








✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。
🍎个人主页:Java Fans的博客
🍊个人信条:不迁怒,不贰过。小知识,大智慧。
💞当前专栏:机器学习分享专栏
✨特色专栏:国学周更-心性养成之路
🥭本文内容:自编码器(Autoencoder)详解
文章目录
引言
在当今数据驱动的时代,如何有效地处理和分析海量数据成为了一个重要的研究课题。自编码器(Autoencoder)作为一种无监督学习的神经网络模型,因其在特征学习、数据降维和重构方面的优越性能而备受关注。自编码器通过将输入数据压缩到低维潜在空间,再将其重构为原始数据,能够有效捕捉数据的内在结构和特征。这一过程不仅有助于提高数据处理的效率,还为后续的机器学习任务提供了更为精炼的特征表示。
本文将深入探讨自编码器的基本原理、数学模型、实现步骤以及其在各个领域的应用场景。通过对自编码器的全面分析,旨在为研究人员和工程师提供一个清晰的理解框架,帮助他们在实际应用中更好地利用这一强大的工具。无论是在图像处理、异常检测还是生成模型等领域,自编码器都展现出了广泛的应用潜力。
一、基本原理
自编码器(Autoencoder)是一种特殊类型的神经网络,旨在学习输入数据的有效表示。其基本原理可以从以下几个方面进行详细阐述:
1. 网络结构
自编码器通常由三个主要部分组成:
- 输入层:接收原始数据,数据可以是图像、文本或其他类型的特征向量。
- 编码器:将输入数据映射到一个低维的潜在空间(latent space)。编码器通常由一系列神经网络层构成,逐渐减少神经元的数量,从而实现数据的压缩。
- 解码器:将潜在空间的表示映射回原始数据空间。解码器的结构通常与编码器相反,逐渐增加神经元的数量,以重构出与输入数据相似的输出。
2. 数据压缩与重构
自编码器的核心思想是通过学习将输入数据压缩为低维表示,并能够从中重构出原始数据。这个过程可以分为两个阶段:
-
编码阶段:在这一阶段,输入数据通过编码器进行处理,生成一个低维的潜在表示。这个表示捕捉了输入数据的主要特征,去除了冗余信息。
-
解码阶段:在这一阶段,潜在表示通过解码器进行处理,生成重构数据。自编码器的目标是使重构数据尽可能接近原始输入数据。
3. 损失函数
自编码器的训练目标是最小化输入数据与重构数据之间的差异。常用的损失函数包括:
-
均方误差(MSE):计算原始输入与重构输出之间的平方差,公式为:
L ( x , x ^ ) = ∣ ∣ x − x ^ ∣ ∣ 2 L(x, \hat{x}) = ||x - \hat{x}||^2 L(x,x^)=∣∣x−x^∣∣2
其中, x x x 是原始输入, x ^ \hat{x} x^ 是重构输出。 -
交叉熵损失:在处理分类问题时,交叉熵损失可以用于衡量重构输出与原始输入之间的相似度。
4. 无监督学习
自编码器是一种无监督学习方法,这意味着它不依赖于标签数据进行训练。通过输入未标记的数据,自编码器能够自动学习数据的结构和特征。这一特性使得自编码器在处理大量未标记数据时具有很大的优势。
5. 激活函数
在编码器和解码器的每一层,通常会使用激活函数来引入非线性特性。常见的激活函数包括:
- ReLU(Rectified Linear Unit):在输入大于零时输出该值,否则输出零,能够有效缓解梯度消失问题。
- Sigmoid:将输出限制在0到1之间,适用于二元分类问题。
- Tanh:将输出限制在-1到1之间,通常在隐藏层中使用。
6. 变种与扩展
自编码器有多种变种和扩展,常见的包括:
- 稀疏自编码器:通过引入稀疏性约束,鼓励网络学习到更具代表性的特征。
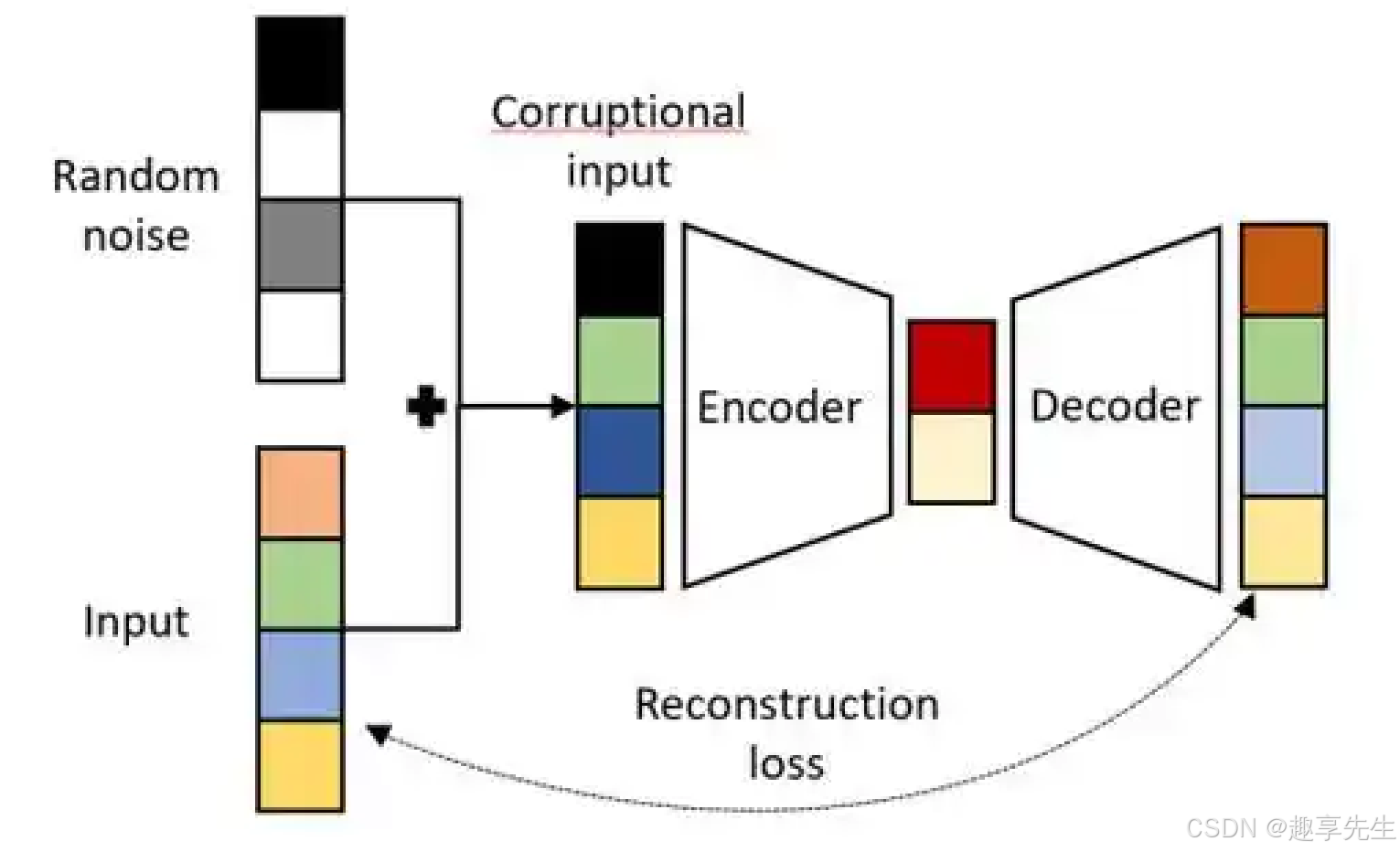
- 去噪自编码器:在输入数据中添加噪声,训练网络从噪声中恢复出干净的输入,增强模型的鲁棒性。
- 变分自编码器(VAE):结合了生成模型的思想,能够生成新的样本,广泛应用于图像生成和数据增强。
7. 应用价值
自编码器的基本原理使其在多个领域具有广泛的应用价值,包括数据降维、特征提取、图像去噪、异常检测等。通过有效地学习数据的潜在表示,自编码器能够为后续的机器学习任务提供更为精炼和有意义的特征。
综上所述,自编码器的基本原理围绕着数据的压缩与重构展开,通过无监督学习的方式,自动提取数据的内在特征。这一过程不仅提高了数据处理的效率,也为后续的分析和建模提供了坚实的基础。
二、数学模型
自编码器的数学模型主要涉及输入数据的编码、解码过程以及损失函数的定义。以下是对自编码器数学模型的详细阐述:
1. 输入与输出
设输入数据为 x ∈ R n x \in \mathbb{R}^n x∈Rn,其中 n n n 是输入特征的维度。自编码器的目标是将输入数据 x x x 通过编码器映射到一个低维的潜在表示 z ∈ R m z \in \mathbb{R}^m z∈Rm,其中 m < n m < n m<n。
2. 编码过程
编码器的作用是将输入数据 x x x 映射到潜在空间 z z z。这个过程可以用以下公式表示:
z = f ( x ) = σ ( W e x + b e ) z = f(x) = \sigma(W_{e}x + b_{e}) z=f(x)=σ(Wex+be)
- W e ∈ R m × n W_{e} \in \mathbb{R}^{m \times n} We∈Rm×n:编码器的权重矩阵,负责将输入特征映射到潜在空间。
- b e ∈ R m b_{e} \in \mathbb{R}^m be∈Rm:编码器的偏置项,增加模型的灵活性。
- σ \sigma σ:激活函数,常用的有ReLU、Sigmoid或Tanh等。
- z z z:潜在表示,捕捉了输入数据的主要特征。
3. 解码过程
解码器的作用是将潜在表示 z z z 映射回原始数据空间 x ^ \hat{x} x^。这个过程可以用以下公式表示:
x ^ = g ( z ) = σ ( W d z + b d ) \hat{x} = g(z) = \sigma(W_{d}z + b_{d}) x^=g(z)=σ(Wdz+bd)
- W d ∈ R n × m W_{d} \in \mathbb{R}^{n \times m} Wd∈Rn×m:解码器的权重矩阵,负责将潜在表示映射回原始特征空间。
- b d ∈ R n b_{d} \in \mathbb{R}^n bd∈Rn:解码器的偏置项。
- x ^ \hat{x} x^:重构输出,期望与原始输入 x x x 尽可能接近。
4. 损失函数
自编码器的训练目标是最小化输入数据 x x x 与重构数据 x ^ \hat{x} x^ 之间的差异。常用的损失函数包括:
-
均方误差(MSE):
L ( x , x ^ ) = ∣ ∣ x − x ^ ∣ ∣ 2 = ∑ i = 1 n ( x i − x ^ i ) 2 L(x, \hat{x}) = ||x - \hat{x}||^2 = \sum_{i=1}^{n} (x_i - \hat{x}_i)^2 L(x,x^)=∣∣x−x^∣∣2=i=1∑n(xi−x^i)2
其中, x i x_i xi 和 x ^ i \hat{x}_i x^i 分别是输入和重构输出的第 i i i 个特征。
-
交叉熵损失:在处理分类问题时,交叉熵损失可以用于衡量重构输出与原始输入之间的相似度,特别是在输出为概率分布时。
5. 训练过程
自编码器的训练过程通常采用反向传播算法,通过最小化损失函数来更新权重和偏置。具体步骤如下:
- 前向传播:计算潜在表示 z z z 和重构输出 x ^ \hat{x} x^。
- 计算损失:根据损失函数计算输入与重构输出之间的差异。
- 反向传播:通过链式法则计算损失对权重和偏置的梯度。
- 更新参数:使用优化算法(如Adam或SGD)更新权重和偏置,以最小化损失。
6. 激活函数的选择
激活函数在自编码器中起着至关重要的作用。不同的激活函数会影响模型的非线性特性和学习能力。常见的激活函数包括:
-
ReLU(Rectified Linear Unit):
σ ( x ) = max ( 0 , x ) \sigma(x) = \max(0, x) σ(x)=max(0,x)
适用于隐藏层,能够有效缓解梯度消失问题。
-
Sigmoid:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
输出范围在0到1之间,适用于二元分类问题。
-
Tanh:
σ ( x ) = e x − e − x e x + e − x \sigma(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} σ(x)=ex+e−xex−e−x
输出范围在-1到1之间,通常在隐藏层中使用。
7. 变种与扩展
自编码器的基本数学模型可以扩展为多种变种,以适应不同的应用场景:
-
稀疏自编码器:通过引入稀疏性约束,鼓励网络学习到更具代表性的特征,通常在损失函数中添加稀疏性惩罚项。
-
去噪自编码器:在输入数据中添加噪声,训练网络从噪声中恢复出干净的输入,增强模型的鲁棒性。
-
变分自编码器(VAE):结合了生成模型的思想,通过引入潜在变量的分布,使得模型能够生成新的样本。
三、实现步骤
实现自编码器的过程可以分为多个步骤,从数据准备到模型训练和评估。以下是自编码器实现的详细步骤:
1. 数据准备
- 数据收集:获取需要处理的数据集,数据可以是图像、文本、时间序列等。
- 数据预处理:
- 清洗数据:去除缺失值、异常值和重复数据。
- 标准化/归一化:将数据缩放到相同的范围,通常使用标准化(均值为0,方差为1)或归一化(将数据缩放到0到1之间)。
- 分割数据集:将数据集分为训练集、验证集和测试集,通常的比例为70%训练集,15%验证集,15%测试集。
2. 构建模型
-
选择框架:选择适合的深度学习框架,如TensorFlow、Keras或PyTorch。
-
定义模型结构:
- 编码器:定义编码器的层数、每层的神经元数量和激活函数。例如,可以使用全连接层(Dense Layer)或卷积层(Conv Layer)来构建编码器。
- 解码器:定义解码器的结构,通常与编码器对称。
例如,在Keras中定义一个简单的自编码器模型:
from keras.models import Model from keras.layers import Input, Dense input_dim = 784 # 输入维度(例如28x28图像展平) encoding_dim = 32 # 潜在空间维度 # 输入层 input_layer = Input(shape=(input_dim,)) # 编码层 encoded = Dense(encoding_dim, activation='relu')(input_layer) # 解码层 decoded = Dense(input_dim, activation='sigmoid')(encoded) # 构建自编码器模型 autoencoder = Model(input_layer, decoded)
3. 编译模型
-
选择损失函数:根据任务选择合适的损失函数,通常使用均方误差(MSE)或交叉熵损失。
-
选择优化器:选择优化算法,如Adam、SGD等,设置学习率等超参数。
例如,在Keras中编译模型:
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
4. 训练模型
-
设置训练参数:定义批次大小(batch size)、训练轮数(epochs)等超参数。
-
训练模型:使用训练集进行模型训练,并在验证集上监控模型性能,防止过拟合。
例如,在Keras中训练模型:
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, validation_data=(x_val, x_val))
5. 评估模型
-
测试模型:使用测试集评估模型的重构能力,计算损失值。
例如,在Keras中评估模型:
loss = autoencoder.evaluate(x_test, x_test) print(f'Test Loss: {loss}') -
可视化结果:可视化重构结果与原始输入的对比,帮助理解模型的表现。可以使用Matplotlib等库进行可视化。
6. 应用模型
-
特征提取:使用训练好的编码器提取输入数据的潜在表示,可以用于后续的机器学习任务。
例如,在Keras中提取特征:
encoder = Model(input_layer, encoded) encoded_data = encoder.predict(x_test) -
异常检测:通过计算重构误差,识别异常数据点。通常设定一个阈值,当重构误差超过该阈值时,标记为异常。
7. 调整与优化
- 超参数调整:根据模型的表现,调整超参数,如学习率、批次大小、层数和神经元数量等,以提高模型性能。
- 正则化:引入正则化技术(如L1、L2正则化或Dropout)以防止过拟合。
- 尝试变种:根据具体应用场景,尝试不同类型的自编码器(如去噪自编码器、变分自编码器等)以获得更好的效果。
四、应用场景
自编码器在多个领域具有广泛的应用,以下是一些具体的应用场景及其实现代码示例:
1. 数据降维
自编码器可以用于将高维数据映射到低维空间,便于可视化和后续分析。以下是一个使用自编码器进行数据降维的示例,使用MNIST手写数字数据集。
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Dense
# 加载MNIST数据集
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.reshape((len(x_train), -1)).astype('float32') / 255
x_test = x_test.reshape((len(x_test), -1)).astype('float32') / 255
# 定义自编码器结构
input_dim = 784 # 输入维度
encoding_dim = 32 # 潜在空间维度
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
decoded = Dense(input_dim, activation='sigmoid')(encoded)
autoencoder = Model(input_layer, decoded)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# 训练自编码器
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, validation_split=0.2)
# 提取编码器
encoder = Model(input_layer, encoded)
encoded_data = encoder.predict(x_test)
# 可视化降维结果
plt.scatter(encoded_data[:, 0], encoded_data[:, 1], c=np.argmax(x_test, axis=1), cmap='viridis')
plt.colorbar()
plt.title('Data Dimensionality Reduction using Autoencoder')
plt.xlabel('Encoded Dimension 1')
plt.ylabel('Encoded Dimension 2')
plt.show()
2. 特征学习
自编码器可以用于学习数据的有效特征表示,这些特征可以用于后续的分类或回归任务。以下是一个示例,使用自编码器提取特征并用于分类任务。
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout
from keras.utils import to_categorical
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape((len(x_train), -1)).astype('float32') / 255
x_test = x_test.reshape((len(x_test), -1)).astype('float32') / 255
# 定义自编码器
input_dim = 784
encoding_dim = 32
autoencoder = Sequential()
autoencoder.add(Dense(encoding_dim, activation='relu', input_shape=(input_dim,)))
autoencoder.add(Dense(input_dim, activation='sigmoid'))
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# 训练自编码器
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, validation_split=0.2)
# 提取编码器
encoder = Model(autoencoder.input, autoencoder.layers[0].output)
encoded_train = encoder.predict(x_train)
encoded_test = encoder.predict(x_test)
# 使用提取的特征进行分类
classifier = Sequential()
classifier.add(Dense(128, activation='relu', input_shape=(encoding_dim,)))
classifier.add(Dropout(0.2))
classifier.add(Dense(10, activation='softmax'))
classifier.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
classifier.fit(encoded_train, to_categorical(y_train), epochs=50, batch_size=256, validation_split=0.2)
# 评估分类器
loss, accuracy = classifier.evaluate(encoded_test, to_categorical(y_test))
print(f'Test Accuracy: {accuracy}')
3. 图像去噪
自编码器可以用于去除图像中的噪声,通过学习干净图像的特征来重构清晰的图像。以下是一个去噪自编码器的示例。
from keras.datasets import mnist
# 加载MNIST数据集
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# 添加噪声
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
# 限制像素值在[0, 1]之间
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
# 重塑数据
x_train_noisy = x_train_noisy.reshape((len(x_train_noisy), -1))
x_test_noisy = x_test_noisy.reshape((len(x_test_noisy), -1))
# 定义去噪自编码器
input_dim = 784
encoding_dim = 32
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
decoded = Dense(input_dim, activation='sigmoid')(encoded)
denoising_autoencoder = Model(input_layer, decoded)
denoising_autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# 训练去噪自编码器
denoising_autoencoder.fit(x_train_noisy, x_train.reshape((len(x_train), -1)), epochs=50, batch_size=256, validation_split=0.2)
# 重构测试集
denoised_images = denoising_autoencoder.predict(x_test_noisy)
# 可视化去噪效果
n = 10 # 展示的图像数量
plt.figure(figsize=(20, 4))
for i in range(n):
# 原始图像
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28), cmap='gray')
plt.title("Original")
plt.axis('off')
# 去噪图像
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(denoised_images[i].reshape(28, 28), cmap='gray')
plt.title("Denoised")
plt.axis('off')
plt.show()
4. 异常检测
自编码器可以用于异常检测,通过计算重构误差来识别异常数据点。以下是一个简单的异常检测示例。
from keras.datasets import mnist
import numpy as np
# 加载MNIST数据集
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.reshape((len(x_train), -1)).astype('float32') / 255
x_test = x_test.reshape((len(x_test), -1)).astype('float32') / 255
# 定义自编码器
input_dim = 784
encoding_dim = 32
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
decoded = Dense(input_dim, activation='sigmoid')(encoded)
autoencoder = Model(input_layer, decoded)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
# 训练自编码器
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, validation_split=0.2)
# 计算重构误差
reconstructed = autoencoder.predict(x_test)
mse = np.mean(np.power(x_test - reconstructed, 2), axis=1)
# 设定阈值
threshold = 0.01 # 根据数据集特性调整
anomalies = mse > threshold
# 可视化异常检测结果
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 10, i + 1)
plt.imshow(x_test[i].reshape(28, 28), cmap='gray')
plt.title("Normal" if not anomalies[i] else "Anomaly")
plt.axis('off')
plt.show()
总结
自编码器作为一种强大的无监督学习工具,凭借其独特的结构和灵活性,在多个领域展现了广泛的应用潜力。通过对输入数据的有效压缩与重构,自编码器不仅能够实现数据降维和特征学习,还能在图像去噪和异常检测等任务中发挥重要作用。本文详细探讨了自编码器的基本原理、数学模型、实现步骤以及具体应用场景,结合代码示例,使得读者能够更深入地理解自编码器的工作机制及其实际应用。随着数据量的不断增加和复杂性的提升,自编码器将继续在数据处理和分析中扮演关键角色,为研究人员和工程师提供更为高效和有效的解决方案。未来,随着技术的不断进步,自编码器的变种和应用场景将不断扩展,推动人工智能领域的进一步发展。
码文不易,本篇文章就介绍到这里,如果想要学习更多Java系列知识,点击关注博主,博主带你零基础学习Java知识。与此同时,对于日常生活有困扰的朋友,欢迎阅读我的第四栏目:《国学周更—心性养成之路》,学习技术的同时,我们也注重了心性的养成。



















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











