







前言:
「围棋是完全信息博弈。
在完全信息博弈里,机器战胜人类是必然的,没有任何值得惊奇的地方。
“解决一个问题的效率,取决于它的知识描述的效率。” ---- Patrick Henry Winston
AlphaGo 的成功,是因为它为围棋找到了非常适合的知识描述方法。
围棋的棋盘方方正正,二元对立,天然适合用矩阵来描述棋局。」
正文
首先,围棋是一种完全信息博弈。
什么是完全信息博弈呢?完全信息博弈是一种一定可以被破解的博弈。它具有以下特征:
-
规则明确(不是连规则都不知道或者朝令夕改)
-
局面有限(棋盘不是无限大)
-
信息完全(一览无余,没有底牌、战争迷雾之类)
-
确定性(不像大富翁游戏那样掷骰子)
-
两方(不像麻将或四国大战那样多方)
-
对抗性游戏(一方所得必然是另一方所失,没有合作共赢)。
常见的棋类游戏,如围棋、中国象棋、国际象棋、五子棋、跳棋,都是这样的例子。
完全信息博弈是最简单的一类博弈,也是最适合电脑处理的。随便更改任意一个条件,都会使问题变得更难,而不适用电脑求解,人类可以轻松胜过电脑。
策梅洛定理

根据策梅洛定理(Zermelo's Theorem),完全信息博弈是一定可以被破解的,也就是说,在算力的发展下,电脑玩完全信息博弈是一定会胜过人类的。
「策梅洛定理:
在二位玩家间展开的步数有限的游戏中,如果双方拥有完全的信息(或双方每步都采用最优策略),则必有一方拥有不败策略。」
早在2007年,跳棋就已经被破解,这个游戏已经被找到了一方必不败的策略,在双方都不犯错的前提下,这个游戏只有一种结局,那就是和局。请大家想一下,当年和电脑玩跳棋的时候,如果你没有选择最简单的游戏难度(也就是没有要求电脑故意犯错),你,有赢过吗?换句话说,这个游戏其实已经死了。对于高手来说,不用下,就已经知道结局。
而其他的完全信息博弈,如围棋、象棋等,之所以还没有被破解,是因为计算机领域的终极问题----组合爆炸。
组合爆炸
策梅洛定律证明了解的存在,但是并没有直接给出解。随着算力的不断进步,围棋的破解迟早会发生,但是具体是什么时候发生,还是未知的。
为什么跳棋已经被破解了,但是围棋还没有呢?那是因为围棋太复杂了,围棋棋局的不确定性太大了......围棋的局面数目高达10的170次方,远高于国际象棋的10的46次方,而宇宙中质子的数目,也不过才10的80次方......
博弈树搜索
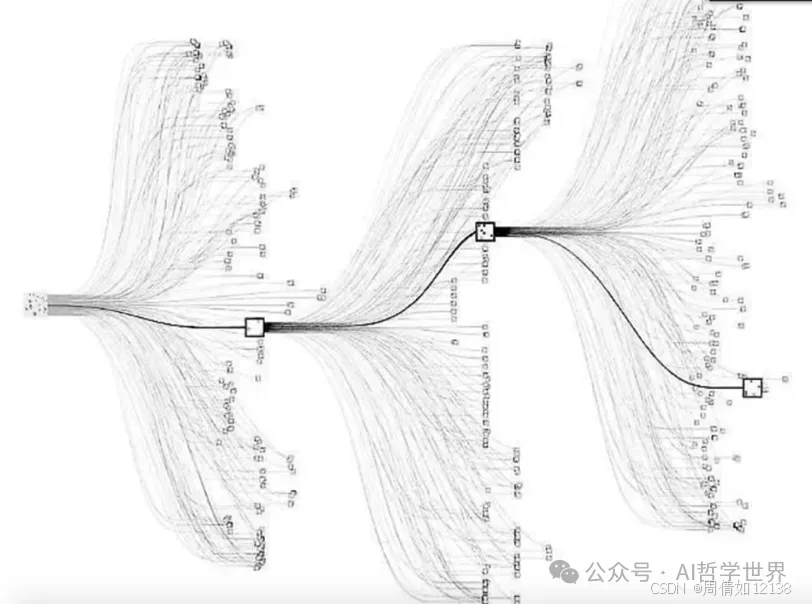
电脑玩围棋,其实用的都是同一个算法----逆向博弈树搜索。也就是说,根据围棋的结局把所有的棋局分成三类:「黑子赢」、「白子赢」、「和棋」,然后根据时间的顺序逆向倒推,直至最初的棋局,也就是那个空空荡荡的棋盘,一个子也没有,将遍历到的每个棋局分类。如果一个棋局落子之后,其后的所有棋局可能中,黑子赢的概念更大,则归类为「黑子赢」,反之亦然。极端情况下,如果一个棋局无论以后怎么走,都必然走到黑子赢的结局,则称该棋局为黑子的必胜局,反之亦然。所以电脑求解围棋,本质上就是根据现场的棋局,遍历所有可能的棋局,构建一颗围棋的博弈树,然后选择自己胜算最大的落子策略。
然而,由于前面提到的围棋棋局的不确定性太大,棋局数目(也就是博弈树的节点数)高达10的170次方,不可能遍历完。计算机科学家只能通过近似的方法,暨蒙特卡洛树搜索来得到解。
其实,在AlphaGo之前,就已经有很多围棋游戏了,它们用的都是蒙特卡洛博弈树搜索,为什么之前的游戏都没有战胜人类,而AlphaGo却可以?相比其他的围棋游戏,AlphaGo 真正的致胜招是什么呢?
知识就是力量
答案就是:AlphaGo 选择了正确的知识表达方法(即矩阵)来表达围棋的棋局。围棋的棋局,方方正正,天然就非常适合用矩阵来描述,而且黑白棋子二元对立,非常适合用二元矩阵来描述。
AI之父 Patrick Henry Winston 的著作《Aritificial Intelligence》第一章里就讲到:“解决一个问题的关键,就是为这个问题找到正确的知识表达方法。”



AlphaGo 的致胜秘诀是它为围棋的棋局选择了正确的知识表达方法,而不是深度学习。深度学习只不过是恰巧是使用矩阵来表达数据的模式识别算法而已。当AlphaGo 使用了矩阵描述围棋的棋局之后,逆向蒙特卡洛树搜索的效率突飞猛进,超过了同类的围棋类游戏,一举成名。而在资本操纵的舆论攻势下,人们都以为深度学习是AI的万能膏药,可以解决所有问题......从此以后,全世界的科研人员(依然是在资本的操纵下),都不再认真研究领域的知识表达和本体,而是将所有资源投入“大数据”,“大模型”,苦苦哀求天上能掉下免费的午餐。
真正决定问题解决效率的是知识表示,而并不是所有问题都适合用矩阵来表示,否则的话,AlphaGo 成功这么多年了,同样拥有方方正正棋盘的象棋,AI为什么还是没有战胜人类呢?
参考文献
冲虚道长给你讲博弈论:AlphaGo需要的不是恐惧,而是理解 | 袁岚峰
知乎 https://zhuanlan.zhihu.com/p/27233601

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









