







论文标题:Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds
cvpr2022
transformer用在点云上面逐渐成为一种新的趋势 本文就是用transformer做3d目标检测。
作者首先分析了现有的一些方法 直接在点云上逐个点用transformer是行不通的 因为实在是太大了 而现有的一些方法 例如将点云group后做trans 又难免遗漏一些点 将点云转化为voxel 进行3d卷积的话 相对于transformer来说 感受野是很小的。那么 有没有一种方法能够既享受trans带来的全局特征 又能减小一下计算量呢 这篇文章就是在这样的背景下写出来的:
老规矩 上图!
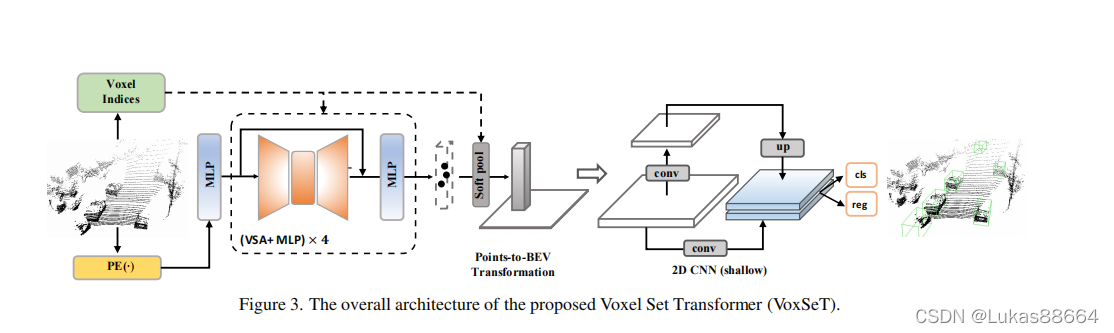
文章是在point level上做的 可以看到 作者提出来比较新的点就是文章中的vsa层,那我们便来仔细看看这个结构:
这个结构是对于所有的点云进行的 首先作者引入了set transformer 的概念,建议大家看这篇文章前可以稍微浏览一下之前nips上的一篇文章:《Set transformer: A framework for attention-based permutation-invariant neural networks》
主要思路类似于linformer 大概就是认为自注意力矩阵是一个低秩的模块 因此对于自注意力模块 我们可以采用两个cross attetion的操作来进行降秩处理,再将降秩后的attention matrix与我们的输入矩阵进行相乘。
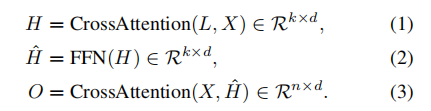
而对于所有的点云 我们便从此出发,首先对于点云映射到key 和 value 我们进行一个线性映射的操作 随后计算key和一个降秩矩阵L(K*D)之间的cross attention 再与value相乘 经过softmax计算value的权重后与value进行相乘 得到hidden feature 这个hidden feature是对于每一个点而言的 我们将它们根据voxel的划分分配到每一个voxel中 组成每一个voxel的feature深度:
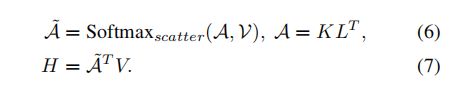
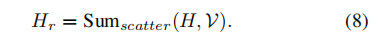
对组成的voxel图 我们进行深度卷积 提取不同voxel间的特征 这个卷积进行了两次 最后再进行broadcast 将得到的feature投影回原来的point 对于新得到的feature 我们将它们做为key 和 value 进行前面类似的与低秩矩阵的crossattention操作后 得到新的point feature
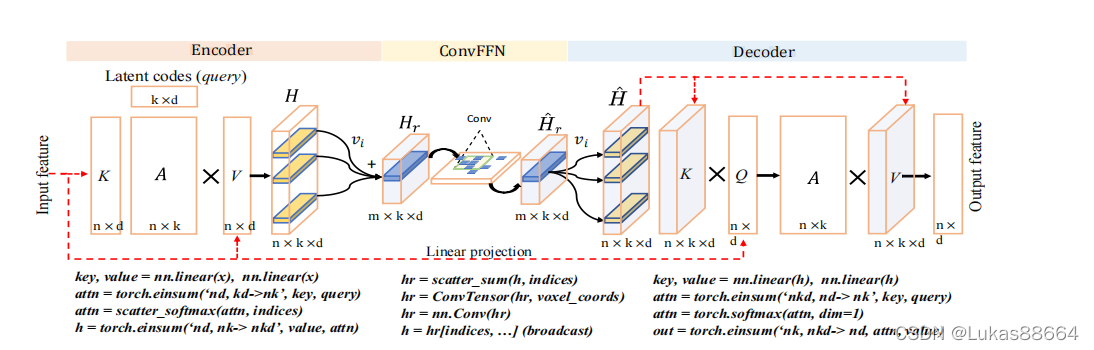
我们可以看到 前面的encoder实际上就是vfe的操作
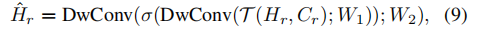
上述模块 即为全文的重点 vsa
随后对该模块进行叠加 不断提取pointlevel的全局特征 最后利用 soft pool 将特征投影到 bev
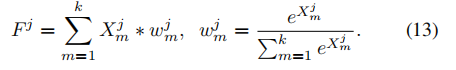
X是该bev voxel内的点的特征
最后进行2d卷积 输出检测的head
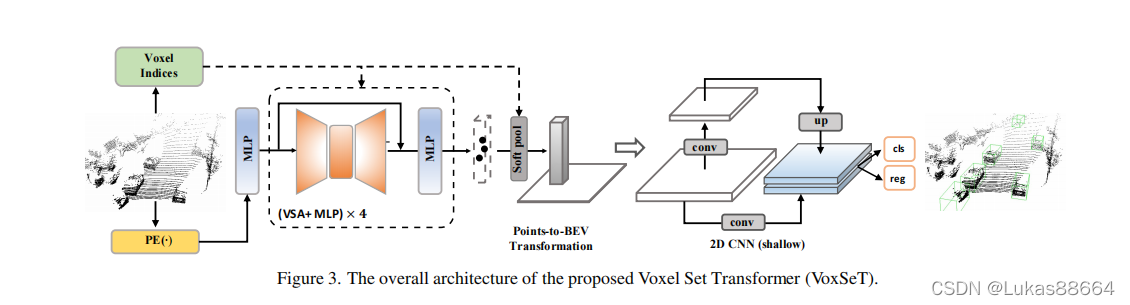
作者认为该网络还可以扩展到二阶段 第二阶段 作者利用了cvpr2021的Lidar rcnn作为refinement net
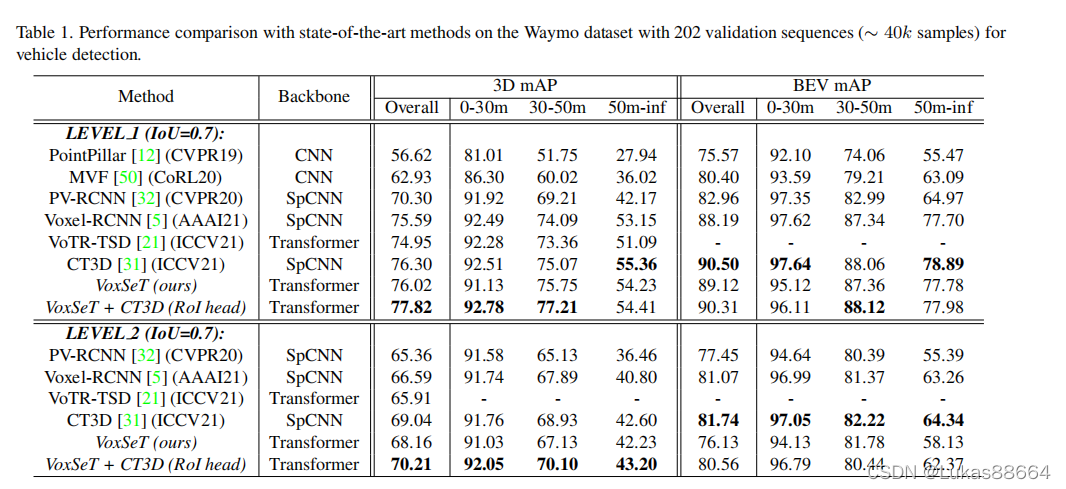
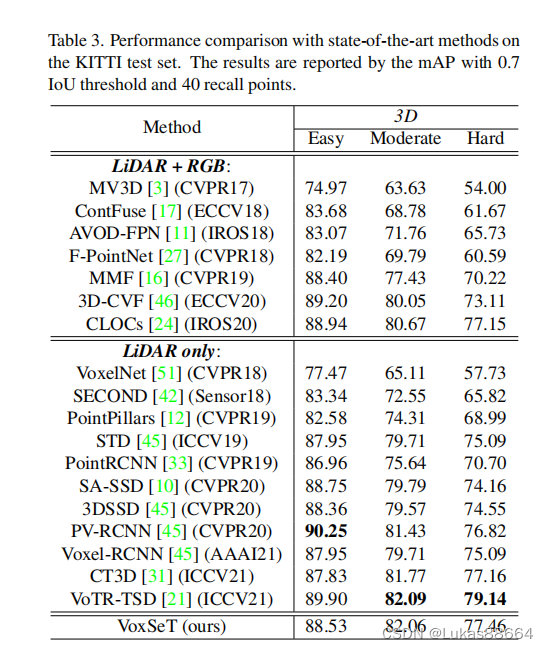
ablation实验做了替换ffn和不同的latent codes 及在pointrcnn上替换Sa为transformer 来看看效果吧:
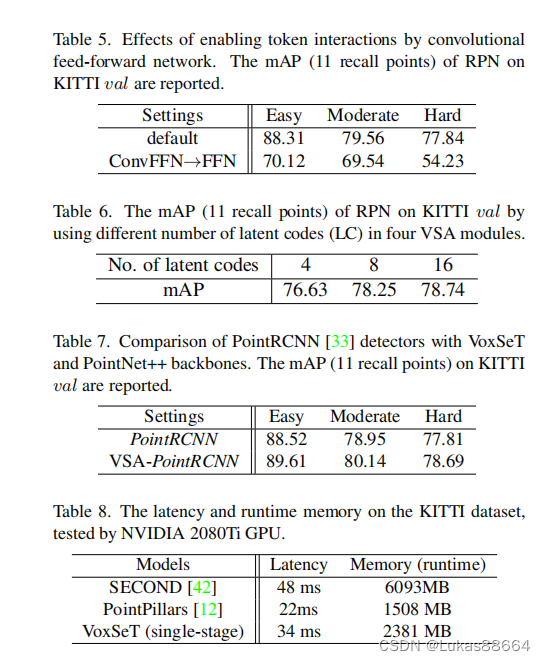
可以看到 很重要的一点是 进行voxel间的conv能很大的提升ap 相比原来的sa transformer也确实能更好地提取局部特征。

















 2157
2157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









