






B战学习视频:使用MarianMT进行文本数据增强
pip install transformers==4.1.1 sentencepiece=0.1.94
pip install mosestokenizer=1.1.0
from transformers import MarianMTModel,MarianTokenizer
初始化模型,将英语翻译成罗曼语,
target_model_name='Helsinki-NLP/opus-mt-en-ROMANCE'
target_tokenizer=MarianTokenizer.from_pretrained(target_model_name)
target_model=MarianMTModel.from_pretrained(target_model_name)
初始化将法语翻译成英语的模型
en_model_name='Helsinki-NLP/opus-mt-ROMANCE-en'
en_tokenizer=MarianTokenizer.from_pretrained(en_model_name)
en_model=MarianMTModel.from_pretrained(en_model_name)
书写辅助函数,来翻译给定机器翻译模型
def translate(texts,model,tokenizer,language='fr')
template=lambda text:f"{text}" if language == "en" else f">>{language}<<{text}"
src_texts=[template(text) for text in texts]
encoded=tokenizer.prepare_seq2seq_batch(src_texts)
translated =model.generate(**encoded)
translated_texts=tokenizer.batch_decode(translated,skip_special_tokens=True)
return translated_texts
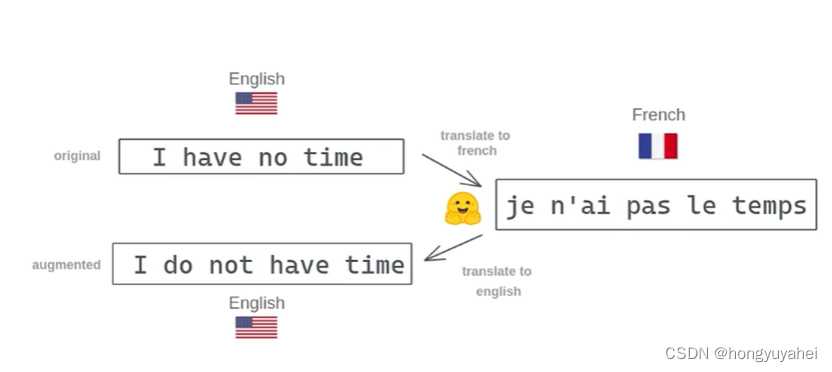
回译函数:
def back_translate(texts,source_lang="en",target_lang="fr")
fr_texts=translate(texts,target_model,target_tokenizer,language=target_lang)
back_translated_texts=translate(fr_texts,en_model,en_tokenizer,language=source_lang)
return back_translated_texts
执行数据增强(英语到西班牙语)
en_texts =['This is so cool','I hated the food','They were very helpful']
aug_text=back_translate(en_texts,source_lang="en",target_lang="es")
print(aug_texts)
["Yeah,it's so cool.","It's the food I I hate.","They were of great help."]
使用英语到法语进行扩充:
en_texts =['This is so cool','I hated the food','They were very helpful']
aug_text=back_translate(en_texts,source_lang="en",target_lang="fr")
print(aug_texts)
["It's so cool.","I hate food.","They've been very helpful."]
如下命令查看所有可使用的增强语言
target_tokenizer.supported_language_codes

















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









