






图形学理论中的渲染:追求高效率,表现力和数学运算的正确性。对硬件的实现关注不多,一般根据需求可以分为以下几种:
Realtime:实时渲染,30FPS以上。
Interactive:可交互渲染,10FPS以上。
offline rendering:离线渲染,对渲染时间没有要求,关键在于表现力。
out- of- core rendering:同上,一般一帧渲染几天都有可能,数据由于过大因此会被离散地存储,一般是电影公司的渲染。
游戏渲染的挑战:
1. 同时要处理的对象是非常多且复杂的。
2. 需要深度适配当代硬件,因此需要对硬件的了解。
3. 游戏中的帧率必须是稳定的,因此在不同复杂程度的场景下的帧率稳定是挑战,游戏中的绘制必须在一个固定的期限里运行成功。
4. 游戏跑在电脑上,因此CPU是不能100%地被使用的(只能吃10%-20%左右)。
Rendering的构成要素:顶点数据,表面数据,材质数据,贴图数据。
渲染代码包括:常量/变量访问,数字运算,纹理取样等。
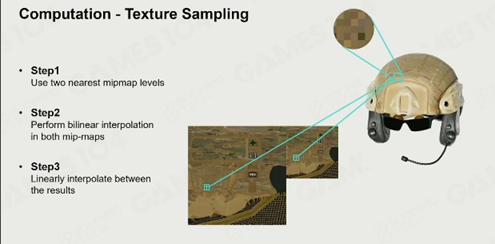
以其中的纹理采样为例:Texture Sampling(纹理采样)的过程:
1.每张纹理会存多级纹理。
2.根据距离取最贴合实际的两级mipmap(分级细化纹理)。
3.在每张mipmap上进行双线性插值获得中间结果。
4.在两个中间结果间做线性插值获得最终结果。
GPU是用于解决大量的图形学复杂运算的专门部件。
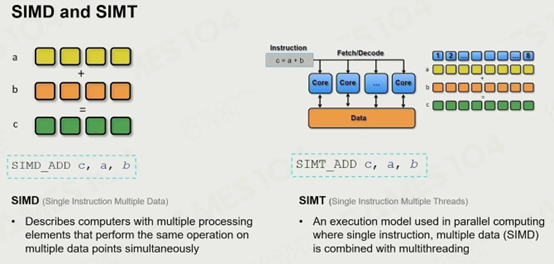
SIMD:单指令多数据运算,能同时执行多个数据运算。是指令级的,一般需要的是长一些的ALU和寄存器。
SIMT:单指令多线程运算,一条指令能执行更多批的数据运算,一般有多核的运算要求,即是针对多个核的处理器构造的指令,是硬件上的,虽然对硬件要求更高,但是处理量级也远高于SIMD。
(有关两者的区别,可以看这篇:SIMD与SIMT区别 - 知乎)
两者的共同点是一条指令能同时执行多个数据并能分别访问。
费米架构下的GPU架构:
GPC(Graphics Processing Cluster):图形处理集群,每个集群中有很多SM(Streaming Multiprocessor)。
SM(Streaming Multiprocessor):在给定一条指令后,各个SM会同时运算,每个SM都会有一个CUDA核。
CUDA Core:并行处理器,允许数据能并行地被不同处理核处理。

核心要点:GPU的结构允许很强大的并行计算操作,且各个核心的计算结果可以互通。
带来的隐患:数据的流动需要消耗一定时间,而数据的来回运输可能会导致游戏引擎的绘制的内容和逻辑不同步。因此在描述底层的绘制逻辑时,一般是固定的单向运输,即由逻辑运向绘制部分就结束了,尽量不要从显卡里往回读数据。
Cache:最快的一层缓存。在几层缓存中存储量最小,数据读取效率最高。因此CacheHit越多,CacheMiss越少,游戏引擎绘制速度越快。
GPU Bounds:现代计算机渲染过程基本是一个流水线过程,若有一个环节卡住了则会影响整体效率。在GPU中,效率最低的环节被称为GPU Bounds。在CPU中也有类似的CPU Bounds存在。
手机,主机,PC等硬件的GPU部分架构都略有不同。在不同平台的硬件上写渲染前,最好先了解它们各自的GPU硬件架构。
Mesh Primitive:基础的mesh(网格)数据表示方式。

VertexData:描述顶点的详细数据,一般单独存在一个数组中。
IndexData:顶点的索引数据,一般用于面片的描述中。
顶点法向需要单独保存的目的:在表面是硬表面(即有一条折线)时,各个面的平均方向不一定是顶点法向(即一个顶点可能存在多个法向),因此需要单独保存。如下图,左图为各个面平均方向得出的法向,右图为正常情况下顶点的法向。这样能有效防止渲染过程中对硬表面的渲染过于平滑。

材质系统:在现代游戏引擎中,物体的物理材质和渲染材质一般是分开的
纹理:是材质的重要表达方式,表示表面哪些部分有哪些特性。
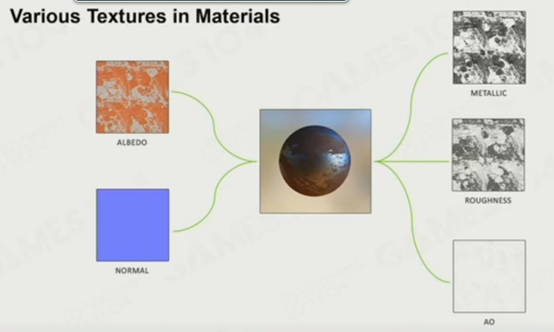
Shader:着色器,属于源码,但是在游戏引擎中会当做数据进行处理。表示物体实际的绘制方式。
渲染过程:物体投影变换(投影到屏幕坐标系)-->加载Mesh,texture,Shader
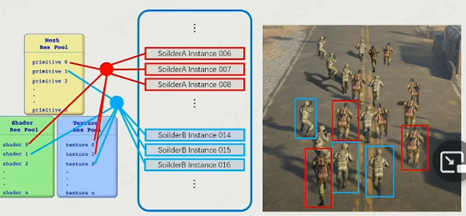
Submesh:在现代游戏引擎中,一个mesh会根据各部分材质的不同会被切分为不同的子mesh,每个mesh都有各自的shader,material等,但顶点相关的会被存储在父节点的buffer中。下图展示了它们的关系。

Resource Pool:全部的资源会被存在一个Pool中,方便一个Resource的共用。
实例化(Instance):数据实例的内容可以用Resource Pool里的共用部分。
材质排序(Sort by Material):把整个场景的物体根据材质进行排序,绘制时逐材质进行绘制,这样GPU读取材质的次数会减少,从而能加快绘制速度。
GPU Batch Rendering:一次把所有相同材质的东西都绘制出来。
包围盒:一个包围物体本身的空间,是物体本身模型的一种简化,分为很多种。在碰撞检测和渲染等方面有很大的应用。
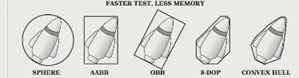
可见性裁剪(Visibility Culling):屏幕外的物体可以简化绘制,屏幕内的物体精细绘制。
PVS算法(Potential Visibility Set):先用BSP树将空间分为很多小方块,在每个空间判断最多能看到几个其它空间,则在这个空间时只渲染这几个空间的内容。(但运算时间很长,现代基本不用这个方法。)

将玩家所在的游戏世界分为不同的zone,通过PVS算法可以对zone的资源加载优化。
现在的Culling一般都由GPU完成。
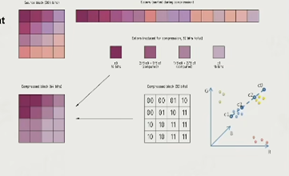
Texture Compression(纹理压缩):将图片切成小块进行压缩(Block Compression)的技术。
可以在切分成小块后,取小块中色值最大和最小的两个部分,其余部分的描述方式变为在这个色值区间上的比例。PC上常用的块压缩算法有DXTC和BC7,这两种算法都能在CPU上实时压缩,且压缩解压缩效率很高。手机上则采用ETC/PVPTC或ASTC算法,分块不会是严格的4*4,不能在运行中压缩。
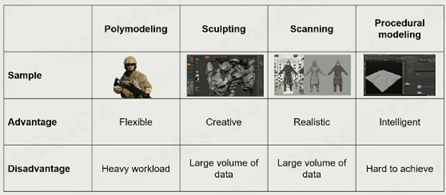
建模工具:3D扫描,雕刻(zBrush),几何建模(3Dmax),Procedural Modeling(自动生成网格模型,如Houdini等)
现代游戏引擎pipeline:Cluster-Based Mesh Pipeline
核心思想:当面对一个非常精细模型时,会将它分为很多小的大小一致的面片集合,从而方便GPU的渲染处理。
这种管线可以生成无数的细节,并能根据精度改变显示。
总结:
- 游戏引擎绘制系统深度依赖于现代硬件设计。
- 游戏引擎中的绘制部分核心要解决的是mesh,材质,模型等之间的关系。
- 绘制的时候尽可能减少绘制的数据量。
- 如今越来越多的绘制运算被转移到了GPU。














 2019
2019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









