







**
rcnn
**
1.RCNN算法流程可分为4个步骤(前向传播过程)
(1)一张图像生成1K~2K个候选区域(使用Selective Search方法)
(2)对每个候选区域,使用深度网络提取特征
(3)特征送入每一类的SVM分类器,判别是否属于该类
(4)使用回归器精细修正候选框位置

(1).候选区域的生成
利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
(2).对每个候选区域,使用深度网络提取特征
将2000候选区域缩放到227x227 pixel,接着将候选区域输入事先训练好的AlexNet CNN网络获取4096维的特征得到2000×4096维矩阵。

(3).特征送入每一类的SVM分类器,判定类
别将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。


(4).使用回归器精细修正候选框位置
对MS处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
如图,黄色框口P表示建议框Region Proposal,绿色窗口G表示实际框Ground Truth,红色窗口G_hat表示Region Proposal:进行回归后的预测窗口,可以用最小二乘法解决的线性回归问题。


2.数据训练
rcnn训练数据需要三个步骤单独训练,训练步骤为
(1) CNN fine-tuning,
(2) detector SVM training
(3)bounding-box regressor training
3.为什么需要svm
fine-tuning时用的正样本是IOU>0.5的候选框,和groundtruth有偏差,对训练结果会有影响,而训练svm用的正样本就是groundtruth。
4.为什么用svm不用softmax
svm的性能比softmax好,主要由于下面几个原因,微调中使用的正例的定义不强调精确定位,并且 softmax 分类器是在随机采样的负例上训练的,而svm训练用的是hard negatives。
**
faster rcnn
**
1.Fast R-CNN算法流程可分为3个步骤
(1)一张图像生成1K2K个候选区域(使用Selective Search方法)
(2)将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
(3)将每个特征矩阵通过R0Ipoo1ing层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果

损失公式(详细介绍参考论文)
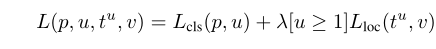
2.sppnet为什么不能更新金字塔前的卷积层
根本原因是当每个训练样本(即 RoI)来自不同的图像时,通过 SPP 层的反向传播效率非常低,这正是 R-CNN 和 SPPnet 网络的训练方式。效率低下的原因是每个 RoI 可能有一个非常大的感受野,通常跨越整个输入图像。由于前向传递必须处理整个感受野,因此训练输入很大(通常是整个图像)。
3.解决的问题
1、训练分多步。R-CNN的训练先要fine tuning一个预训练的网络,然后针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归,另外region proposal也要单独用selective search的方式获得,步骤比较繁琐。
2、时间和内存消耗比较大。在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间消耗还是比较大的。
3、测试的时候也比较慢,每张图片的每个region proposal都要做卷积,重复操作太多。
4.改进的地方
1、卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高,因此产生重复计算。
2、用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把region proposal作为输入。
3、将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax代替原来的SVM分类器。
faster rcnn
faster rcnn = rpn+fast rcnn
1.Faster R-CNN算法流程可分为3个步骤
(1)将图像输入网络得到相应的特征图
(2)使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
(3)将每个特征矩阵通过R0Ipoo1ing层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果

2.rpn的训练样本采样方式
三种尺度(面积){1282,256,512},三种比例{11,1:2,2:1},每个位置在原图上都对应有3x3=9 anchor对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cs得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩2k个候选框。
再从2k个候选框中选择样本进行训练,每个小批量都来自包含许多正例和负例锚点的单个图像。可以优化所有锚点的损失函数,但这会偏向负样本,因为它们占主导地位。相反,我们在图像中随机采样 256 个锚点来计算小批量的损失函数,其中采样的正负锚点的比率高达 1:1。如果图像中的正样本少于 128 个,我们用负样本填充小批量。
总结为:
1)首先是选择了大约20000个候选框。
2)去除掉其中与边缘相交的,选择其中大约6000个。
3)通过NMS抑制选择其中大约2000个。
4)最后在2000个中选择其中256个用于训练。在测试时直接就选择其中300个送入Fast RCNN。
3.rpn损失
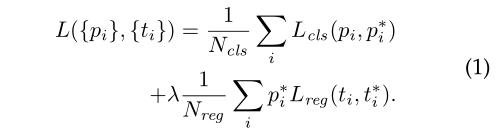
4.论文训练模型方式(4-step)
(1)利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数;
(2)固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框去训练Fast RCNN网络参数。
(3)固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数。
(4)同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
自己训练可直接采用RPN LoSs±Fast R-CNN Loss的联合训练方法(pytorch官方训练方式)
总框架
















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









