还是很简单清晰的,用最简单的方法达到了ap的提升。
看文章的时候我在想从中学习写论文的方法。如果是我写这篇文章我会怎么做实验?
作者的实验做的很漂亮,首先分析了这个模块的兼容性,带来的ap提升,不同数据集上的表现效果,对于不同class的物体的检测效果,同时与当前ap最高的检测器对比。
ablation实验作者分析了前面的语义分割模块的效果对于整个网络架构的影响,考虑了score还是label作为特征融入网络的影响,最后对于是否对齐时间戳这个问题进行了一定的探讨,发现在实际使用了首先要进行语义分割,这段时间不对齐对于3d检测效果的影响是很小的。
一篇精炼、详实的文章!















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









