



文章目录
🌟 第0层:极简版(30秒理解)
一句话核心:模型蒸馏是"老师教学生"——用大模型(老师)的知识指导小模型(学生)学习,让小模型获得接近大模型的性能。
核心公式(记住这个!)
完整的学生损失函数如下:
L
student
=
α
⋅
L
hard
+
(
1
−
α
)
⋅
T
2
⋅
L
soft
(
T
)
L_{\text{student}} = \alpha \cdot L_{\text{hard}} + (1 - \alpha) \cdot \color{red}{T^2} \cdot L_{\text{soft}}(\color{red}T)
Lstudent=α⋅Lhard+(1−α)⋅T2⋅Lsoft(T)
- 硬目标损失 ( L hard L_{\text{hard}} Lhard):基于真实标签(0/1)计算的损失(如交叉熵)。
- 软目标损失 ( L soft ( T ) L_{\text{soft}}(T) Lsoft(T)):基于老师模型用温度 T \color{red}T T 软化后的预测概率(如[0.1, 0.7, 0.2])计算的损失(如KL散度)。
- 温度 T \color{red}T T:控制软目标"柔和度"的核心参数(T>1时更柔和,蕴含更多知识)。
- 权重 α \alpha α:平衡两种损失贡献的超参数。
- 缩放因子 T 2 \color{red}{T^2} T2:用于补偿高温导致的梯度减小,确保训练稳定性。
生活比喻
想象两位厨师:
- 老师模型:米其林三星大厨(准确但慢且贵)
- 学生模型:学徒厨师(快且便宜,但需要指导)
- 蒸馏过程:大厨不仅告诉学徒"这道菜应该这样",还分享其精细的权衡判断(比如“盐多一点,但如果客人口味淡,就少一点用胡椒补足”),这对应了概率分布中的“黑暗知识”。
⚠️ 核心前提:老师必须会!
蒸馏完全依赖教师模型的知识。如果“大厨”手艺有缺陷(过拟合、有偏见),学徒也会学坏。选择一个高质量的教师模型是成功的基石。
💡 记住这个比例:T=3-10
蒸馏时温度参数通常设为3-10,让概率分布更"柔和",包含更多知识。
📚 第1层:基础概念(5分钟理解)
1. 什么是模型蒸馏?
模型蒸馏(Distillation) 是一种知识迁移技术,将大型复杂模型(教师模型)的知识迁移到小型简单模型(学生模型)中。
为什么需要它?
- 问题:大型模型(如BERT、GPT)性能好但:
- 计算资源需求高
- 推理速度慢
- 难以部署在移动设备
- 解决方案:用蒸馏创建小而快但性能接近的模型
蒸馏 vs 传统训练
2. 软目标 vs 硬目标
硬目标(传统训练)
- 只有"正确/错误"信息
- 例如:[0, 0, 1, 0](第3类是正确答案)
- 缺点:丢失类别间关系信息
软目标(蒸馏关键)
- 包含类别间关系信息
- 例如:[0.1, 0.2, 0.6, 0.1](第3类最可能,但第2类也有一定可能)
- 优势:
- "猫"和"狗"比"猫"和"汽车"更相似
- 捕捉教师模型学到的隐含知识(Dark Knowledge)
- 风险:如果教师模型本身有偏见或错误,这些缺陷也会被“蒸馏”给学生模型。教师模型的质量直接决定了学生模型的上限。
3. 温度参数的魔力
什么是温度参数T?
控制预测概率分布"柔和度"的参数:
soft_logits
=
logits
T
\text{soft\_logits} = \frac{\text{logits}}{T}
soft_logits=Tlogits
soft_probs
=
softmax
(
soft_logits
)
\text{soft\_probs} = \text{softmax}(\text{soft\_logits})
soft_probs=softmax(soft_logits)
温度影响示例
| 温度T | 预测概率分布 | 特点 |
|---|---|---|
| T=1 | [0.05, 0.1, 0.8, 0.05] | 接近one-hot,硬目标 |
| T=3 | [0.15, 0.25, 0.5, 0.1] | 更柔和,保留更多信息 |
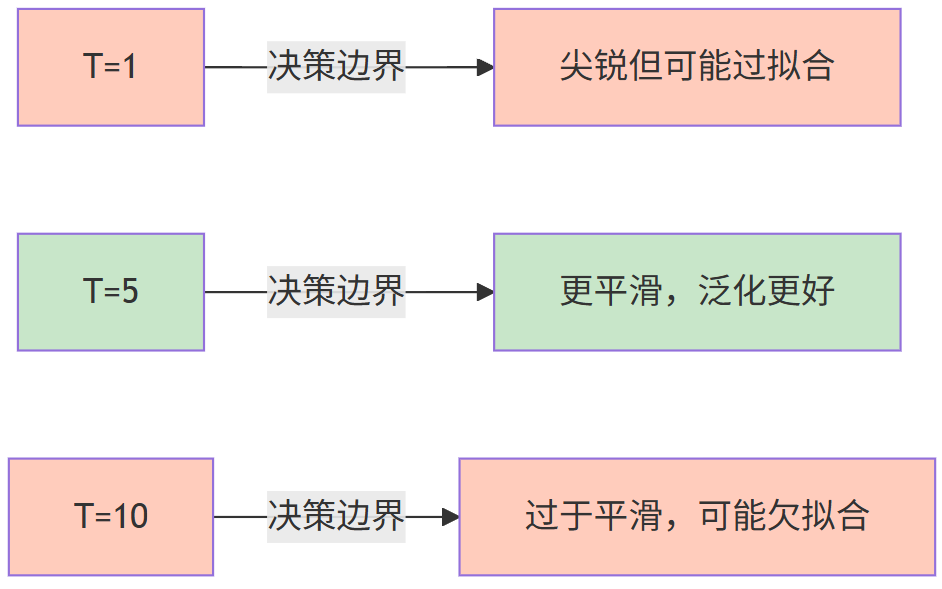
| T=10 | [0.2, 0.25, 0.35, 0.2] | 非常柔和,类别间关系明显 |
💡 关键洞察:高温度让小概率事件"可见",学生能学到更多类别间关系。但温度过高可能导致决策边界过于平滑,引发欠拟合。
4. 蒸馏过程简述
典型效果:
- 学生模型大小:教师模型的1/10 - 1/100
- 性能保留:教师模型性能的95-99%
- 推理速度:提升3-10倍
🔍 第2层:中等深度(15分钟理解)
1. 模型蒸馏的数学原理
标准交叉熵损失
L hard = − ∑ y i ⋅ log ( p i ) L_{\text{hard}} = -\sum y_i \cdot \log(p_i) Lhard=−∑yi⋅log(pi)
- y i y_i yi:真实标签(one-hot)
- p i p_i pi:学生模型预测概率
蒸馏损失函数
L distill = α ⋅ L hard + ( 1 − α ) ⋅ T 2 ⋅ L soft L_{\text{distill}} = \alpha \cdot L_{\text{hard}} + (1-\alpha) \cdot T^2 \cdot L_{\text{soft}} Ldistill=α⋅Lhard+(1−α)⋅T2⋅Lsoft
- L soft = − ∑ q i ⋅ log ( p i ) L_{\text{soft}} = -\sum q_i \cdot \log(p_i) Lsoft=−∑qi⋅log(pi)
- q i q_i qi:教师模型的软目标(温度T下)
- α \alpha α:硬/软损失权重(通常0.1-0.9)
- T 2 T^2 T2:温度缩放因子。这里的 T 2 T^2 T2 用于在反向传播时补偿因温度缩放导致的梯度减小,确保软损失项的梯度与硬损失项保持在相近的量级。
为什么需要 T 2 T^2 T2?
- 温度T增加 → 软目标熵增加 → 梯度变小
- T 2 T^2 T2缩放 → 保持软损失梯度与硬损失相当
2. 蒸馏过程详解
三阶段蒸馏流程
flowchart LR
A[阶段1] -->|教师训练| B[在完整数据集上训练教师模型]
B --> C[阶段2] -->|软标签生成| D[用教师模型为所有训练数据生成软标签]
D --> E[阶段3] -->|学生训练| F[用硬标签+软标签训练学生模型]
style A,B,C,D,E,F fill:#c8e6c9
阶段2:软标签生成
def generate_soft_labels(teacher, data_loader, temperature=5.0):
soft_labels = []
for inputs, _ in data_loader:
# 禁用dropout和batchnorm的评估模式
teacher.eval()
with torch.no_grad():
# 获取logits并应用温度
logits = teacher(inputs)
soft_logits = logits / temperature
# 转换为概率
soft_probs = F.softmax(soft_logits, dim=-1)
soft_labels.append(soft_probs)
return torch.cat(soft_labels)
阶段3:学生训练
def train_student(student, teacher, train_loader, temperature=5.0, alpha=0.7):
optimizer = torch.optim.Adam(student.parameters())
for inputs, hard_labels in train_loader:
# 获取教师软标签
with torch.no_grad():
teacher_logits = teacher(inputs) / temperature
soft_labels = F.softmax(teacher_logits, dim=-1)
# 学生前向传播
student_logits = student(inputs)
student_probs = F.softmax(student_logits / temperature, dim=-1)
# 计算损失
hard_loss = F.cross_entropy(student_logits, hard_labels)
soft_loss = F.kl_div(
F.log_softmax(student_logits / temperature, dim=-1),
soft_labels,
reduction='batchmean'
) * (temperature ** 2) # 注意这里的 T²
loss = alpha * hard_loss + (1 - alpha) * soft_loss
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
3. 蒸馏效果可视化
软目标 vs 硬目标
温度对决策边界的影响
4. 经典蒸馏方法对比
1. logits蒸馏(Hinton原始方法)
- 核心:匹配教师和学生的logits
- 优势:简单有效
- 局限:只利用最终输出
2. 特征蒸馏
- 核心:匹配中间层特征
- 优势:捕获更多结构化知识
- 方法:
L feature = ∣ ∣ F t ( x ) − F s ( x ) ∣ ∣ 2 L_{\text{feature}} = ||F_t(x) - F_s(x)||^2 Lfeature=∣∣Ft(x)−Fs(x)∣∣2- F t F_t Ft:教师中间特征
- F s F_s Fs:学生中间特征
3. 关系蒸馏
- 核心:匹配样本间关系
- 优势:捕获全局结构
- 方法:
L relation = ∣ ∣ R ( F t ( x ) ) − R ( F s ( x ) ) ∣ ∣ 2 L_{\text{relation}} = ||R(F_t(x)) - R(F_s(x))||^2 Lrelation=∣∣R(Ft(x))−R(Fs(x))∣∣2- R R R:关系函数(如Gram矩阵)
4. 自蒸馏
- 核心:用同一模型的不同阶段作为教师
- 优势:无需额外教师模型
- 方法:用训练中期的模型指导后期训练
⚙️ 第3层:技术深度(30分钟理解)
1. 高级蒸馏技术详解
1. 特征蒸馏实现
class FeatureDistiller:
def __init__(self, teacher, student, layer_mapping):
"""
layer_mapping: 教师层到学生层的映射
例如: {4: 2, 8: 4, 12: 6} (教师第4层→学生第2层)
"""
self.teacher = teacher
self.student = student
self.layer_mapping = layer_mapping
# 注册钩子获取中间特征
self.teacher_features = {}
self.student_features = {}
for t_layer, s_layer in layer_mapping.items():
self._register_hooks(t_layer, s_layer)
def _register_hooks(self, t_layer, s_layer):
def teacher_hook(module, input, output):
self.teacher_features[t_layer] = output
def student_hook(module, input, output):
self.student_features[s_layer] = output
# 获取对应层
t_module = self._get_module(self.teacher, t_layer)
s_module = self._get_module(self.student, s_layer)
# 注册钩子
t_module.register_forward_hook(teacher_hook)
s_module.register_forward_hook(student_hook)
def _get_module(self, model, layer_idx):
# 简化版:实际需要根据模型结构实现
# 在实际应用中,通常使用钩子(hook)机制按模块名而非序号来捕获特征
if hasattr(model, 'layers'):
return model.layers[layer_idx]
elif hasattr(model, 'blocks'):
return model.blocks[layer_idx]
else:
return list(model.children())[layer_idx]
def feature_loss(self):
loss = 0.0
for t_layer, s_layer in self.layer_mapping.items():
t_feat = self.teacher_features[t_layer]
s_feat = self.student_features[s_layer]
# 调整学生特征尺寸以匹配教师
if s_feat.shape != t_feat.shape:
s_feat = F.interpolate(
s_feat,
size=t_feat.shape[2:],
mode='bilinear',
align_corners=False
)
# 计算特征损失
loss += F.mse_loss(s_feat, t_feat)
return loss / len(self.layer_mapping)
def train_step(self, inputs, hard_labels, alpha=0.5, beta=0.5, temp=5.0):
# 清空之前的特征
self.teacher_features = {}
self.student_features = {}
# 教师前向传播
with torch.no_grad():
teacher_logits = self.teacher(inputs) / temp
soft_labels = F.softmax(teacher_logits, dim=-1)
# 学生前向传播
student_logits = self.student(inputs)
# 计算各类损失
hard_loss = F.cross_entropy(student_logits, hard_labels)
soft_loss = F.kl_div(
F.log_softmax(student_logits / temp, dim=-1),
soft_labels,
reduction='batchmean'
) * (temp ** 2)
feature_loss = self.feature_loss()
# 组合损失
loss = alpha * hard_loss + beta * soft_loss + (1 - alpha - beta) * feature_loss
return loss
2. 关系蒸馏实现
def relational_distillation_loss(teacher_features, student_features, temperature=1.0):
"""
计算关系蒸馏损失
teacher_features: 教师模型的中间特征 [batch, channels, h, w]
student_features: 学生模型的中间特征 [batch, channels, h, w]
"""
# 计算Gram矩阵(捕捉特征关系)
def compute_gram_matrix(features):
batch, channels, h, w = features.shape
features = features.view(batch, channels, -1)
gram = torch.bmm(features, features.transpose(1, 2))
return gram / (channels * h * w)
# 计算关系损失
teacher_gram = compute_gram_matrix(teacher_features)
student_gram = compute_gram_matrix(student_features)
# 使用温度缩放关系
teacher_relation = F.softmax(teacher_gram / temperature, dim=-1)
student_relation = F.log_softmax(student_gram / temperature, dim=-1)
# KL散度损失
loss = F.kl_div(student_relation, teacher_relation, reduction='batchmean')
return loss
2. 温度调度策略
固定温度 vs 动态温度
def train_with_fixed_temp(student, teacher, loader, temp=5.0):
"""固定温度训练"""
for epoch in range(epochs):
for inputs, labels in loader:
# 使用固定温度
loss = compute_distill_loss(student, teacher, inputs, labels, temp=temp)
# 训练步骤...
def train_with_dynamic_temp(student, teacher, loader, start_temp=10.0, end_temp=1.0):
"""动态温度调度"""
total_steps = len(loader) * epochs
for step, (inputs, labels) in enumerate(loader):
# 线性衰减温度
temp = start_temp - (start_temp - end_temp) * step / total_steps
loss = compute_distill_loss(student, teacher, inputs, labels, temp=temp)
# 训练步骤...
最佳温度选择策略
def find_optimal_temperature(student, teacher, val_loader, temps=[1, 2, 3, 5, 7, 10]):
"""找到最优温度参数"""
best_temp = temps[0]
best_score = float('-inf')
for temp in temps:
# 临时设置温度
student.set_temp(temp)
# 评估验证集性能
score = evaluate_model(student, val_loader)
if score > best_score:
best_score = score
best_temp = temp
return best_temp
3. 无数据蒸馏(Data-Free Knowledge Distillation)
核心思想
当没有原始训练数据时,如何进行蒸馏?
生成伪数据方法
def generate_pseudo_data(teacher, num_samples=1000, img_size=(3, 32, 32)):
"""生成用于蒸馏的伪数据"""
# 初始化随机噪声图像
pseudo_images = torch.randn(num_samples, *img_size, requires_grad=True)
optimizer = torch.optim.Adam([pseudo_images], lr=0.1)
# 优化图像以最大化教师模型的预测熵
for step in range(1000):
optimizer.zero_grad()
# 获取教师预测
with torch.no_grad():
teacher_logits = teacher(pseudo_images)
teacher_probs = F.softmax(teacher_logits, dim=-1)
# 计算损失:最大化预测熵(鼓励多样性)
entropy = -(teacher_probs * torch.log(teacher_probs + 1e-7)).sum(dim=-1).mean()
loss = -entropy # 最大化熵
loss.backward()
optimizer.step()
# 投影到有效范围
pseudo_images.data = torch.clamp(pseudo_images.data, 0, 1)
return pseudo_images.detach()
无数据蒸馏流程
4. 跨模态蒸馏
图像到文本的蒸馏示例
class CrossModalDistiller:
def __init__(self, image_teacher, text_student):
self.image_teacher = image_teacher
self.text_student = text_student
def distill_step(self, image_batch, alpha=0.6):
# 图像教师生成软标签
with torch.no_grad():
image_features = self.image_teacher.encode_image(image_batch)
soft_labels = self.image_teacher.classify(image_features)
# 提取文本描述
text_descriptions = self._generate_text_descriptions(image_batch)
# 文本学生前向传播
text_features = self.text_student.encode_text(text_descriptions)
student_logits = self.text_student.classify(text_features)
# 计算损失
hard_loss = self._compute_hard_loss(text_descriptions) # 如果有真实标签
soft_loss = F.kl_div(
F.log_softmax(student_logits, dim=-1),
soft_labels,
reduction='batchmean'
)
return alpha * hard_loss + (1 - alpha) * soft_loss
def _generate_text_descriptions(self, images):
"""生成图像的文本描述(简化版)"""
# 实际应用中可能使用CLIP或BLIP等模型
descriptions = []
for img in images:
# 这里简化:实际应调用图像描述模型
desc = "a photo of " + self._guess_category(img)
descriptions.append(desc)
return descriptions
def _guess_category(self, image):
"""猜测图像类别(简化版)"""
# 实际应使用图像分类模型
return "animal" # 简化示例
🔬 第4层:前沿研究(60分钟理解)
1. 大语言模型(LLM)知识蒸馏专章
随着大语言模型(LLMs)的兴起,知识蒸馏已成为将先进功能从领先的专有LLM(例如GPT-4)转移到更小、更高效的开源模型(例如LLaMA和Mistral)的关键方法。
LLM蒸馏的核心范式与传统蒸馏的差异
- 数据增强(DA)成为主流:传统蒸馏依赖原始数据集,而LLM蒸馏常通过小规模“种子”数据激发LLM生成大量特定领域或技能的扩展数据,再用这些合成数据微调学生模型。这是一种 “以数据为中心” 的范式。
- 黑盒蒸馏(Black-Box Distillation)的挑战:对于闭源的商业API(如GPT-4),学生模型无法访问其内部结构或中间层特征,只能依赖其输出分布。这限制了特征蒸馏等高级方法的应用,迫使研究者探索更有效的输出层面知识提取技术。
- 目标多样化:LLM蒸馏的目标不仅是模仿分类概率,还包括迁移生成能力、推理能力、遵循指令的能力、安全性(Alignment) 等复杂技能。
LLM蒸馏的最新技术与挑战
- 注意力蒸馏:利用LLM的自注意力机制,将教师模型的注意力模式或特征迁移到学生模型,以更好地保留语义和结构信息。
- 多教师蒸馏:探索如何将不同教师模型(可能擅长不同任务)的知识有效整合到单一学生模型中。
- 数据选择与生成:如何自动选择或生成最有利于蒸馏效果的数据是一个关键研究方向。例如,使用教师模型自身来评估生成数据的“教学价值”。
- 评估挑战:评估蒸馏后LLM的性能不仅要看准确率,还需评估其生成质量、多样性、安全性、推理链一致性等。
- 知名案例:DistilBERT、TinyBERT、DistilGPT 等是成功将BERT、GPT系列模型蒸馏到更小规模的著名案例。近期,DistilQwen2 等模型也展示了在强大开源模型上进行蒸馏的有效性。
2. 蒸馏理论分析
泛化误差边界
蒸馏可以改善泛化误差边界:
泛化误差
≤
经验误差
+
O
(
d
/
n
)
\text{泛化误差} \leq \text{经验误差} + O(\sqrt{d/n})
泛化误差≤经验误差+O(d/n)
- d d d:模型复杂度
- n n n:训练样本数
蒸馏的影响:
- 通过软标签提供更多有效样本
- 相当于增加训练数据的信息量
- 有效降低 d / n d/n d/n比例
知识迁移的表示理论
关键洞见:蒸馏本质上是迁移表示空间结构
数学表示:
- 教师模型定义了一个表示流形 M t M_t Mt
- 学生模型学习近似这个流形 M s ≈ M t M_s \approx M_t Ms≈Mt
- 蒸馏损失衡量流形间的几何距离
理论结果:
- 当教师和学生架构相似时,蒸馏能保持流形结构
- 当架构差异大时,需要额外的结构匹配损失
3. 高级蒸馏技术
1. 动态蒸馏(Dynamic Distillation)
核心思想:根据样本难度动态调整蒸馏策略
实现:
class DynamicDistiller:
def __init__(self, teacher, student, hard_threshold=0.3):
self.teacher = teacher
self.student = student
self.hard_threshold = hard_threshold
def compute_loss(self, inputs, labels):
# 教师预测
with torch.no_grad():
teacher_logits = self.teacher(inputs)
teacher_probs = F.softmax(teacher_logits, dim=-1)
max_probs, _ = torch.max(teacher_probs, dim=-1)
# 确定样本难度
hard_mask = max_probs < self.hard_threshold # 低置信度=难样本
easy_mask = ~hard_mask
# 学生预测
student_logits = self.student(inputs)
# 难样本:更多依赖硬标签
hard_loss = F.cross_entropy(student_logits[hard_mask], labels[hard_mask])
# 易样本:更多依赖软标签
soft_loss = F.kl_div(
F.log_softmax(student_logits[easy_mask] / 5.0, dim=-1),
F.softmax(teacher_logits[easy_mask] / 5.0, dim=-1),
reduction='batchmean'
) * 25 # T² = 5²
# 组合损失
total_loss = hard_loss * hard_mask.float().mean() + soft_loss * easy_mask.float().mean()
return total_loss
2. 对抗蒸馏(Adversarial Distillation)
核心思想:使用对抗训练增强蒸馏效果
架构:
实现:
class AdversarialDistiller:
def __init__(self, teacher, student, discriminator):
self.teacher = teacher
self.student = student
self.discriminator = discriminator
self.adv_lambda = 0.1 # 对抗损失权重
def train_step(self, inputs, labels, alpha=0.7, temp=5.0):
# 1. 教师生成软标签
with torch.no_grad():
teacher_logits = self.teacher(inputs) / temp
soft_labels = F.softmax(teacher_logits, dim=-1)
# 2. 学生前向传播
student_logits = self.student(inputs)
# 3. 计算蒸馏损失
hard_loss = F.cross_entropy(student_logits, labels)
soft_loss = F.kl_div(
F.log_softmax(student_logits / temp, dim=-1),
soft_labels,
reduction='batchmean'
) * (temp ** 2)
distill_loss = alpha * hard_loss + (1 - alpha) * soft_loss
# 4. 对抗训练
# 生成特征用于判别
with torch.no_grad():
teacher_features = self._extract_features(self.teacher, inputs)
student_features = self._extract_features(self.student, inputs)
# 判别器训练
real_preds = self.discriminator(teacher_features)
fake_preds = self.discriminator(student_features.detach())
d_loss_real = F.binary_cross_entropy_with_logits(real_preds, torch.ones_like(real_preds))
d_loss_fake = F.binary_cross_entropy_with_logits(fake_preds, torch.zeros_like(fake_preds))
d_loss = (d_loss_real + d_loss_fake) / 2
# 学生对抗损失
fake_preds = self.discriminator(student_features)
g_loss = F.binary_cross_entropy_with_logits(fake_preds, torch.ones_like(fake_preds))
# 5. 组合损失
total_loss = distill_loss + self.adv_lambda * g_loss
return total_loss, d_loss, g_loss
def _extract_features(self, model, inputs):
"""提取中间特征(简化版)"""
# 实际需要根据模型结构实现
if hasattr(model, 'features'):
return model.features(inputs)
else:
return model(inputs, return_features=True)
4. 蒸馏与神经架构搜索(NAS)
蒸馏引导的NAS
优势:
- 蒸馏评估比完整训练快10-100倍
- 能更准确预测最终性能
- 避免搜索过程中的资源浪费
实现代码
def nas_with_distillation(search_space, teacher, epochs=50, top_k=5):
candidates = []
for _ in range(epochs):
# 1. 从搜索空间采样候选架构
candidate = sample_architecture(search_space)
# 2. 快速蒸馏训练(少量epoch)
student = build_model(candidate)
distiller = BasicDistiller(teacher, student)
# 只训练5个epoch进行快速评估
for _ in range(5):
distiller.train_step(next(train_loader))
# 3. 评估性能
val_acc = evaluate(student, val_loader)
candidates.append((candidate, val_acc))
# 4. 选择top-k候选进行完整训练
candidates.sort(key=lambda x: x[1], reverse=True)
top_candidates = [c[0] for c in candidates[:top_k]]
# 5. 完整蒸馏训练
final_models = []
for candidate in top_candidates:
student = build_model(candidate)
distiller = BasicDistiller(teacher, student, full_epochs=100)
distiller.train(train_loader)
final_models.append((candidate, student))
return final_models
5. 蒸馏与联邦学习
隐私保护的联邦蒸馏
优势:
- 无需共享原始数据
- 保护用户隐私
- 兼顾模型性能和隐私
实现代码
class FederatedDistiller:
def __init__(self, global_student, clients, alpha=0.5, temp=5.0):
self.global_student = global_student
self.clients = clients
self.alpha = alpha
self.temp = temp
def federated_train(self, rounds=10, client_epochs=5):
for r in range(rounds):
client_updates = []
# 1. 客户端本地训练
for client in self.clients:
# 从服务器获取最新学生模型
client.load_model(self.global_student)
# 本地蒸馏训练
client_distiller = ClientDistiller(
teacher=client.local_teacher,
student=client.model,
alpha=self.alpha,
temp=self.temp
)
for _ in range(client_epochs):
client_distiller.train_step(client.train_loader)
# 计算更新
update = client.get_model_update()
client_updates.append(update)
# 2. 服务器聚合更新
avg_update = self._aggregate_updates(client_updates)
self.global_student.apply_update(avg_update)
# 3. 评估全局模型
val_acc = evaluate(self.global_student, global_val_loader)
print(f"Round {r+1} | Global Acc: {val_acc:.4f}")
def _aggregate_updates(self, updates):
"""简单平均聚合"""
avg_update = {}
for key in updates[0].keys():
avg_update[key] = torch.stack([u[key] for u in updates], dim=0).mean(dim=0)
return avg_update
class ClientDistiller:
def __init__(self, teacher, student, alpha=0.5, temp=5.0):
self.teacher = teacher
self.student = student
self.alpha = alpha
self.temp = temp
self.optimizer = torch.optim.Adam(student.parameters())
def train_step(self, data_loader):
inputs, hard_labels = next(iter(data_loader))
# 教师生成软标签
with torch.no_grad():
teacher_logits = self.teacher(inputs) / self.temp
soft_labels = F.softmax(teacher_logits, dim=-1)
# 学生前向传播
student_logits = self.student(inputs)
# 计算损失
hard_loss = F.cross_entropy(student_logits, hard_labels)
soft_loss = F.kl_div(
F.log_softmax(student_logits / self.temp, dim=-1),
soft_labels,
reduction='batchmean'
) * (self.temp ** 2)
loss = self.alpha * hard_loss + (1 - self.alpha) * soft_loss
# 反向传播
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
6. 蒸馏理论极限与挑战
1. 知识容量限制
- 教师瓶颈:学生无法学到教师没有的知识
- 表示差距:学生架构限制了可迁移知识量
- 数学表达:
I ( S ; Y ∣ X ) ≤ I ( T ; Y ∣ X ) I(S;Y|X) \leq I(T;Y|X) I(S;Y∣X)≤I(T;Y∣X)- I I I:互信息
- S S S:学生
- T T T:教师
- Y Y Y:标签
- X X X:输入
2. 蒸馏效率边界
关键结果:蒸馏效率受以下因素影响
- 教师-学生容量比:最优比例约5-10:1
- 任务复杂度:简单任务蒸馏效率更高
- 数据质量:高质量数据提高蒸馏效率
3. 灾难性遗忘问题
当进行连续蒸馏(多个教师到一个学生):
- 新知识覆盖旧知识
- 学生忘记之前学到的知识
解决方案:
- 弹性权重巩固(EWC)
- 回放旧教师的知识
- 正交蒸馏:确保新旧知识正交
4. 安全蒸馏与价值对齐(新增)
- 挑战:蒸馏可能复制并压缩教师模型中的社会偏见、有害内容生成倾向、安全漏洞。这是一个在负责任AI领域受到广泛关注的问题。
- 研究方向:如何在进行知识蒸馏的同时,过滤掉有害知识,甚至提升学生模型的安全性和对齐性(Alignment),是一个重要的前沿课题。
5. 教师模型选择的重要性(新增强调)
选择一个高质量、不过拟合的教师模型是蒸馏成功的前提。如果教师模型本身存在缺陷(如过拟合、偏见、错误的知识),学生模型很可能会继承甚至放大这些问题。因此,在开始蒸馏前,对教师模型进行全面的评估至关重要。
📊 实用指南:如何有效应用模型蒸馏
1. 蒸馏方法选择决策树
2. 蒸馏参数调优指南
温度参数T
| 任务类型 | 推荐范围 | 调整策略 |
|---|---|---|
| 图像分类 | 2-8 | 从5开始,根据验证集调整 |
| 语义分割 | 4-10 | 较高温度保留空间关系 |
| 语言模型 | 0.5-2.0 | 较低温度保持语言结构 |
| 目标检测 | 3-6 | 中等温度平衡定位和分类 |
损失权重 α \alpha α
- α \alpha α高(0.7-0.9):当硬标签非常可靠时
- α \alpha α低(0.3-0.5):当教师模型远优于学生时
- 动态 α \alpha α:训练初期 α \alpha α低,后期 α \alpha α高
特征匹配层选择
| 学生大小 | 推荐匹配层 | 原因 |
|---|---|---|
| 大学生 | 深层+浅层 | 捕获多层次知识 |
| 中学生 | 中间层 | 平衡抽象和细节 |
| 小学生 | 浅层 | 避免过拟合教师复杂特征 |
3. 蒸馏质量评估指标
1. 基本性能指标
- 准确率:与教师/基线比较
- 推理速度:FPS或延迟
- 模型大小:参数量/内存占用
2. 知识迁移质量指标
def evaluate_distillation_quality(student, teacher, test_loader):
"""评估蒸馏质量的综合指标"""
student_correct = 0
teacher_correct = 0
agreement = 0
total = 0
# 计算准确率和一致性
for inputs, labels in test_loader:
with torch.no_grad():
s_logits = student(inputs)
t_logits = teacher(inputs)
s_pred = s_logits.argmax(dim=-1)
t_pred = t_logits.argmax(dim=-1)
student_correct += (s_pred == labels).sum().item()
teacher_correct += (t_pred == labels).sum().item()
agreement += (s_pred == t_pred).sum().item()
total += labels.size(0)
# 计算类别关系保留
class_relations = []
for class_i in range(num_classes):
for class_j in range(class_i + 1, num_classes):
# 计算教师和学生对这两个类的区分能力
teacher_diff = _class_diff(teacher, class_i, class_j)
student_diff = _class_diff(student, class_i, class_j)
relation_preserved = 1 - abs(teacher_diff - student_diff) / (teacher_diff + 1e-7)
class_relations.append(relation_preserved)
return {
"student_acc": student_correct / total,
"teacher_acc": teacher_correct / total,
"agreement": agreement / total,
"class_relation_preservation": np.mean(class_relations)
}
def _class_diff(model, class_i, class_j):
"""计算模型区分两个类的能力"""
# 简化版:实际应使用验证集样本
return 0.5 # 示例值
4. 实用蒸馏技巧
1. 渐进式蒸馏
def progressive_distillation(teacher, student, train_loader,
stages=[(0.3, 8), (0.5, 5), (0.7, 2)]):
"""
渐进式蒸馏:逐步增加硬损失权重,降低温度
stages: [(alpha, temp), ...]
"""
for alpha, temp in stages:
print(f"Training with alpha={alpha}, temp={temp}")
for epoch in range(10): # 每阶段训练10个epoch
for inputs, labels in train_loader:
# 计算蒸馏损失
loss = compute_distill_loss(
student, teacher, inputs, labels,
alpha=alpha, temp=temp
)
# 训练步骤...
2. 知识选择性迁移
def selective_distillation(teacher, student, train_loader,
confidence_threshold=0.9,
temperature=5.0):
"""
只蒸馏教师高置信度的样本
"""
for inputs, labels in train_loader:
# 教师预测
with torch.no_grad():
teacher_logits = teacher(inputs) / temperature
teacher_probs = F.softmax(teacher_logits, dim=-1)
max_probs, teacher_preds = torch.max(teacher_probs, dim=-1)
# 选择高置信度样本
high_confidence = max_probs > confidence_threshold
low_confidence = ~high_confidence
# 学生预测
student_logits = student(inputs)
# 高置信度样本:使用软标签
if high_confidence.any():
soft_loss = F.kl_div(
F.log_softmax(student_logits[high_confidence] / temperature, dim=-1),
teacher_probs[high_confidence],
reduction='batchmean'
) * (temperature ** 2)
else:
soft_loss = 0.0
# 低置信度样本:使用硬标签
if low_confidence.any():
hard_loss = F.cross_entropy(
student_logits[low_confidence],
labels[low_confidence]
)
else:
hard_loss = 0.0
# 组合损失
loss = 0.5 * soft_loss + 0.5 * hard_loss
# 训练步骤...
3. Hugging Face 最佳实践(新增)
Hugging Face 的 transformers 库为知识蒸馏提供了强大的支持,简化了从模型加载到训练的流程。
- 模型加载:使用
AutoModel/AutoModelForCausalLM等可以方便地加载教师和学生模型。 - 训练循环:可以使用内置的
Trainer类或自定义训练循环进行蒸馏。Trainer类支持丰富的回调函数和评估指标,方便监控训练过程。 - 中间层访问:库支持通过
output_hidden_states=True等参数获取模型中间层的输出,便于实现特征蒸馏。 - 预训练模型库:Hugging Face Hub 上丰富的预训练模型库(数万个模型)为选择合适的教师和学生架构提供了极大便利。
- 开源蒸馏模型:社区已开源许多成功的蒸馏模型(如 DistilBERT, DistilGPT-2, DistilBART, TinyBERT 等),这些模型可以直接使用或作为自己实施蒸馏的参考。
🌐 模型蒸馏全景图
📌 总结与关键洞见
1. 核心原则
- 知识迁移:蒸馏的本质是迁移教师模型学到的隐含知识
- 软目标优势:软目标包含类别间关系,比硬目标信息更丰富
- 温度魔力:温度参数T控制知识的"抽象级别"
- 教师质量是前提:蒸馏的天花板由教师模型决定,务必选择高性能、高泛化能力的教师。
2. 成功蒸馏的关键
- 教师-学生比例:5-10:1通常最优
- 温度选择:根据任务类型调整(图像3-8,语言1-3)
- 损失平衡:动态调整硬/软损失权重
- 特征匹配:选择合适的中间层进行特征蒸馏
- 教师评估:蒸馏前全面评估教师模型的性能、泛化性和偏见。
3. 常见误区与陷阱
-
误区1:“学生模型越小越好”
事实:过小的学生无法容纳教师知识,性能急剧下降。 -
误区2:“温度越高越好”
事实:过高温度使决策边界过于平滑,导致欠拟合。 -
误区3:“蒸馏总是有效”
事实:当教师和学生架构差异过大时,蒸馏可能失败。教师模型本身的质量是前提。 -
误区4:“只关注最终准确率”
事实:应同时评估知识迁移质量(如类别关系保留、生成多样性、安全性)。 -
误区5:“忽略教师模型选择”
事实:教师模型的任何缺陷(如过拟合、偏见、有害知识)都可能被学生继承甚至放大。
4. 未来展望
- 自动化蒸馏:神经架构搜索与蒸馏结合
- 动态蒸馏:根据输入样本动态调整蒸馏策略
- 理论突破:更精确的知识容量边界
- 跨模态扩展:更高效的多模态知识迁移
- LLM蒸馏深化:针对黑盒API的高效知识提取、复杂能力(如推理、安全对齐)的迁移。
- 安全蒸馏:如何在蒸馏过程中过滤有害知识,实现价值对齐。
💡 终极洞见:蒸馏不是简单压缩,而是知识提炼——就像将一锅浓汤浓缩成精华高汤,去除水分(参数)但保留风味(知识)。成功的蒸馏不仅缩小模型,更提炼出教师模型中最精华的知识。在大模型时代,蒸馏技术是连接强大AI能力与实际应用场景的关键桥梁。记住,这一切始于选择一个优秀的“老师”。
掌握模型蒸馏技术,您就掌握了在资源受限环境下部署高性能AI系统的"密钥",能够在保持模型性能的同时,大幅降低计算成本和提高推理速度!


















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











